干货 | 手把手带你入门微软Graph Engine

导读:出自微软亚洲研究院的Graph Engine(原名Trinity)是一个基于内存的分布式大规模图数据处理引擎,能够帮助用户高效地处理大规模图数据,且更方便地构建实时查询应用和高吞吐量的离线分析平台。自2015年发布以来,Graph Engine受到了来自学术界和工业界的广泛关注。点击【阅读原文】访问Graph Engine 的GitHub页面(https://github.com/Microsoft/GraphEngine)。
今天,我们邀请了Graph Engine的主要设计者与开发者之一,微软亚洲研究院机器学习组副研究员李亚韬为大家详解Graph Engine,并演示一些快速上手的实例。
(以下文字整理,内容略有精简)
首先,我们来回顾一下NOSQL中一种很重要的系统——键值存储器 (Key-Value stores)。Key-Value stores是一个字典形式的索引存储系统,里面所有数据都按照Key去索引,每个Key对应一个唯一值。这就像是各种语言,如Python、Java中的Dictionary或者Map。
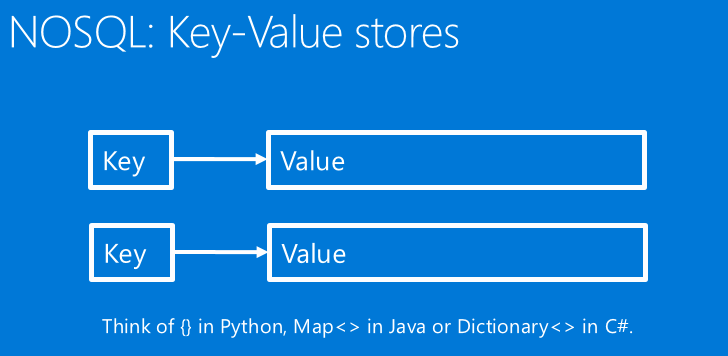
比如MemCached,就是NOSQL中一个很早出现且非常流行的键值存储器(Key-Value stores)系统。它是一个分布式、多线程的缓存系统。为什么叫缓存系统?因为它其实并不知道用户存储的数据结构是什么样的,只是把数据当成一个个blobs,像二进制的数组一样。这里的例子就是说,当给定一个Foo ID,我们利用MemCached,可以得出一个能够识别的对象(Object)。但实际上MemCached本身无法识别我们这个东西,在它那里其实就是一个二进制的数组。
这所带来的问题是,一个系统如果不知道用户存的是什么东西,那么所有的计算就必须在客户端进行。因为如果系统不知道数据的属性,那就没有办法操作里面的数据。比如我有一个很大的对象,若要更新其中的一个部分,就需要把整个对象从客户端输入,然后进行一些操作再写回去。当两个人同时写一个东西时,就可能会导致一个人的改动被另一个人的冲掉。
Redis系统比MemCached出现得晚一些,它支持几种简单的数据结构。系统中每一个Key对应的值可以是一个数据结构——列表、集合或是字典。每一个值对应着一个小的容器,并且在这个容器上,它所有的操作都保持了原子性并支持事务。
