语音合成:模拟最像人类声音的系统

目前国内的语音合成技术趋于成熟,但是企业对语音合成候选人的要求也极高。语音技术相较于AI其他方向而言,具有典型的跨学科特点。除了声学、语音语言学、信号处理等,还要会编程语言,并且要对常见的深度学习模型有深入了解,以及对语音合成本身的Tacotron、WaveNet等系统异常熟悉。内容涉及的越广泛,大家学习周期也就越长,企业的人才缺口也会相应的增加。

并且语音合成算法工程师的薪资也极为可观,基本是30k/月起步。(是不是很心动!)
◐
1.讲师团队介绍





◐
2. 实践项目
实现基于CRF的分词

World vocoder参数提取与合成
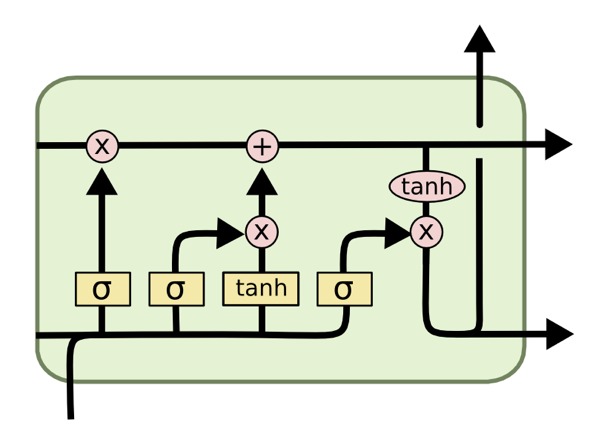
基于LSTM/GRU的声学与时长模型
在此实践中,我们将基于Tensorflow实现递归神经网络LTSM/GRU的语音合成时长与声学模型。从而将设计好的文本特征经过时长和声学模型,合成语音。
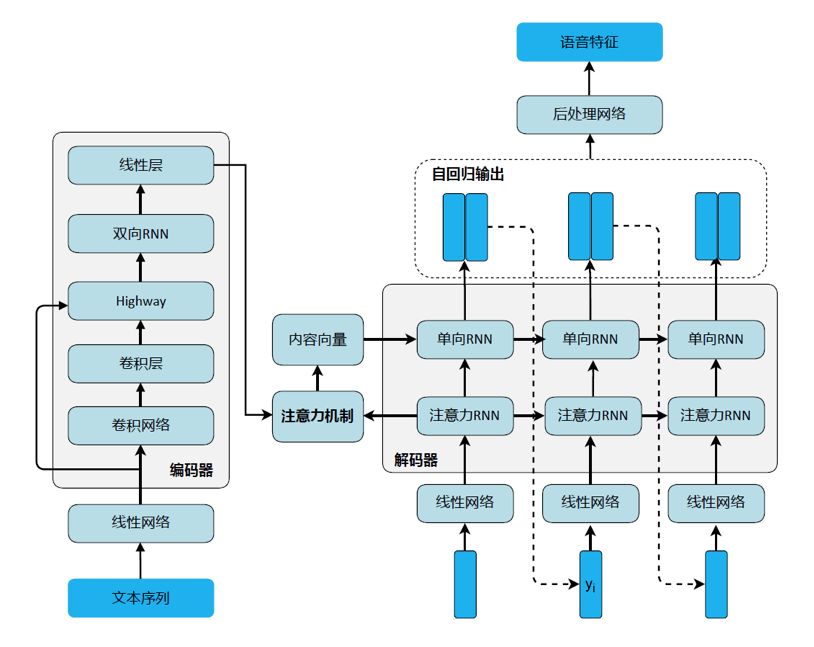
实现基于Tacotron的声学模型
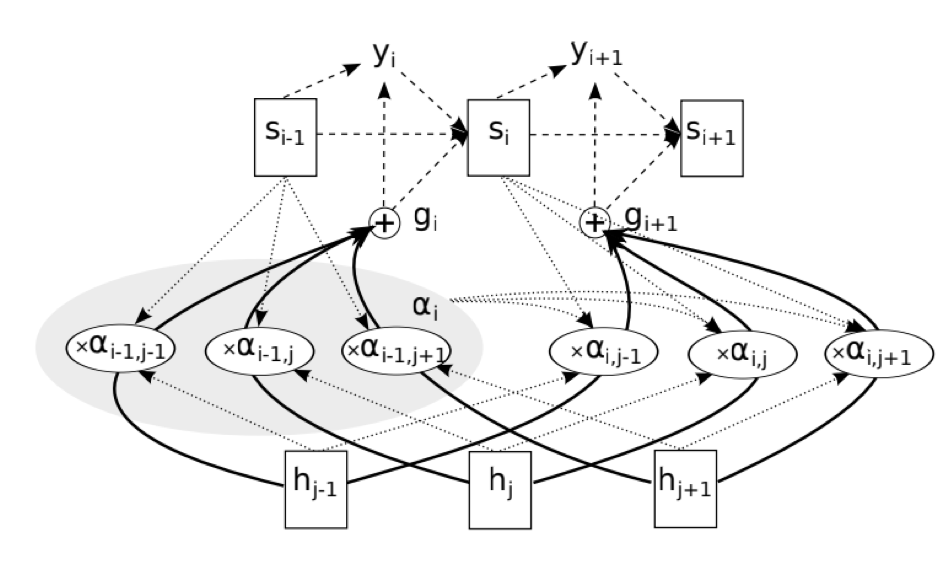
