Spark 3.0 新特性抢先看

记得 Databricks 研发工程师王耿亮老师去年在分享 Spark 新特性议题的时候,稍微透露了一些 关于 Spark 3.0 版本特性的内容,但具体的性能细节可以关注今年 ASF 和 Apache Spark PMC 最终的发布信息。这里做一些简单的介绍,具体技术细节请关注 9 月 11 日深圳站 ArchSummit 全球架构师峰会演讲。
作为 Project Hydrogen 的延续,在 Spark 3.0 版本里支持 GPU Aware Scheduling 调度,广泛用于加速特定应用,比如深度学习等。
发布 Data Source API,其设计比较合理,性能更稳定,批处理和流处理使用统一的 API。其背后的历史原因是,第一个版本的 Data Source API 在实现 Data Source 过程中不是很方便,后来做了 fire for mate。但是流处理的时候又使用另一套 API。所以社区花了很多时间把 API 都整合起来,后期能兼容各种云数据存储,例如 Hive,Delta 等等。
这是 Databricks 和Intel 中国团队在做的项目(https://tinyurl.com/y3rjwcos),基于已完成的执行计划节点的统计数据,优化剩余的查询执行计划,它的特点是:减少 Reducer 的数量;将 Sort Merge Join 转换为 Broadcast Hash Join;处理数据倾斜。以下图为例:
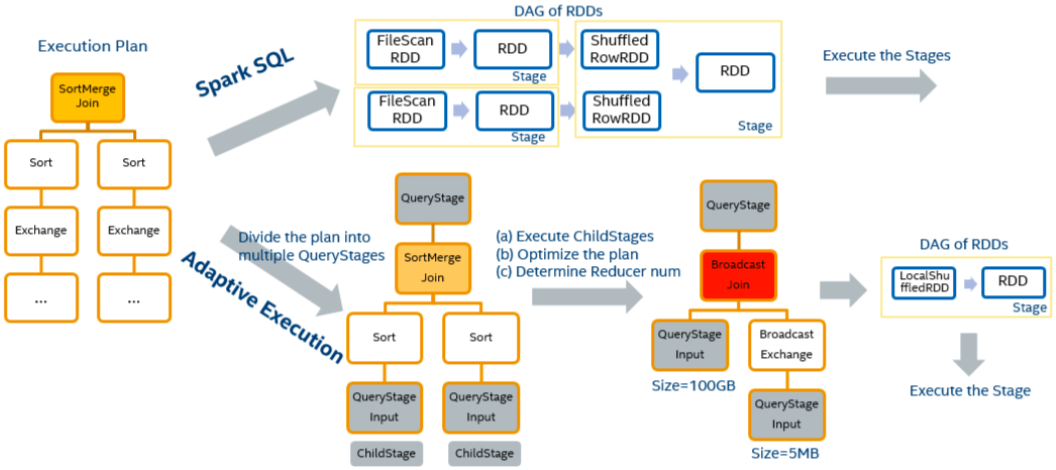
这是一个典型的 Spark 任意操作过程,读取两个文件,而使用 Adaptive Execution 方法之后,避免了存储的过程,性能也有了很大的提升。
Spark 3.0 在 Kubernetes 上有更多的功能,例如支持使用 pod 模板来定制化 driver 和 executor 对应的 pods;支持动态资源申请,资源空闲的时候,减少 executor 数量,资源紧张的时候,动态的加入一些 executor;支持外置的 shuffle 服务,将 shuffle 服务放在独立的 pod 里,能够解耦成一个架构。
• 支持 Hadoop 3.x
• Hive execution 从 1.2.1 升级至 2.3.4
• Scala 2.12 GA
• 更加遵从 ANSI SQL
• 提高 PySpark 可用性

很多数据科学家之前在学数据分析的时候使用 Python 的 Pandas,但是真正到了生产环境,Pandas 只能运行在一台机器上,而且是单线程,性能和可扩展性有限。这个时候需要转到 Spark,但是受到 API 区别,所以会有一些局限。

但是后来开源了 Koalas,目标是使用 Pandas API 可以直接运行在 Spark,能够支持数据科学家更好的无缝迁移到 Spark。

关于 Spark 3.0 新特性的解读,我们邀请王耿亮老师在今年 9 月 11 日 ArchSummit 全球架构师峰会(深圳站)上详细介绍,包括 Delta Lake 新功能介绍、设计思路细节、用户在使用过程中遇到的坑(案例),以及解决方法。感兴趣的可以点击阅读原文查看会议官网。
👇点击阅读原文查看更多大会内容