但是在实际使用的过程中,我们会发现,很多时候数据没有办法简单的用列表或字典这些简单的数据结构来表示(因为它不能嵌入)。我们的数据有时候是层次结构的(Hierarchical)的,所以我们必须用某种层次化的数据结构,例如JSON、XML等去表示。在这种时候,Redis就没有办法很好地表达这些数据结构。实际上,业界很多用法都是用JSON模型先把它序列化成一个字符串,然后再输入Redis。但这样就会把Redis又变回MemCached,因为Redis不知道里面存的是什么东西,所以所有的计算操作又回到客户端。
谈到数据建模(DataModeling),我们不妨从另外一个角度,用图数据库去解决这种问题。在图数据库里,我们存储的是实体间的关系。
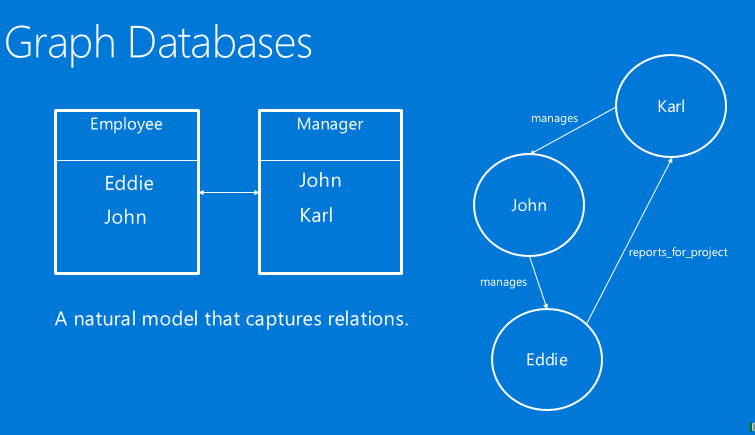
举个例子,左边是一个表,右边是和它等价的图中的关系。我们可以看到这里有三个人,有老板,也有员工。老板会管理员工,员工也会为了某个项目向老板报告,这种数据模型最核心的数据结构就是图。
图由节点和节点间的边构成。但这里的图和教科书上讲的图有点不一样,我们可以在点或者边上添加一些数据,这种图叫做“带属性图”(Property Graph),即它的点上能够存储数据,比如说一个人的年龄、名字等等。在这种数据模型下,我们可以有一些在图上的查询方法,它能够做到在SQL中很难表达的一些事情。
也正是因为这种灵活的特性,我们在实现图数据库时,会遇到一些挑战。主要的问题是在查询时,会有很多的随机存取。因为在图上查询时,很多是利用遍历实现的。虽然一个点走到另外一个点的代价不是很高,但是如果从一万个点走到它周围的两万个点,再走到周围的四万个点,这样一层一层扩散出去的话,问题就会变得越来越严重。如果把数据放在磁盘上,就会有很高的时延,因为我们没有办法很好地预测一个点的下一步会决定往哪边遍历。
为了解决这个问题,有几个主要的优化手段。一个就是不要像SQL里,同一个实体需要在不同的表里面查找,更多的是直接把一个点上所有相关的信息组织在一起。所以只需查找一次,就能索引到其中的一个实体。另一个方法是,我们要尽可能多的把数据放在内存里,这样随机存取的性能会提高很多。
我们在做图遍历时,如果是单机系统,利用广度优先算法BFS或者深度优先算法DFS都可以。但如果是分布式系统,由于不能跨机器执行单机算法,所以我们需要用消息传递(Message passing)实现图遍历的功能。
图数据模型下对应的查询语言和传统的SQL查询语言会有一些不一样。传统上,如果在多个表里查询数据,我们会用联结操作(join operator)把数据连在一起。但是在图查询语言里,我们更多的是直接从一个点遍历到它的邻居,再从中筛选出符合条件的数据,做操作。
此外,在图查询语言里还可以使用一些特殊的操作符。比如,给定两个点,然后可以查询数据库,找两点之间的最短距离。我们还可以做一些特殊的便利操作,比如从一个点走出去,走过一个三角形,又回到这个点,这样就可以找到这个点周围的所有三角形。以及,告诉系统一直沿着某个条件走下去,就好像正则表达式一样,直到遇到一个停止条件才停下来,我们把这个叫做“闭包”操作。

