利用自组织映射解决旅行推销员问题
编者按:本文原作者为Diego Vicente,他用自组织映射(SOM)方法对经典的旅行推销员问题找出了解决方法。论智已获原作者授权,以下是编译版本。
旅行推销员问题是一项有名的计算机视觉挑战,即在地图上给定一系列城市和各城市之间的距离,求解访问每一座城市一次并回到起始城市的最短回路。虽然听起来很简单,它是组合优化中的一个NP困难问题。这意味着,城市的数量越多,解决起来困难就越大,而且针对这一问题并没有通用的解决方法、所以,现在只要能找到任何次优解的方法都已经很满足了(但大多数情况下我们无法验证返回的结果是否为最优解)。
为了找出解决方法,我们可以试着在自组织映射技术上进行调整。首先来了解一下这一技术都包含什么,只有充分理解它,才能将其应用到这一问题上。
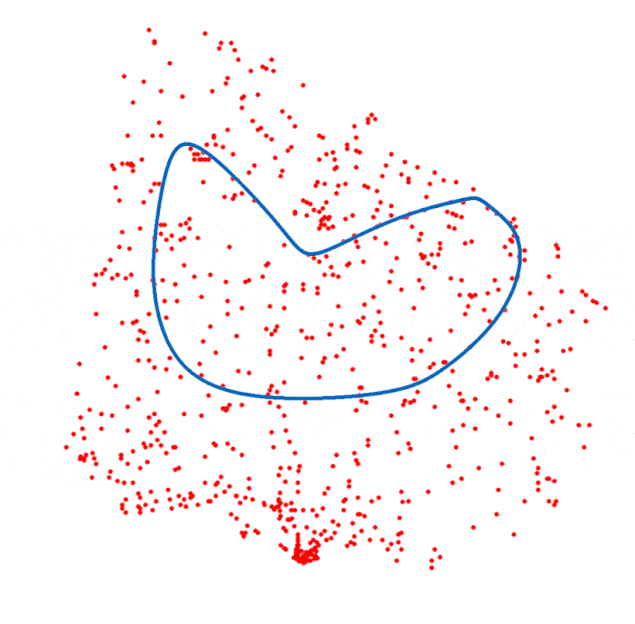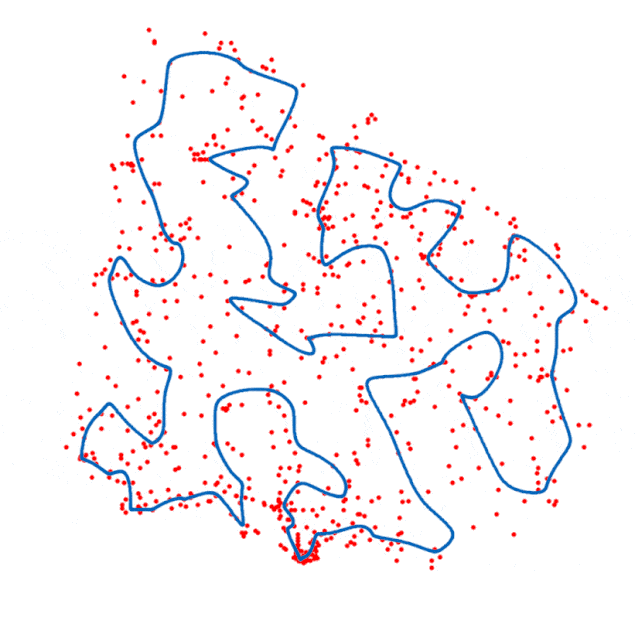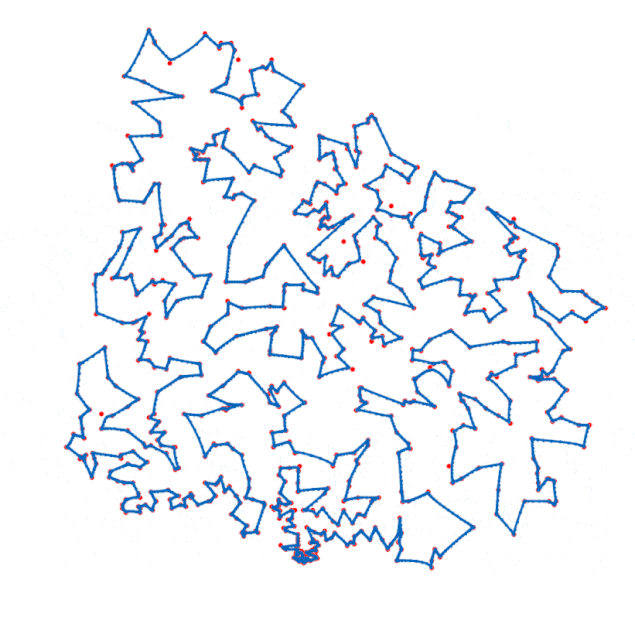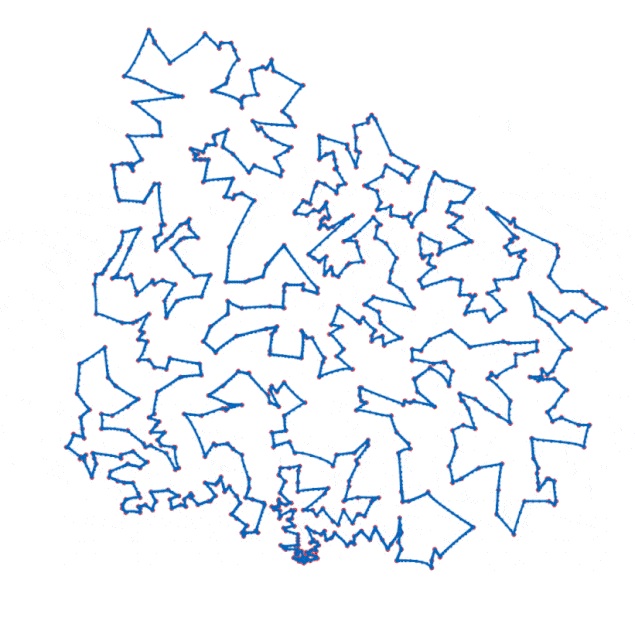
对自组织映射的一些见解
1998年,Teuvo Kohonen发表的论文中,对这一技术进行了简要却精准的描述。在论文中,他解释道,自组织映射通常是一个二维的节点网络,灵感来自神经网络。与映射密切相关的是模型的概念,即映射试图反应真实的情况。该技术的目的是用尽量少的维度表现模型,同时保持节点中相似性之间的关系。
为了捕捉这种相似性,地图上的节点在空间上的位置越接近,相似性就越高。因此,SOM是图形可视化、组织数据的好方法。为了获得这个结构,映射上应用了回归操作,修改节点的位置以便更新节点。一次从模型中选取一个元素,用于回归的表达式为:
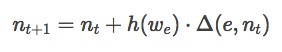
上述公示表明,将节点n中的距离添加到给定元素中,再乘以获胜神经元(winner neuron)we的近邻因素,该节点的位置就被更新。一个元素中的获胜神经元就是地图中与相近节点相似度较高的节点,通常用欧几里得距离测量(尽管可以使用不同的相似度测量)。
