论文浅尝 - ICLR2020 | Abductive Commonsense Reasoning
论文笔记整理:毕祯,浙江大学硕士,研究方向:知识图谱、自然语言处理。

动机
尽管长期以来人们一直认为归因是人们在自然语言界线之间进行解释和阅读的核心,但很少有研究支持归因自然语言推理和产生。这篇文章提出了第一个研究基于语言的归纳推理可行性的研究,引入了一个数据集ART,该数据集包含超过20k的常识性叙述上下文和200k的解释。并且基于此数据集将两个新任务概念化:(i)归因法NLI:问答的任务,用于选择更可能的解释;(ii)归因法NLG:用于自然地解释给定观测值的条件生成任务语言。在Abductive NLI上,模型最佳可达到68.9%的准确度,低于91.4%的人工性能。在Abductive NLG上,当前最好的语言生成器同样不尽人意,因为它们缺乏对人类来说微不足道的推理能力。尽管它们在涉及NLI的相关任务但定义更窄的任务上表现出色,文章的分析为深入的预训练语言模型无法执行的推理类型提供了新的见解。
任务定义
归纳(归因)自然语言推理:将αNLI公式化为由一对观察结果和一对假设选择组成的多项选择问题。ART中的每个实例定义如下:
• O1$:在时间 t1的观测现象;
• O2:在时间 t2>t1 处的观测现象;
• h+:一个合理的假设,解释了两个观测值O1和O2。
• h-:观测值和的不可信(不合理)的假设。
给定观察结果和一对假设,αNLI的任务是选择最合理的解释(假设)。
归纳(归因)自然语言生成:αNLG是在给出两个观测值 O1 和 O2 的情况下生成有效假设 h^+ 的任务,形式上该任务需要最大化 P(h+ | O1, O2 )。
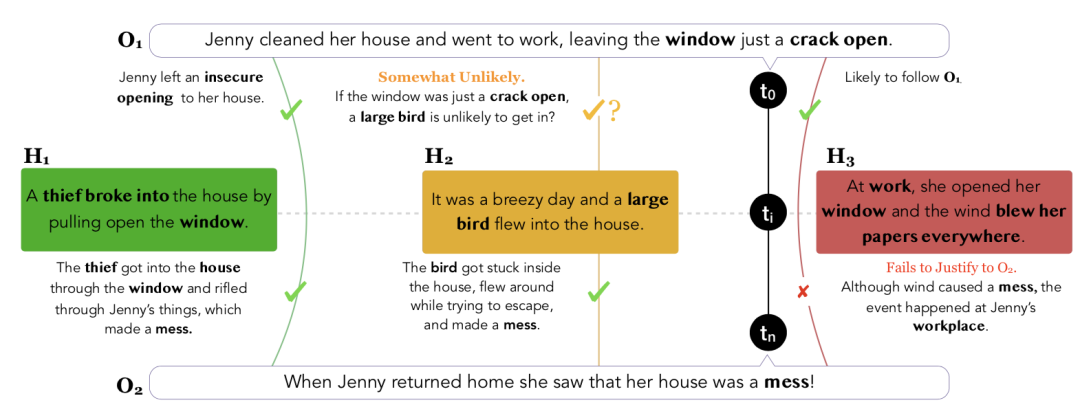
图 1 归因推理的例子
常识归因推理模型架构
归纳(归因)自然语言推理:αNLI任务的一个特征是需要共同考虑所有可用的观测值及其常识,以识别正确的假设。形式上αNLI任务是选择给定观测值最可能的假设(公式1)。
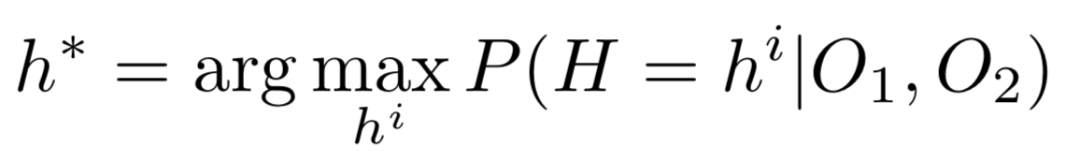