接下来我们看一个“闭包”的具体例子。假设Karl是部门的大老板,他会管理一些中层干部,这些中层干部会管理一些基层员工;而基层员工可能会在做一些项目,他们需要直接向Karl汇报。现在在Karl管理的部门中,要找到所有向Kark直接汇报的人,应该怎么找?
这里的问题是,我们不能确定管理的链条有多长。因为可能是A管着B、B管着C、C管着D,D又向H报告。如果用SQL,就需要把所有的两跳、三跳、四跳以及等等的操作都做一遍,最后再把结果综合。但是在图里面,由于有“闭包”操作,所以我们可以从Karl这个点出发,沿着管理这条路线走,这样走下去一定是报告和管理的关系,而终止条件是找到一个点,它不再管理其他人,或者是它连回了一条边,比如Karl这条报告的边。
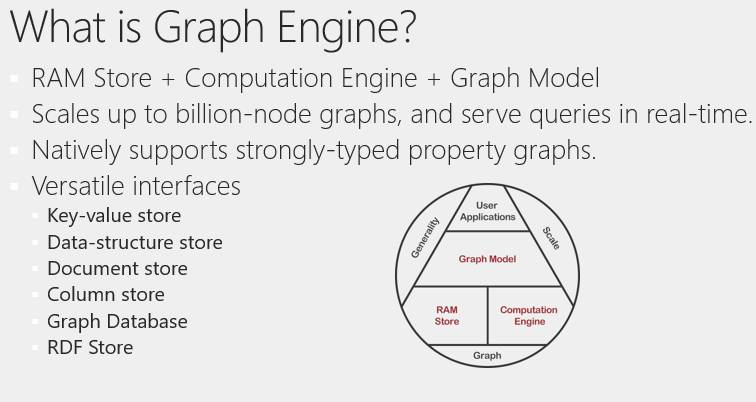
刚才介绍了内存中系统以及Graph model怎么为数据建模,并且简单介绍了图数据库上的查询语句以及它是怎么做计算的。将这些内容结合,我们做了一个系统,就是Graph Engine,用于处理以上工作。
这里有一个系统结构示意图,中间这个三角形是系统的基础架构。最底层是一个内存中的键值存储器(Key-Value stores),以及计算引擎。计算引擎在不同机器之间会传递消息,并且一个机器可以调用另一个机器上某一类消息的响应代码(Handler)。在这种架构上构建图模型层(Graph Model),用户就可以利用图模型层的抽象,做自己的应用。所以Graph Engine系统不仅可以进行图数据的处理,由于它是分布式的,所以存储管理(Memory management)做的也相对较好,可扩展性(Scalability)也比较好。此外它还具有一定的通用性,不仅是图上的计算,还可以用于其他的应用。比如可以简单的把它用作键值存储器,简单的定义数据结构,当成Redis去用。
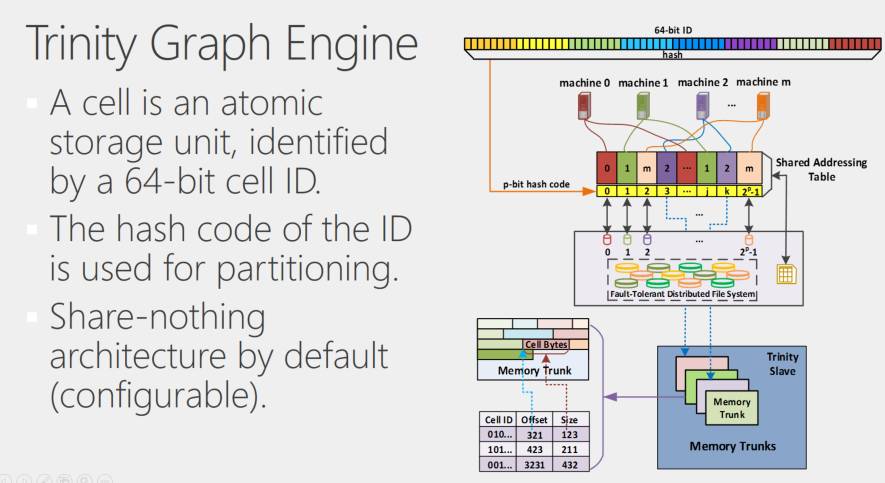
在系统最底层, RAM store本质上也是一个键值存储器,使用64位整数做Key,Value是任意的一个值。每个机器上有一个本地的RAM Store,不同的机器之间,给定一个Key之后,通过对这个Key进行Hash,可以判断当前的实体,即Cell ID对应的Value是在哪个机器上。这是一种叫Share-nothing的配置方法。当然这是一个可配置的(Configurable)方案,但是默认情况下,它是一个Share-nothing的结构。