另一方面,近邻节点被定义为获胜神经元周围映射的卷积似的核。这样一来,我们就能更新获胜神经元和靠近元素的神经元,获得一个均衡的结果。函数通常呈高斯分布,其他实现也是如此。值得一提的是泡沫邻域,它更新了获胜者神经元半径范围内的神经元(基于离散克罗内克三角函数),这是最简单的邻域函数。
调整技术
用神经网络解决旅行推销员问题,主要任务就是理解如何修正邻域函数。如果我们将神经元排列成圆形而不是网格,每个节点只会注意到前面和后面的神经元。也就是说,内在的相似性只能在一个维度上起作用。只需要稍作修改,在邻域函数的作用下,自组织映射就会像一个弹性圆圈,不断靠近城市,同时尽量缩小总长度。
虽然这种修改是该技术最重要的部分,但是这样仍然无法工作,因为该算法几乎不会收敛。为了保证算法的收敛性,我们可以用一个学习速率α来控制算法的探索和运用。首先要实现高水平的探索,然后才能运用。为实现上述二者,我们必须在邻域函数和学习速率中添加衰减。学习速率的降低能让模型周围的神经元不过度移动。同时,对邻域函数进行衰减,对模型每个部分局部最小值的利用也就更合理。那么回归函数可以表示为:
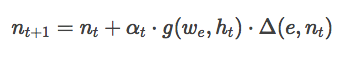
这里α是特定时间的学习速率,g是以获胜神经元为中心、具有领域分散h的高斯函数。衰减函数中分别乘以两个给定的值γ,分别代表学习速率和邻近距离。
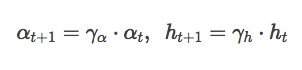
上述表达式有点像Q-Learning,并且收敛方式也类似。在无监督学习任务中,对参数进行衰减可以用于之前提到过的任务。另外,它和Teuvo Kohonen开发的学习式向量量化(Learning Vector Quantization)技术也很相似。
最后,为了获取SOM得出的路线图,只需要将某一城市与其获胜神经元相连,从任意一点开始,按获胜神经元的出现顺序依次连接城市。如果几个城市映射到同一个神经元,那是因为SOM因为缺乏与最终距离的相关性或者精度不够,而没有考虑到穿过其他这些城市的情况。
安装并测试SOM
在本次任务中,安装所述技术的方法可以在Python3中找到。它能够解析和加载任何建模为TSPLIB文件的2D实例问题,并利用回归获取最短路线。选择这种形式是因为滑铁卢大学在“全国旅行推销员问题”的实际情况中提供了这一例子的最优路线,从而能让我们测试和评估我们的方案。