使用以O1为条件的贝叶斯规则重写目标函数,得到(公式2):
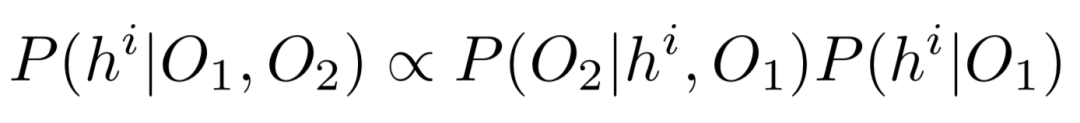
论文为αNLI制定了一套概率模型,这些模型对上述的公式进行了各种独立性假设,从一个完全忽略观测值的简单基线开始,然后建立一个完全联合的模型。这些模型在图2中被描述为贝叶斯网络。从理论上讲,“完全连接”模型可以将来自两个可用观测值的信息进行组合。

图2 概率框架中描述的图形模型的图示。
Hypothesis Only:最简单的模型做出了一个强有力的假设,即假设完全独立于两个观察值,即 (H ⊥ O1, O2),在这种情况下,目标只是最大化 P(H)。
仅第一次(或第二次)观察:接下来的两个模型做出了较弱的假设:该假设仅取决于第一次O1或第二次O2观察中的一个。
线性链:下一个模型同时使用两个观察值,但会独立考虑每个观察值对假设的影响,即它不会合并各个观察值的信息。形式上该模型假设三个变量<O1,H,O2>形成线性马尔可夫链,其中第二个观测值在给定假设下(即 (O1 ⊥ O2|H))有条件地独立于第一个观测值。在这种假设下,目标是使公式2稍微简单些(公式3):
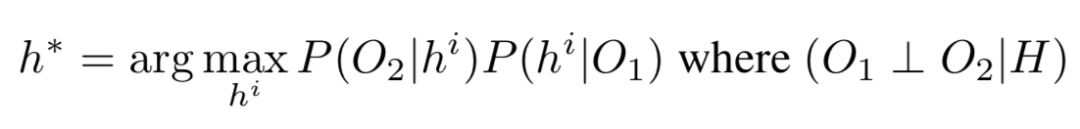
全联接性:最后最复杂的模型按照公式2共同对所有三个随机变量进行建模,并且原则上可以合并两个观测值的信息以选择正确的假设。
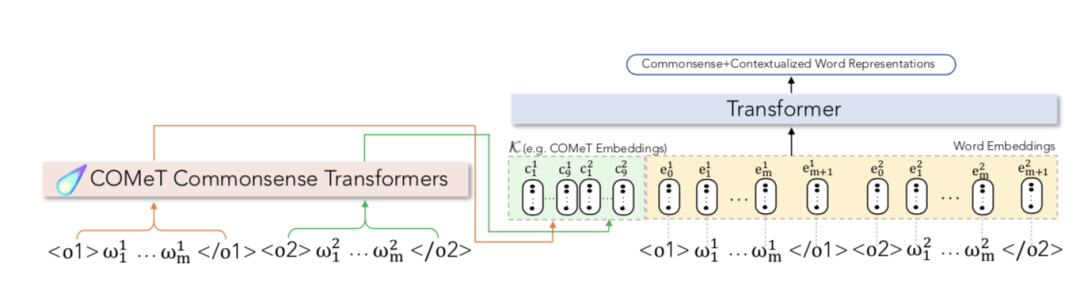
图3 αNLG 任务
为了说明线性链模型和完全连接模型如何同时考虑这两种观察结果之间的细微区别,作者举了一个示例。观察现象 O1:“卡尔拼命去商店寻找面粉玉米饼作为食谱。”和O2:“卡尔非常沮丧地离开了商店。”然后考虑两个不同的假设,一个不正确的h1:“收银员很粗鲁”,一个正确的h2:“商店有玉米饼,但没有面粉。”对于此示例,线性链模型可能会得出错误的答案,因为它会分别对观察结果进行解释——将O1单独分离,h1和h2似乎都可能是下一个事件,尽管每个事件都是先验的。对于分离的O2,即在没有O1的情况下,对于随机抽取的购物者而言,H1的粗鲁收银员解释似乎比卡尔的玉米饼选择细节更有说服力。结合这两个单独的因素,线性链会选择h1作为更合理的解释。就像完全连接模型中那样,只有通过对卡尔在O1中的目标以及他对O2的沮丧进行推理,我们才能得出正确的答案h2作为更合理的解释。
