【11分钟训练完ImageNet】DNN训练再破纪录,1024 CPU Caffe开源
点击上方“公众号”可以订阅哦!
文章来源:新智元 编译于:arXiv.org 编译:费欣欣 编辑:闻菲
【导读】此前,伯克利、TACC和UC戴维斯的研究人员使用新算法,在24分钟内训练完AlexNet,1小时训练完ResNet,创下了纪录。现在,他们继续推进,使用1024个CPU,在11分钟内训练完AlexNet,48分钟训练完ResNet-50。研究人员表示,源代码不久后将在Intel Caffe发布。
先来看论文摘要:

自创建以来,ImageNet-1k基准测试集被用于确定各种深度神经网络(DNN)模型分类的精度,作为基准发挥了重要的作用。近年来,它也成为评估不同的DNN训练方法的主要标准。
使用单块NVIDIA M40 GPU,在ImageNet-1k训练ResNet-50(90-epoch)需要14天的时间。训练总共需要10^18次单精度运算。另一方面,目前世界上最快的超级计算机,每秒可以完成2*10^17次单精度运算。如果能够充分利用超级计算机训练DNN,我们应该能够在5秒内训练完ResNet-50(ImageNet-1k,90-epoch)。
为了弥补性能的差距,一些研究人员已经把工作重点放在探索如何有效利用大规模并行处理器训练深度神经网络上面。大多数扩展ImageNet训练的成功方法,都使用了同步随机梯度下降(SGD)。但是,为了扩展同步SGD,必须增加每次迭代中使用的批量的大小。
因此,对许多研究人员而言,扩展DNN训练,实际上就成了开发方法,确保在不降低精度的前提下,增加固定epoch数据并行同步SGD中的批量大小。
过去的两年里,我们已经看到批量大小以及成功使用的处理器数量,从1K批次/128个处理器,增加到8K批次/256个处理器。最近发表的LARS算法将一些DNN模型的批量进一步增加到了32K。继这项工作之后,我们希望弄清LARS是否可以用来进一步扩大DNN训练中有效使用的处理器的数量,从而进一步缩短训练的总时间。
在本文中,我们介绍了这次调查的结果:使用LARS,我们能够在11分钟内有效利用1024个CPU训练完AlexNe(ImageNet,100-epoch),并在48分钟内训练完ResNet-50(ImageNet,90-epoch),批量大小为32K。
此外,当我们将批量增加到20K以上时,我们的准确性远远高于Facebook同等批量大小的准确率。如果需要,可以联系我们提供源代码。代码不久后将在Intel Caffe发布。
Facebook 256颗GPU,1小时训练完ImageNet
此前新智元报道过, Facebook的人工智能实验室(FAIR)与应用机器学习团队(AML)合作,提出了一种新的方法,大幅加速机器视觉任务的模型训练,用1小时训练完了ImageNet。

为了克服minibatch过大的问题,Facebook团队使用了一个简单的、可泛化的线性缩放规则调整学习率(learning rate)。为了成功应用这一规则,他们在训练中增加了一个预热阶段(warm-up phase)——随着时间的推移,逐渐提高学习率和批量大小,从而帮助保持较小的批次的准确性。在训练开始时使用较低的学习率,克服了早期的优化困难。重要的是,这种方法不仅符合基线验证误差,还产生与了比较小的minibatch基准线匹配的训练误差曲线。
作者在论文中写道,他们提出的这种简单通用的技术,能够将分布式同步 SDG minibatch 大小最多扩展到 8k 张图像,同时保持 minibatch 训练前 Top-1 位的错误率不变。
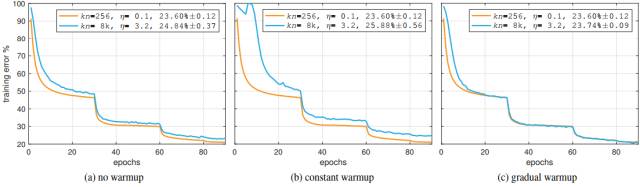
用这种方法,他们能够为一个小批量为 8192 张的图像,保持小批量大小 256 图像大致相同的错误率。
“对于所有大小的 minibath,我们将学习率设置为 minibatch 的线性函数,并对前几个训练时期(epoch)应用一个简单的预热(warm-up)。所有其他超参数保持固定。使用这种简单的方法,我们的模型精度对于 minibatch 尺寸是不变的。这项技术使我们可以在线性拓展 minibatch 大小的情况下,以高达 90% 的 efficiency 减少训练时间,在 1 小时内在 256 颗 GPU 上训练出了精确的 ResNet-50 模型,minibatch 大小为 8k。”
快速训练视觉模型应用意义重大,这项工作出来以后引发了一个小小的轰动——不仅仅是因为论文作者包括贾扬清和何恺明,更是因为使用了256颗GPU(32台英伟达DGX-1工作站),硬件价格高达410万美元,令人咋舌。
24分钟训练完ImageNet,硬件仅需120万美元
但很快,Facebook 1 小时训练完ImageNet的记录就被刷新。伯克利、TACC和UC戴维斯的研究人员使用新的算法,报告称在24分钟内训练完了ImageNet(AlexNet,100-epoch)。

