推荐系统中的产品聚类:一种文本聚类的方法

作者:Dimitris Apostolopoulos
编译:ronghuaiyang
给大家介绍一下推荐系统中的产品聚类方法。
之前有一篇文章,推荐系统之路,介绍了推荐系统的一些基础知识,并用矩阵分解的方法实现了一个基础的推荐系统,今天接下来后面的内容。
在上一篇文章中,我把我的船驶向了"推荐系统"的岛屿,但是由于矩阵系统的性能问题,我的船受到了严重的伤害。

因此,现在,在接下来的文章中,我将一个接一个地找出每一个问题,并尝试修复它们(剧透警告:最后一切都会得到修复)。
让我们从中断的地方快速浏览一下。
“疼痛定位”:找出问题所在
正如本系列文章的第一部分中所描述的,我们面临的问题之一是:我们上一篇文章中的交互矩阵太大,无法度量。这是由于我们收集了大量的数据,其中包含重复的信息,因为相同的产品或类似的产品可以在不同的商店中找到。
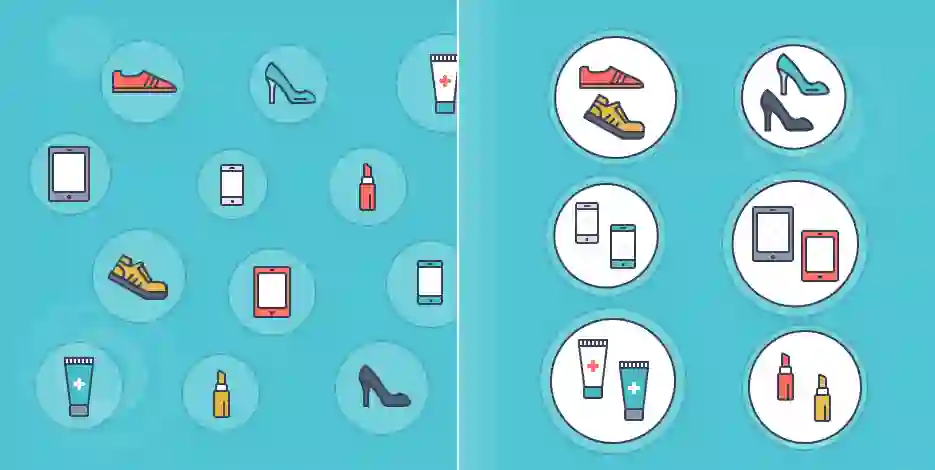
换句话说,如果你销售耳机,而你的三个竞争对手也在销售同一品牌的耳机,那么你的矩阵上就会有重复的产品,这就会毫无理由地减慢你的速度。
这就是为什么本文的目的是实现相同或非常相似的产品的跨店标识。
“仔细看看”:合并信息
现在,每家商店都使用自己的内部系统来跟踪产品。因此,每个商店的产品代码都是独一无二的。
更糟糕的是,我们也不能依赖产品价格,因为不同的商店价格不同。
这给我们留下了两个选项:产品标题和产品 URL。
如果一个人可以做一个从网站页面上拉取数据的网页采集器话,产品的 URL 可以是一个很好的信息来源,但是,由于 HTML 是“无结构”的,我们不能有这样一个网页采集器可以对每个网站都适用。
这样就只剩下一个选项,即整个聚类中只使用产品标题。
“做作业”:文本预处理
什么是预处理?
遵循这些文本聚类预处理的步骤
我们对数据进行预处理的步骤如下:
-
首先,我们识别品牌并将它们从标题中移除,这样我们只剩下产品名称。 -
然后,我们删除描述颜色的词,以减少数据的噪音,因为,在这一点上,我们想要根据颜色来分类产品。例如,我们想创建一个类别“黑色匡威全明星鞋 10”和另一个类别“白色匡威全明星鞋 10.5”。 -
之后,我们从标题中删除了数字和度量单位(如果有的话),因为我们想创建具有非常相似产品的组,比如“Cola 330ml”和“Cola 500ml”。 -
最后,我们对单词进行词干处理,也就是说,去掉单词的后缀以找到一个共同的词根,同时去掉所有的停止词。 -
为了将标题数据输入到算法中,我们将数据转换为向量。为了实现这一点,我们使用了两个不同的向量转换器:CountVectorizer,它创建了只有{0,1}的二进制向量,以及tf-idf 向量转换器,它根据单词在所有向量中的频率为所有单词分配权重。在本例中,我们使用两个向量转换器来找到对我们更有效的那个。
继续:文本聚类
什么是文本聚类?
文本聚类是在未标记的数据中生成组的过程。在大多数聚类技术中,组的数量是由用户预定义的,但是在这种情况下,聚类组的数量必须动态变化。
我们可以有包含单个产品的聚类,也可以有包含 10 个或更多产品的聚类,这个数字取决于我们能找到多少类似的产品。
我们的需求减少了我们的选择。DBSCAN 是一种基于密度的算法,它依赖于向量之间的距离,从而创建组。
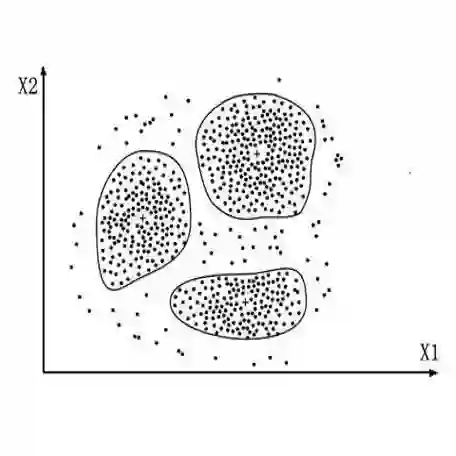
DBSCAN 生成的组:

为什么 DBSCAN 不能正确地对数据聚类?
产品的标题是一个很短的句子(1-5 个单词)。然而,我们创建的向量非常大,因为来自数据集中的所有唯一的单词组成了词汇表。词汇表的长度就是向量的长度,因此我们失去了所有的信息。
降维技术,诸如 PCA 和 SVD 之类的不能帮助解决这个问题,因为转换矩阵的每一列都代表一个单词。
因此,当你删除一些列时,你将删除许多产品。
由于现有的解决方案不能正常工作,我们决定构建一个自定义的聚类流程,旨在找到问题的解决方案。
训练向量生成器
当你训练一个向量生成器时,它将学习到给定句子包含的单词。
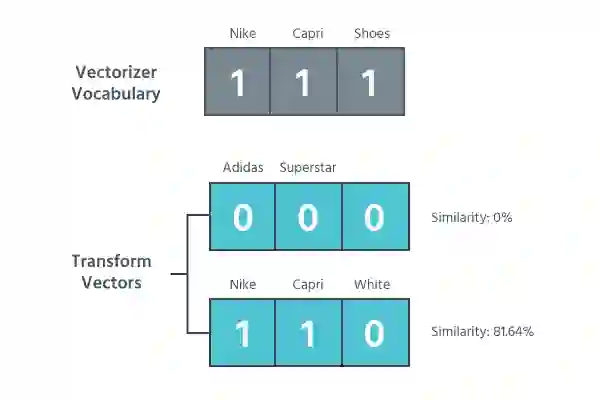
例如,当被给予““Nike Capri Shoes”时,向量生成器只学习这三个词。这意味着当你对其他产品进行变换时,除了那些包含一个或所有单词的向量,其他变换出来的向量都是 0。
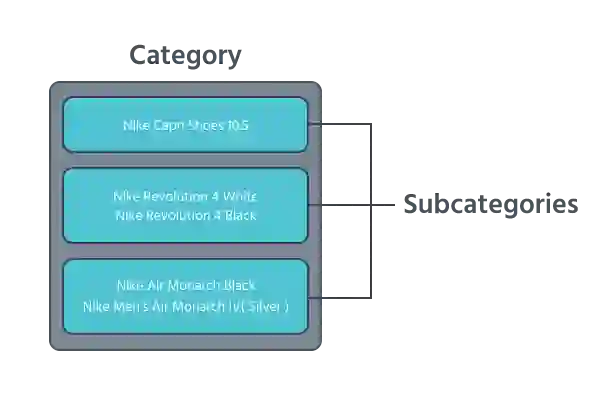
为了找出两个向量有多相似,我们测量它们基于欧氏距离的相似度。要把两个单词归到同一组里,这两个单词之间的相似度必须高于我们的阈值。我们生成的组称为categories。
把我们的数据想象成一大桶产品。categories 是有用的,因为它们创建了包含我们可以处理的相关数据的小桶。
现在,我们通过使用更高的阈值再次运行相同的进程来为每个 bucket 创建子类别,并创建子类别。子类别是我们将使用的最终的组。
换档:提高速度的小窍门
之后,我们根据标题中包含的单词数对数据进行排序,因此只有一个单词的标题将位于列表的顶部,而单词最多的标题位于列表的底部。
这样,一个词的标题将构成我们的大多数类别,减少我们处理的数据量。

英文原文:https://medium.com/moosend-engineering-data-science/product-clustering-a-text-clustering-approach-c392c2ef4310
推荐阅读
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。