开源分布式 NewSQL 数据库 TiDB 2.0 正式发布
去年十月,TiDB 1.0 版本发布,在接下来的六个月中,开发团队一方面在维护 1.0 版本的稳定性并且增加必要的新特性,另一方面马不停蹄的开发 2.0 版本。经过 6 个 RC 版本,TiDB 2.0 GA 版本于 4 月 27 日正式发布。
TiDB 是国内 PingCAP 团队开发的一个分布式 SQL 数据库。其灵感来自于 Google 的 F1 和 Google spanner, TiDB 支持包括传统 RDBMS 和 NoSQL 的特性。
2.0 版本规划
根据现有用户的情况、技术发展趋势以及社区的声音,TiDB 2.0 版本主要聚焦在以下几点:
保证 TiDB 的稳定性以及正确性。这两点是一个数据库软件的基础功能,作为业务的基石,任何一点抖动或者错误都可能对业务造成巨大的影响。目前已经有大量的用户在线上使用 TiDB,这些用户的数据量在不断增加、业务也在不断演进。
提升 TiDB 在大数据量下的查询性能。TiDB 目前很多客户都有少则上百 GB,多则上百 TB 的数据,一方面数据会持续增加,另一方面也希望能对这些数据做实时的查询。所以如果能提升大数据量下的查询性能,对用户会很有帮助。
优化 TiDB 的易用性和可维护性。TiDB 整套系统的复杂性比较高,运维及使用的难度要大于单机数据库,所以希望能提供尽可能方便的方案帮助用户使用 TiDB。比如尽可能简化部署、升级、扩容方式,尽可能容易的定位系统中出现的异常状态。
围绕上面三点原则,TiDB 做了大量的改进,一些是对外可见,如 OLAP 性能的显著提升、监控项的大量增加以及运维工具的各项优化,还有更多的改进是隐藏在数据库背后,默默的提升整个数据库的稳定性以及正确性。
正确性和稳定性
在 1.0 版本发布之后,TiDB 开始构建和完善自动化测试平台 Schrodinger,彻底告别了之前靠手工部署集群测试的方式。同时也新增了非常多的测试用例,做到测试从最底层 RocksDB,到 Raft,再到 Transaction,然后是 SQL 都能覆盖。
在 Chaos 测试上面,TiDB 引入了更多的错误注入工具,例如使用 systemtap 对 I/O 进行 delay 等,也在代码特定的业务的逻辑进行错误注入测试,充分保证 TiDB 在异常条件下面也能稳定运行。
TiDB 的开发团队之前做了很多 TLA+ 的论证工作,也有一些简单的测试,1.0 之后开始使用 TLA+ 系统进行论证,保证所做的实现在设计上面都是正确的。
在存储引擎方面,为了提升大规模集群的稳定性和性能,TiDB 优化了 Raft 的流程,引入 Region Merge、Raft Learner 等新特性;优化热点调度机制,统计更多的信息,并根据这些信息做更合理的调度;优化 RocksDB 的性能,使用 DeleteFilesInRanges 等特性,提升空间回收效率,降低磁盘负载,以及更加平滑地使用磁盘资源等等。
OLAP 性能优化
TiDB 2.0 版本重构了 SQL 优化器和执行引擎,希望能尽可能快的选择最优查询计划并且尽可能高效地执行查询计划。
1.0 版本已经从基于规则的查询优化器转向基于代价的查询优化器,但是还不够完善,在 2.0 版本中,一方面优化统计信息的较精确度以及更新及时程度,另一方面提升 SQL 优化器的能力,对查询代价的估算更加精准、对复杂过滤条件的分析更加细致、对关联子查询的处理更加优雅、对物理算子的选择更加灵活准确。
在这一版本中,SQL 执行引擎引入新的内部数据表示方式 --- `Chunk`,一个结构中保存一批数据而不仅是一行数据,同一列的数据在内存中连续存放,使得内存使用更紧凑,这样带来了几点好处:
1. 显著减小了内存消耗;
2. 批量分配内存,减小了 GC 开销;
3. 算子之间可以对数据进行批量传递,减小调用开销;
4. 在某些场景下,可以进行向量计算以及减小 CPU 的 Cache Miss 的情况。
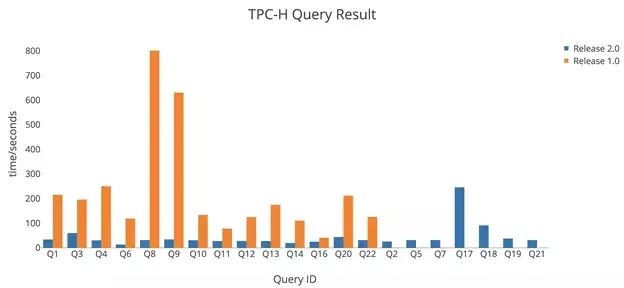
完成上述两项改动之后,TiDB 在 OLAP 场景下的性能有了大幅的质的提升,从 TPC-H 的对比结果来看,所有的 Query 在 2.0 中都运行得更快,一些 Query 大多数都有几倍甚至数量级的提升,特别是一些 1.0 中跑不出结果的 Query 在 2.0 中都能顺利执行。