实现基于LSA的注意力机制
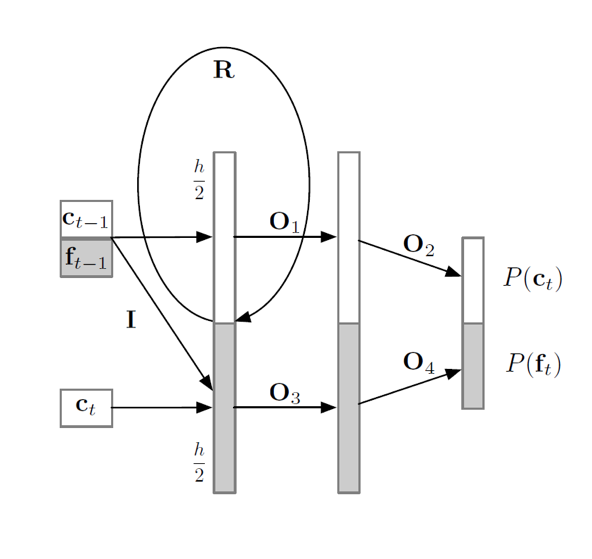
实现基于Mel特征的WaveRNN
◐
3. 课程亮点
1.本课程全面覆盖当前主流算法和模型,学习省时省力;
2.授课团队为国内知名的语音团队——西北工业大学谢磊团队;
3.理论与实践相结合。每章节课程后的都会配有相应的作业,助教1V1批改;
4.班主任带班。督促学习(告别拖延~);
5.超优质的学习圈子。学习本课程的同学来自超牛的学校与企业。
◐
4. 课程收获
1.掌握传统语音合成系统中文本正则化、分词、注音、韵律预测等前端子模块的作用以及基于BLSTM+CRF的方法;
2.掌握传统语音合成系统中主流后端算法,包括基于HMM/NN的统计参数模型,以及基于单元拼接的方法;
3.领悟基于Attention的序列到序列算法的思想,掌握Tacotron模型的细节;
4.深入了解更适合语音任务的Attention机制及其应用;
5.熟悉基于WaveNet的神经网络声码器以及WaveRNN和LPCNet声码器的原理。

扫码添加深蓝学院-叶子
备注【130】,才会通过好友哦!

咨询课程可免费领取试听课哦~