拿到一个Key,首先判断它在哪个机器上,如果我们要访问对象,就把这个消息发到那个机器上,机器访问自己的本地内存数据。一个内存存储(Memory store)可以分成很多不同的块(Memory Trunk),里面有一套内存管理系统,所以我们最终可以定位到每一个对象所对应的内存区域。
讲到这儿大家可能会有一个疑问。刚才说,如果把数据按照Blob二进制存的话会有些限制,可现在不还是把数据扔到一个内存块里面,存储为byte数组么?那接下来就讲讲我们是怎么处理这个问题的。
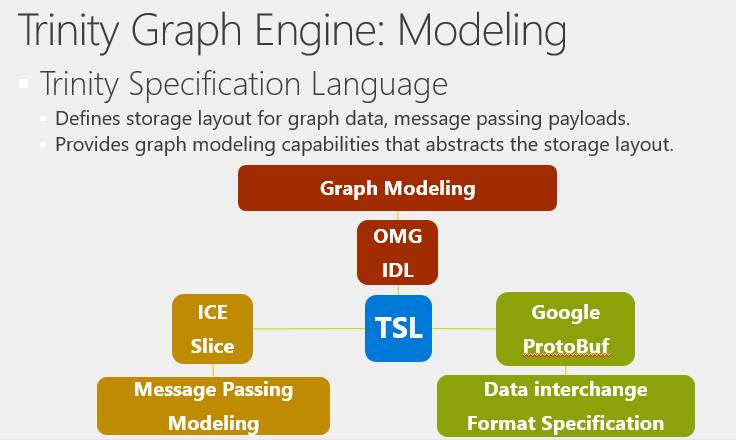
在Graph Engine系统中,我们使用Trinity Specification Language语言,即TSL,来完成以下三种功能。第一个,做数据建模,虽然存储时存成的是一个Blob,但实际上我们有它的数据模式(Schema),并且可以由用户指定,而不是用一些简单的自带数据结构。第二,在做Message passing时,如果期望得到某一种格式的回复,我们可以用TSL来定义消息传递格式。第三,系统和其他外部系统之间需要交互,比如要从C#里传递一个东西,放到Python里,我们也可以通过TSL来进行数据交换,我们可以提供一种标准,作为数据的中间格式。

这里有两个TSL的例子,可以看到TSL和C族语言非常像。首先,看一下图模型的定义,我们用Cell关键字,指明定义的结构体是一种实体——实际上一个cell就是一个Key对应的一个Value,它有自己的内部结构。比如Movie里有电影名字,主演等。同样的,根据演员名字,我们可以得出这个人演了哪些电影。
我们可以在实体的 Cell Type以及它的Filed上加一些属性,用于和系统的其他模块进行交互。在Message Passing里,实际上是一个类似的结构,我们可以定义一个结构,一个cell也可以包含一个结构,不过这个结构体还可以额外用来做Message Passing。
定义结构后,接下来,我们定义了一个通信协议,协议说,发送消息是同步消息,消息发出后,我期待对方处理完返回的还是一个My Message。
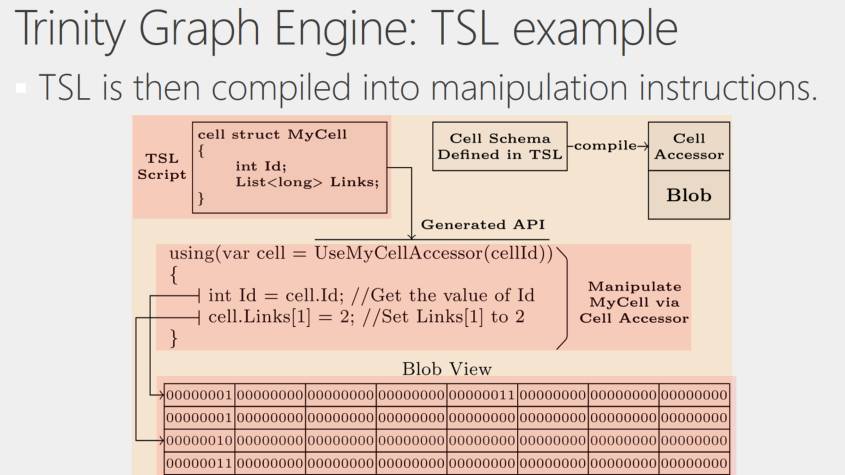
定义好TSL后,会有一个TSL编译器,根据用户定义的Cell Struct以及其他定义结构,生成一些对Cell操作的存取器(Accessor)。比如这里的UseMyCellAccesor,这个API不是系统本来提供的,而是Graph Engine的程序集(Assembly)加上用户的TSL生成出的程序集然后再综合生成的一个API。
这个API的使用方法和Struct类似,可以直接操作里面的ID,也可以认为里面Links是个List,直接分配给List一些值。但实际上我们并没有分配一个运行时的List,我们会把操作翻译成对当前Cell对应的内存的操作。也就是说键值存储器负责最基本的给出内存空间。然后生成的代码负责处理用户如何分配数据,系统应该如何理解数据。