伯克利、TACC和UC戴维斯的研究人员报告称在24分钟内训练完了ImageNet。

他们将批量大小扩展到32k,使用英特尔KNL,硬件费用120万美元。
同时,研究人员表示,他们仅使用了120万美元的硬件,相比Facebook的410万美元便宜了3倍多。
虽然相比Facebook确实节省了不少,但120万美元的硬件设施还是引来不少吐槽。
正如上文介绍,Facebook的Goyal等人提出了预热策略来应对大批量难以优化的问题。然而,伯克利、TACC和UC戴维斯的研究团队发现,预热策略也有局限。当设置AlexNet的批量大于1024或ResNet-50的批量大小大于8192时,测试精度将显着降低。
于是,他们提出了一种新的算法,LARS(Layer-wise Adaptive Rate Scaling,层自适应率缩放)。这实际上是一种新的更新学习率的规则。在训练时,每个层都有自己的权重和梯度,标准SGD算法对所有层使用相同的学习率,但伯克利、TACC、UC戴维斯的研究人员在实验中观察到,不同的层可能需要不用的学习率,这也是算法“层自适应率缩放”名称的由来。
LARS算法使他们在不损失精度的条件下,将批量大小扩展到32k。实验结果证明,LARS可以帮助ResNet-50保持高的测试精度。作者在论文中写道,“我们的ResNet-50基线的准确性略低于最先进的结果(73%对76%),因为我们没有使用数据增强。对于没有数据增强的版本,我们可以得到最先进的精度(90-epoch,73%)”。
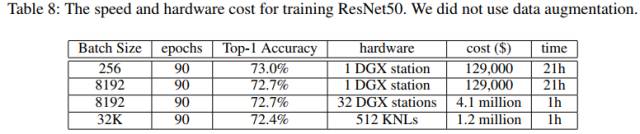
在论文最后,作者指出,我们不隶属于英特尔或NVIDIA,我们对GPU或KNL也没有任何偏好,我们只想表明可以用更少的预算(便宜3.4倍)实现相同的效果。
更进一步:11分钟训练完AlexNet,48分钟训练完ResNet-50
继这项工作之后,很自然地,伯克利、TACC和UC戴维斯的这些研究人员希望弄清,LARS算法是否可以用来进一步扩大DNN训练中有效使用的处理器的数量,从而进一步缩短训练的总时间。
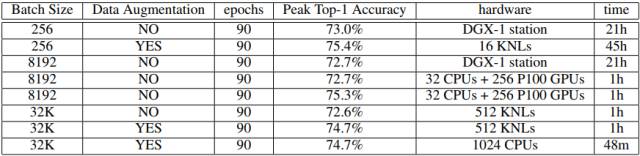
于是这一次,他们使用CPU(总共1024个Intel Skylake),11分钟训练完AlexNet(ImageNet,100-epoch),48分钟训练完ResNet-50(ImageNet,90-epoch)。512个KNL的结果,24分钟训练完AlexNet,60分钟训练完ResNet-50。
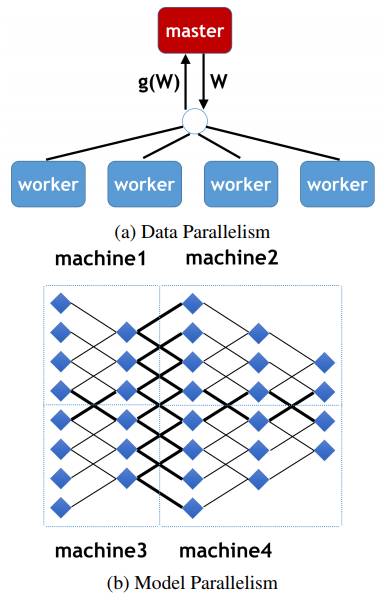
在报告中,研究人员表示,他们采用模型并行,使用LARS算法(You,Gitman和Ginsburg,2017)和预热方案(Goyal等,2017)来扩大批量大小。使用这两种方法,批量大的同步SDG可以达到与基准相同的精度。
为了扩展到AlexNet模型的批量(例如扩大到32k),他们将LRN改变为批量规范化(BN,batch normalization),在每个卷积层之后添加BN。
下图是批量大小=32K的结果,将AlexNet模型中的LRN改变为RN。11分钟完成。精度与基准相当。
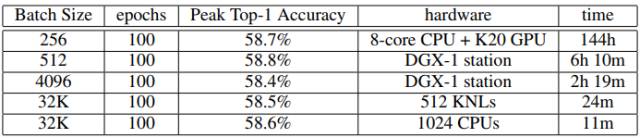
下图则是训练ResNet-50的结果,使用了数据增强,方法与Facebook(He等,2016年)一样。48分钟完成。精度与基准相当。
目标:朝5秒钟训练完ImageNet进发
对于深度学习应用,更大的数据集和更大的模型会让准确性有显着提高,但这样做的代价是需要花费更长的训练时间。 而诸如计算金融,自动驾驶,石油和天然气勘探和医学成像等许多应用,几乎肯定需要数十亿规模的训练元素和TB级的训练数据集。
因此,加速深度神经网络训练是非常有意义的研究课题。而在保持训练和泛化精度的同时,扩大批量大小,加速DNN训练,对分布式学习尤其有意义。再加上代码即将开源,其他研究人员和开发者也可以根据论文中列出的技术,享受类似的增益。
就像伯克利、TACC和UC戴维斯的研究人员在他们摘要中写的一样,目前世界上最快的超级计算机可以完成每秒2*10^17次单精度运算。如果能够充分利用超级计算机训练DNN,我们应该能够在5秒内训练完ResNet-50(ImageNet-1k,90-epoch)。
5秒内训练完ImageNet!
期待那一天的到来。
相关论文
[1] ImageNet Training by CPU: AlexNet in 11 Minutes and ResNet-50 in 48 Minutes https://arxiv.org/pdf/1709.05011v4.pdf
[2] Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour https://arxiv.org/pdf/1706.02677.pdf
[3] ImageNet Training in 24 Minutes https://www.researchgate.net/publication/319875600_ImageNet_Training_in_24_Minutes

注:投稿请电邮至124239956@qq.com ,合作 或 加入未来产业促进会请加:www13923462501 微信号或者扫描下面二维码:

文章版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将删除内容或协商版权问题!联系QQ:124239956