易用性和可运维性
为了更容易被安装和使用,TiDB 2.0 在监控、运维、工具方面也做了诸多优化。
在监控方面,增加了过百个监控项,同时通过 HTTP 接口、SQL 语句等方式暴露出一些运行时信息,用于系统调优或者是定位系统中存在的问题。
在运维方面,运维工具做了优化,简化操作流程,降低操作复杂度及操作过程对于线上的影响。同时功能也更加丰富,支持自动部署 Binlog 组件、支持启用 TLS。
2.0 详细更新列表
TiDB
1.SQL 优化器
精简统计信息数据结构,减小内存占用
加快进程启动时加载统计信息速度
支持统计信息动态更新 [experimental]
优化代价模型,对代价估算更精准
使用 `Count-Min Sketch` 更较精确地估算点查的代价
支持分析更复杂的条件,尽可能充分的使用索引
支持通过 `STRAIGHT_JOIN` 语法手动指定 Join 顺序
`GROUP BY`子句为空时使用 Stream Aggregation 算子,提升性能
支持使用索引计算 `Max/Min` 函数
优化关联子查询处理算法,支持将更多类型的关联子查询解关联并转化成 `Left Outer Join`
扩大 `IndexLookupJoin` 的使用范围,索引前缀匹配的场景也可以使用该算法
2.SQL 执行引擎
使用 Chunk 结构重构所有执行器算子,提升分析型语句执行性能,减少内存占用,显著提升 TPC-H 结果
支持 Streaming Aggregation 算子下推
优化 `Insert Into Ignore` 语句性能,提升 10 倍以上
优化 `Insert On Duplicate Key Update` 语句性能,提升 10 倍以上
下推更多的数据类型和函数到 TiKV 计算
优化 `Load Data` 性能,提升 10 倍以上
支持对物理算子内存使用进行统计,通过配置文件以及系统变量指定超过阈值后的处理行为
支持限制单条 SQL 语句使用内存的大小,减少程序 OOM 风险
支持在 CRUD 操作中使用隐式的行 ID
提升点查性能
3.Server
支持 Proxy Protocol
添加大量监控项, 优化日志
支持配置文件的合法性检测
支持 HTTP API 获取 TiDB 参数信息
使用 Batch 方式 Resolve Lock,提升垃圾回收速度
支持多线程垃圾回收
支持 TLS
4.兼容性
支持更多 MySQL 语法
支持配置文件修改 `lower_case_table_names` 系统变量,用于支持 OGG 数据同步工具
提升对 Navicat 的兼容性
在 `Information_Schema` 中支持显示建表时间
修复部分函数/表达式返回类型和 MySQL 不同的问题
提升对 JDBC 兼容性
支持更多的 `SQL_MODE`
5.DDL
优化 `Add Index` 的执行速度,部分场景下速度大幅度提升
`Add Index` 操作变更为低优先级,降低对线上业务影响
`Admin Show DDL Jobs` 输出更详细的 DDL 任务状态信息
支持 `Admin Show DDL Job Queries JobID` 查询当前正在运行的 DDL 任务的原始语句
支持 `Admin Recover Index` 命令,用于灾难恢复情况下修复索引数据
支持通过 `Alter` 语句修改 Table Options
PD
1.增加 `Region Merge` 支持,合并数据删除后产生的空 Region [experimental]
2.增加 `Raft Learner` 支持 [experimental]
3.调度器优化
调度器适应不同的 Region size
提升 TiKV 宕机时数据恢复的优先级和恢复速度
提升下线 TiKV 节点搬迁数据的速度
优化 TiKV 节点空间不足时的调度策略,尽可能防止空间不足时磁盘被写满
提升 balance-leader scheduler 的调度效率
减少 balance-region scheduler 调度开销
优化 hot-region scheduler 的执行效率
4.运维接口及配置
增加 TLS 支持
支持设置 PD leader 优先级
支持基于 label 配置属性
支持配置特定 label 的节点不调度 Region leader