这样一来,我们可以用像Struct一样简单的接口,利用Accessor,操作一个虚拟的概念。我们只提供了对操作的描述,具体的执行则是翻译成了低层对内存直接的操作。这样既能保证用户接口的友好性,工作效率也可以做得非常高。
另外,这也是Graph Engine与其他系统一个很显著的区别,系统不仅可以对里面所存的实体进行类型定义,也可以有它自己的结构,甚至这个结构是分层的,因为一个Cell也可以包含其他的Struct。另一方面,由于拥有Accessor这套系统,因此,它可以直接在RAM Store里就地操作数据,从而相应地提高效率。
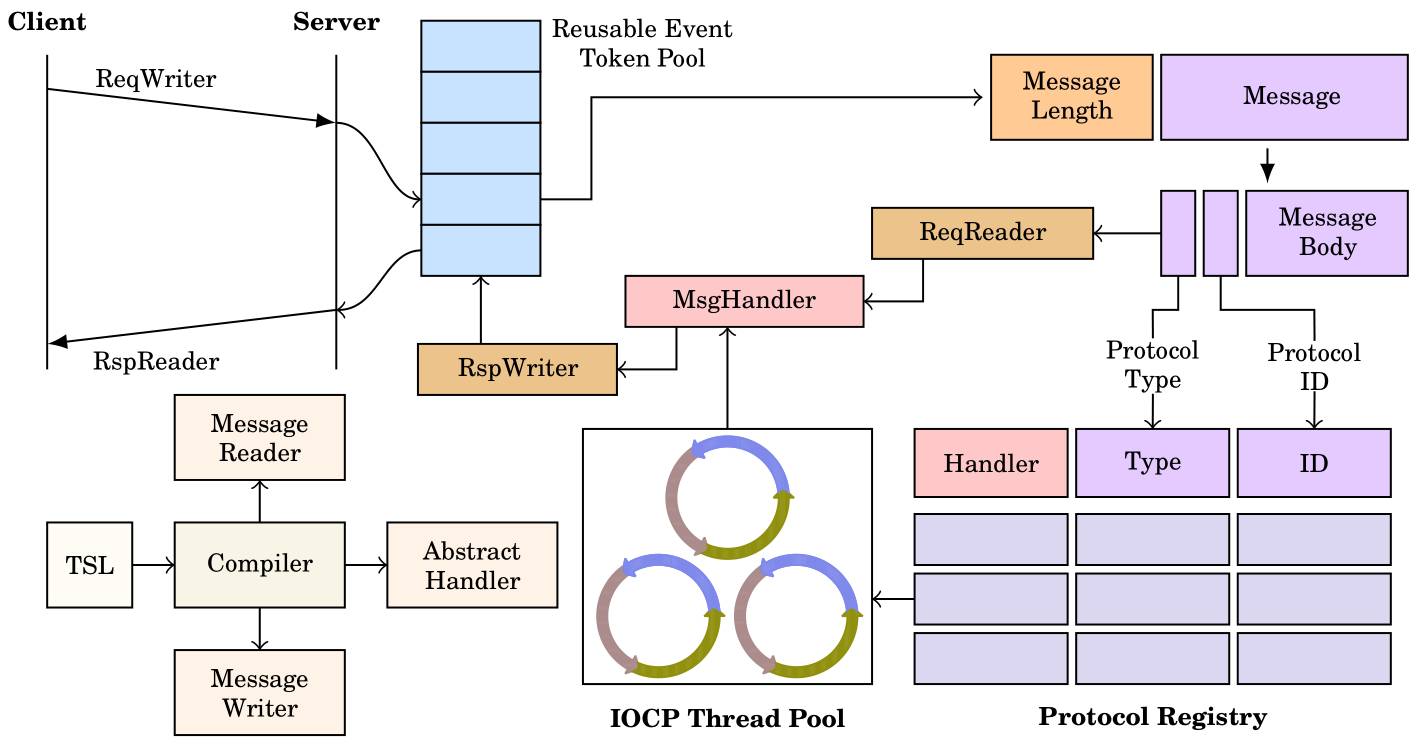
与此类似的,在用TSL做Message Passing过程中,我们从上图的左上角看起,客户端先初始化了一个请求服务器。在客户端,Graph Engine只负责分配缓冲区(Buffer),然后生成的API就会有Data Accsesor告诉我们如何往缓冲中填充数据,甚至可以直接把RAM Store中的一些数据取出,再通过Accesor传给服务器。在服务器这边,我们有一个IOCP的线程池(Thread Pool),或者在Linux系统中,我们用的是一个事件库。
并且我们还定义了协议(Protocol),每一个协议会对应一个Handler,代表服务器收到该协议的消息后应该做什么动作。我们把这个东西存成一个地址向量,在客户端来了一个请求后,系统通过向量跳转到一个Handler里去执行。执行完成后,根据消息是同步还是异步,可以做一个选择。如果同步,客户端会进行block,直到服务器处理完这个消息,并返回处理结果。
我们注意到,客户端发送的请求ReqWriter以及服务器返回的RspReader,其实都是由TSL编译器生成的。不仅如此,在一个消息到达服务器之后,它有一个调度(Dispatch)的过程,需要把消息翻译成一种数据结构,这里我们可以直接用Data Accessor去读取缓冲器中的内容。所有的辅助过程,包括Handler的抽象接口,都是由TSL Compiler生成的。我们设计系统的目标就是让消息传递(Remote Message Passing)变得尽量简单,就像在本地写GUI程序一样。
关于系统底层的实现细节就先介绍到这里。下面来看一个具体的例子——做一个Twitter的“爬虫”。Twitter本身提供了一组Streaming API,订阅后会不停地给你推送最新的消息。