在较低层级时,numpy包能让计算矢量化同时性能出色,代码也更简洁,所以用来计算。另外,pandas能轻松将文件加载到内存中;matplotib用于绘制图形。这些都能在Python发行版Anaconda中使用,或者用pip轻松安装。
我们将用滑铁卢大学提供的实例验证安装效果,这些实例来自真实国家,评估策略包括运行中的几个问题和学习指标:
寻找路线的时间;
解决方案的质量:如果我们认为“一条路线比最优路线长10%”,而实际它正好是最优路线长度的1.1倍,那么模型质量较好;
评估过程中所用的参数:
人口是实际问题中问题中城市人口的8倍;
初始学习速率为0.8,衰减速率为0.99997;
城市数量的初始邻域值,衰减速率为0.9997。
这些参数在以下情况中使用:
卡塔尔,194个城市,最优路线长度为9352;
乌拉圭,734个城市,最优路线长度为79114;
芬兰,10639个城市,最优路线长度为520527;
意大利,16862各城市,最优路线长度为557315。
如果某些变量衰减到有效阈值以下,则模型也会停止工作。运行该算法的同一方式就是测试,尽管每一实例可能有更细的参数。下表为每个评估结果,评估结果为运行5次的平均值。
| 实例 | 迭代次数 | 时间(秒) | 长度 | 质量 |
|---|---|---|---|---|
| 卡塔尔 | 14690 | 14.3 | 10233.89 | 9.4% |
| 乌拉圭 | 17351 | 23.4 | 85072.35 | 7.5% |
| 芬兰 | 37833 | 284.0 | 636580.27 | 22.3% |
| 意大利 | 39368 | 401.1 | 723212.87 | 29.7% |
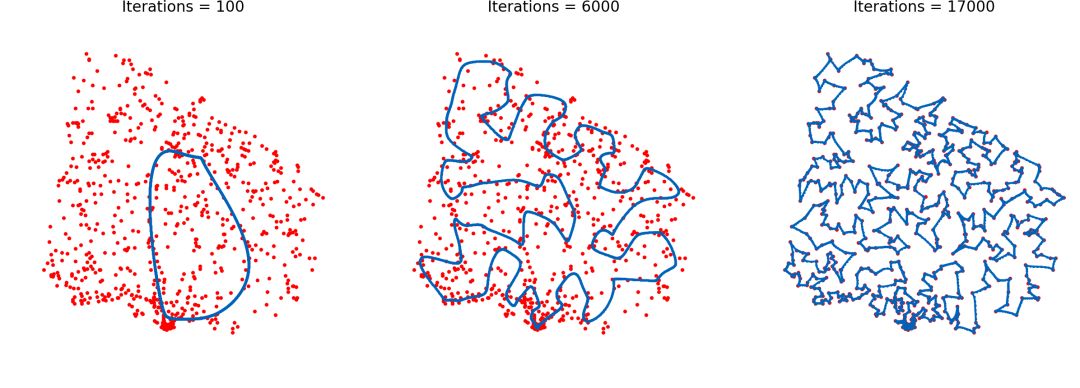
结果不错,我们能在400秒内得到次优方案,结果总体来说可以接受。例如在乌拉圭的734各城市里,模型最快能在25秒内找到仅比最优路线长7.5%的解决方案。
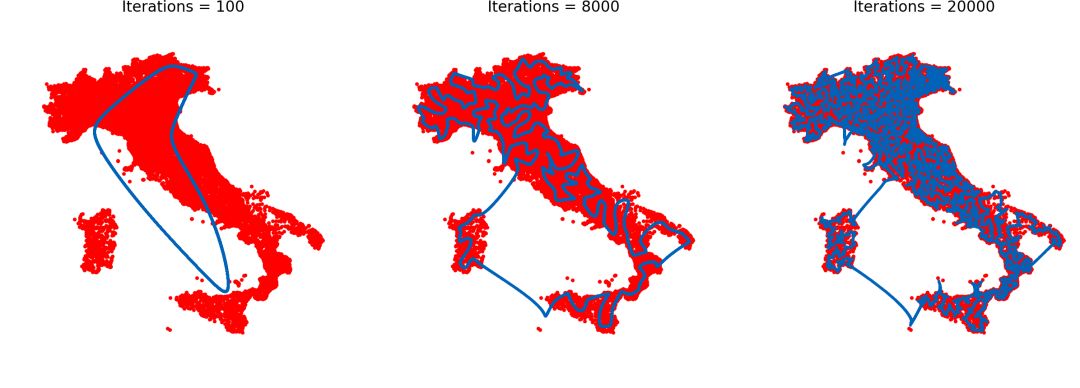
结语
虽然还未进行彻底的测试,但这一项目非常有趣,结果也表现得不错。最后附上GitHub和原文地址,可在其中找到代码。
原文地址:diego.codes/post/som-tsp/
GitHub地址:github.com/DiegoVicen/som-tsp