支持手动 Split Region,可用于处理单 Region 热点的问题
支持打散指定 Region,用于某些情况下手动调整热点 Region 分布
增加配置参数检查规则,完善配置项的合法性较验
5.调试接口
增加 `Drop Region` 调试接口
增加枚举各个 PD health 状态的接口
6.统计相关
添加异常 Region 的统计
添加 Region 隔离级别的统计
添加调度相关 metrics
7.性能优化
PD leader 尽量与 etcd leader 保持同步,提升写入性能
优化 Region heartbeat 性能,现可支持超过 100 万 Region
TiKV
1.功能
保护关键配置,防止错误修改
支持 `Region Merge` [experimental]
添加 `Raw DeleteRange` API
添加 `GetMetric` API
添加 `Raw Batch Put`,`Raw Batch Get`,`Raw Batch Delete` 和 `Raw Batch Scan`
给 Raw KV API 增加 Column Family 参数,能对特定 Column Family 进行操作
Coprocessor 支持 streaming 模式,支持 streaming 聚合
支持配置 Coprocessor 请求的超时时间
心跳包携带时间戳
支持在线修改 RocksDB 的一些参数,包括 `block-cache-size` 大小等
支持配置 Coprocessor 遇到某些错误时的行为
支持以导数据模式启动,减少导数据过程中的写放大
支持手动对 region 进行对半 split
完善数据修复工具 tikv-ctl
Coprocessor 返回更多的统计信息,以便指导 TiDB 的行为
支持 ImportSST API,可以用于 SST 文件导入 [experimental]
新增 TiKV Importer 二进制,与 TiDB Lightning 集成用于快速导入数据 [experimental]
2.性能
使用 ReadPool 优化读性能,`raw_get/get/batch_get` 提升 30%
提升 metrics 的性能
Raft snapshot 处理完之后立即通知 PD,加快调度速度
解决 RocksDB 刷盘导致性能抖动问题
提升在数据删除之后的空间回收
加速启动过程中的垃圾清理过程
使用 `DeleteFilesInRanges` 减少副本迁移时 I/O 开销
3.稳定性
解决在 PD leader 发送切换的情况下 gRPC call 不返回问题
解决由于 snapshot 导致下线节点慢的问题
限制搬移副本临时占用的空间大小
如果有 Region 长时间没有 Leader,进行上报
根据 compaction 事件及时更新统计的 Region size
限制单次 scan lock 请求的扫描的数据量,防止超时
限制接收 snapshot 过程中的内存占用,防止 OOM
提升 CI test 的速度
解决由于 snapshot 太多导致的 OOM 问题
配置 gRPC 的 `keepalive` 参数
修复 Region 增多容易 OOM 的问题
此外,同时发布的还有 TiSpark 1.0 GA 版本。TiSpark 1.0 版本组件提供了针对 TiDB 上的数据使用 Apache Spark 进行分布式计算的能力。更新包括:
1.提供了针对 TiKV 读取的 gRPC 通信框架
2.提供了对 TiKV 组件数据的和通信协议部分的编码解码
3.提供了计算下推功能,包含
聚合下推
谓词下推
TopN 下推
Limit 下推
4.提供了索引相关支持
谓词转化聚簇索引范围
谓词转化次级索引
Index Only 查询优化
运行时索引退化扫表优化
5.提供了基于代价优化
统计信息支持
索引选择
广播表代价估算
6.多种 Spark Interface 的支持
Spark Shell 支持
ThriftServer/JDBC 支持
Spark-SQL 交互支持
PySpark Shell 支持
SparkR 支持
文章来源:开源中国

《MySQL性能优化最佳实践》本课是一门基于MySQL数据库的性能优化课,全课以某大型互联网公司的实际项目为主线去分析、优化、总结。老师将把毕生功力传授给你!!点击下方二维码报名课程