我们可以在Graph Engine上加一个Message Handler,每次Twitter来了一条新的消息,我们就向这个消息协议转发,这个协议(Protocol)可以是同步、异步,或者是内部的协议,也可以是HTTP的协议,所以和其他语言非常好交互。

我们可以用这个做什么事情呢?当一条推文来了之后,我们可以把它放到Graph Engine里。在消息处理器中找到这条推文应该存的地方,比如,哪个用户发的,提到了哪些人等等。在做这件事情的同时,实体间的关系就建立起来了,因为一个用户发了一个推文,会有一个关系连到一条边,如果推文里提到了其他人,那么系统就不仅是存下了这条信息,还可以把所有关系都实时建立起来。
不仅如此,在不停更新数据的同时,我们还可以在上面跑一些计算,记在数据库里,并进行一些查询。
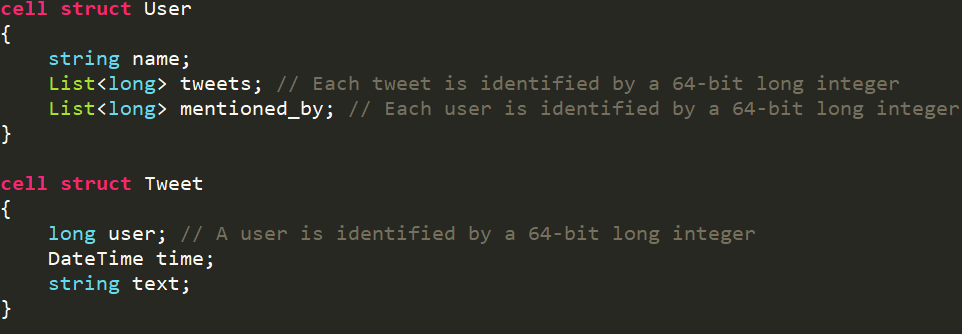
这里是一个简化的Twitter 图模型,里面有两种实体,一种是用户、一种是推文,我们用边把它们连起来,发现用户可能被其他的推文提到过。与此同时,关于推文的定义,它里面有一个单独的边,指向发推文的用户,并且把文本内容作为一个属性,附在这个点上。
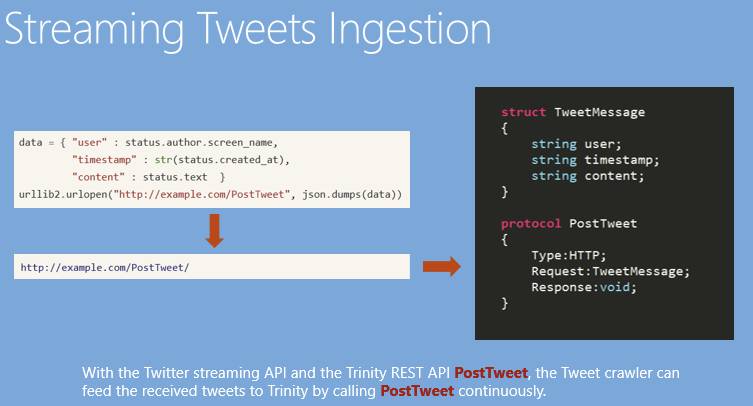
比如,我写好了一个Python的Twitter“爬虫“,调用了官方接口,就可以去监测Twitter中的事件,那么怎么交互呢?在Graph Engine里面定义一个协议(Protocol),标出期望的请求是一个Tweet Message,这里面就包含了用户、时间戳、文本内容。因为这是一个事件定义,文本内容里可能是它发出的一个推文。在指定协议为HTTP后,Graph Engine启动时候就会监测一个HTTP的协议,然后我们就可以在Python里直接把数据传送到Graph Engine。
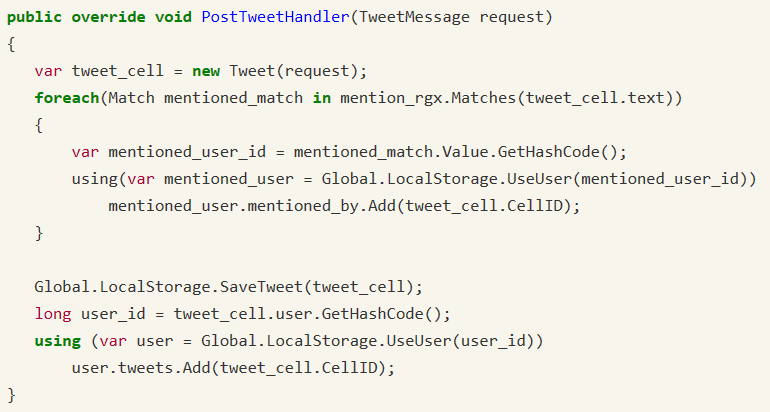
上图可以看到Post Tweet Handler的具体实现。首先从Python方来了一个请求,我们收到了一个推文消息,然后就可以实时在Handler里用正则表达式看有没有提到用户名的部分。如果有,就抽取出来,变成User ID,然后填充相应的关系。以及在此之后,我们会把当前推文存到系统里面。因为Handler不是单线程的调用,系统有一个thread Pool,所以这样的操作可以在一个Handler里实时完成。
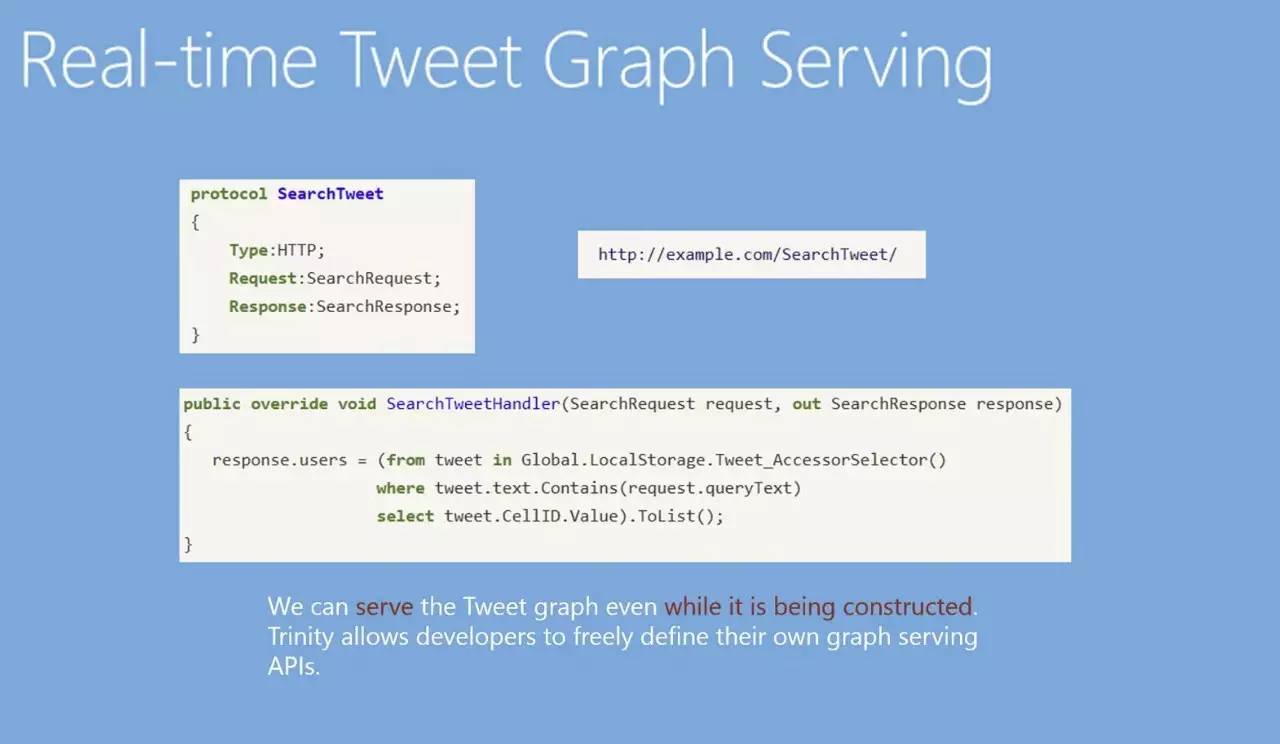
更进一步,在不停的接收(Ingest)数据的同时,还可以定义另外一个协议。现在如果要做全文索引,就可以看到定义了协议后域名下就会多出一个SearchTweet的地址,如果用一个Python代码去访问这个地址,就会触发SearchTweetHandler。这里可以使用LINQ语法,localstorage代表要用自己机器上的RAM Store。后面的Selector是说一但使用Tweet_AccessorSelector,就会把所有推文全部选出来,再之后就可以用“where”做过滤(filtering)。比如,文本里有请求的查询内容,满足条件我们就做一个投影(projection),取出Cell ID,然后我们就拿到了所有符合搜索的推文。
那么问题也来了。Schema是用户自定义的,这里可能包含任何东西,在这种情况下,如何设计一个标准的图模型层?为此,我们采取了一个方案,就是把整个系统做成一个模块化系统(Module System),每一个模块可以提供一个泛型算法(Generic Algorithms),它不和某个具体数据绑定,而是根据某种元规则执行算法,类似C++里面模板库做的事情。
只要泛型算法对于一个数据的观点、看法和用户对于数据的看法一致,那么就可以说用户数据的schema和某个泛型算法是兼容的,进而用户就可以实现一个通用的图模型来完成一些他不方便自己实现的功能。
具体来讲,回到刚才的Tweet Graph上,我们有用户和推文两种实体。我们的目标是要把查询语言,就是LIKQ,应用到Tweet Graph,在Tweet Graph上实现图的查询。问题是现在的Schema里只有List<long>,系统不可能见到List<long>就认为它是一个边,然后去遍历,因为这个Long可能还有别的意思,这样是不现实的。
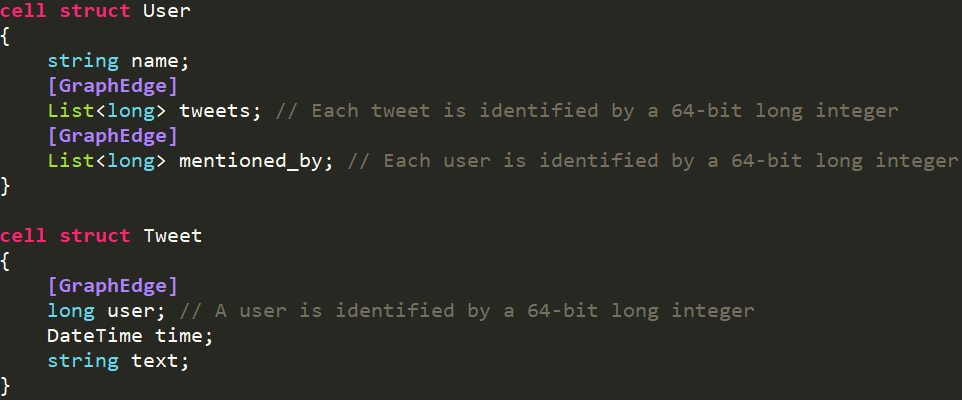
为了解决这个不匹配问题,我们可以加一些属性。这里的属性是TSL里面的,和C#里是不一样的,可以理解成是一个字符串,我们把字符串的标签(tag)打在了一个实体或者field上。这里打的标签叫做“ GraphEdge”,这样就指定了,它是图里面的边。这就回到了刚才所讨论的,数据和泛型算法对于一个属性有没有统一的认识。比如,如果查询语言觉得GraphEdge是边的意思,那么它就会采取一个方案。如果是一个算法的模块调用一个具体的名字,如遍历判断当前是不是一个用户。如果是用户就从Tweets mentioned_by走过去,那这样就不是泛型算法,因为它引用(reference)一个具体的数据。
为了避免这种情况,我们允许泛型算法直接通过属性,找到一个实体中所有符合属性的部分。它可以请求系统,去当前的实体里寻找所有有GraphEdge标志的部分,并且目标是想从这里面提取出长整型。所以不管你的Graph Engine是List<long>,还是单独的Long,甚至是一个Int,更有甚者,这里存的是个String,都可以通过我们系统的Graph Model中间层,然后尽可能的枚举(Enumerate)出长整型来,使得用户数据和系统的泛型算法间可以联系在一起。
接下来我们看一下具体的图查询语言,即LIKQ 。LIKQ是一个直接可以嵌入编程语言的查询语言,它和LINQ很像,都有一个很流畅的语法,可以直接写在编程语言里。
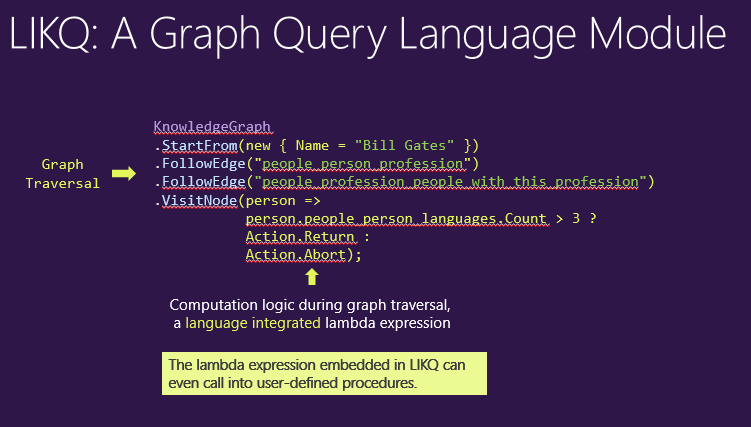
这里的例子是一个知识图谱,StartFrom这个点,指定一个查询条件,名字叫“比尔盖茨”,从这个点FollowEdge,就说从人这个点走到他的职业,然后再从FollowEdge走到people_profession_people_with_this_profession,就找到了和他相同职业的所有人。
我们不仅可以简单从每条边走出去,同时可以在一个点上时时的添加一些查询条件,方法是给这个点传入一个Lambda表达式,每当遍历的框架遇到这个点,比如走到第三跳时,就会动态执行这个Lambda表达式。
比如这里的例子是找和比尔盖茨相同职业的,会说三种以上语言的人。如果找到了,系统就保存当前路径(Path),否则就终止当前的搜索。
Lambda表达式具有非常灵活的查询(Query)特性,不仅可以调用Count>3,用户甚至可以预先把自己的一些功能注册到LIKQ模块里,只要服务器配置正确且加载了程序集(assembly),客户端就可以直接调用这个接口,调用服务器上预先存好的逻辑,而不用把整个逻辑全部写到Query里面。

LIKQ语言是一种线性遍历语言,所有的查询动作都是图的遍历(Graph Traversal)。比如Tweet Graph中,指定从Graph Engine出发(即Twitter上我们的帐号),从mentioned_by找到所有提到我们的人,不做任何过滤,一旦到达那个点之后,就执行下一跳,走的边是用户。也就是说从Graph Engine mentioned_by出发,找到了一个用户,即有一个用户提到了我们,走到这个用户后继续往前走,找到他们所发的那些推文。
这样一来,一旦到达某个推文之后,不加任何限制条件的时候系统会Action.Return。也就是说,由于它是一个线性的查询语言,因此每个查询表达式对应在图遍历中的一条路径上所有的限制条件,即它的限制条件都是从Graph Engine出发然后到一个用户再到一个推文。所以它只是限定了跳数,以及每一步从什么边跳出去。到达推文之后,它会无条件的把当前路径当成结果的一部分返回,然后做一些投影,把推文里的文本选择出来。这就是LIKQ图数据查询语言的一些简单例子。
看完这篇文章有没有收获很大?还想了解更多相关问题么?快来下方评论区提问吧!
你也许还想看:
感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