实验中,在性能最佳的神经网络模型中编码不同的独立性假设。对于仅假设和单一观察模型,可以通过简单地将模型的输入限制为仅相关变量来强制执行独立性。另一方面,线性链模型将所有三个变量作为输入,但是该模型限制了模型的形式以强制条件独立。具体来说是学习了一个判别式分类器:
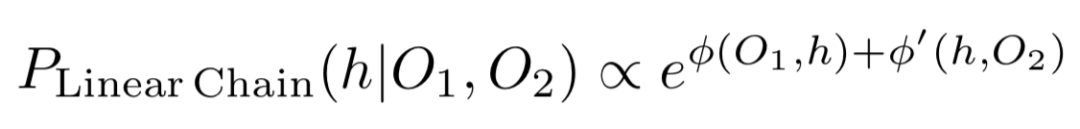
其中φ和φ'是产生标量值的神经网络。
归纳(归因)自然语言生成:给定 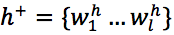
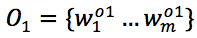
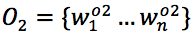
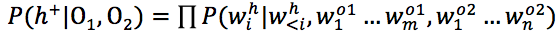
该模型还可以以背景知识K为条件。参数化的模型可以最大程度减少ART中实例的负面对数可能性为目标进行训练:
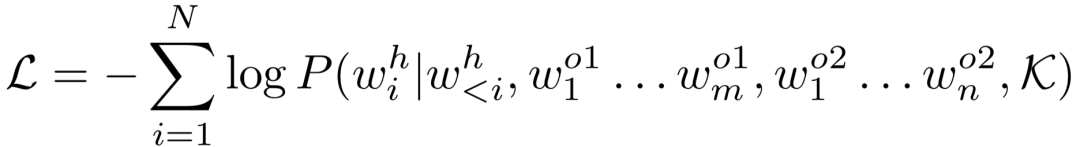
数据集准备
ART是第一个用于研究叙事文本中的归纳推理的大规模基准数据集。它由约20K的叙述情境(成对的观测值⟨O1,O2⟩)和超过200K的解释假设组成。附录中的表6总结了ART数据集的语料库级统计。图4显示了ART的一些示例。
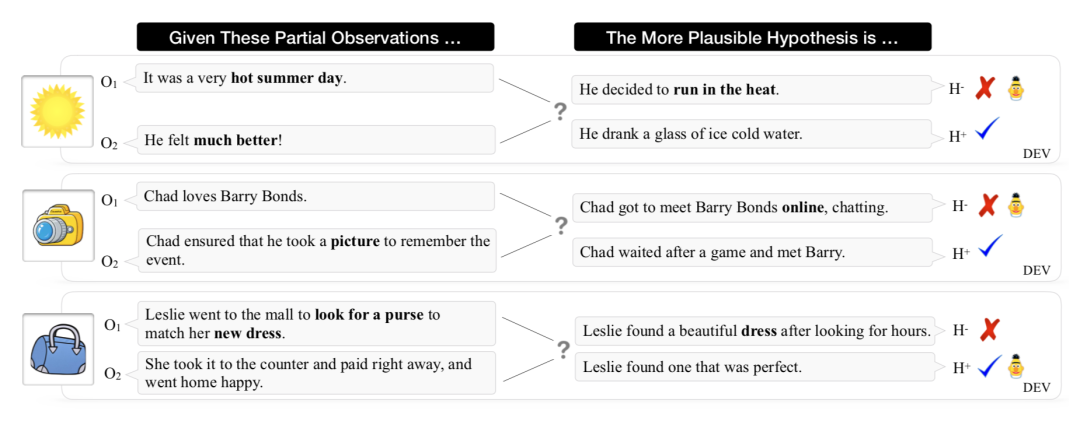
图4 ART数据示例
实验结果及分析
在ART数据集以及αNLI和αNLG的其他几个baseline上,对经过微调的的预训练语言模型进行评估。由于αNLI被构造为二进制分类问题,因此选择准确性作为主要指标。对于αNLG,报告了BLEU、CIDEr、METEOR(等自动化指标的性能,并报告了人类评估结果。
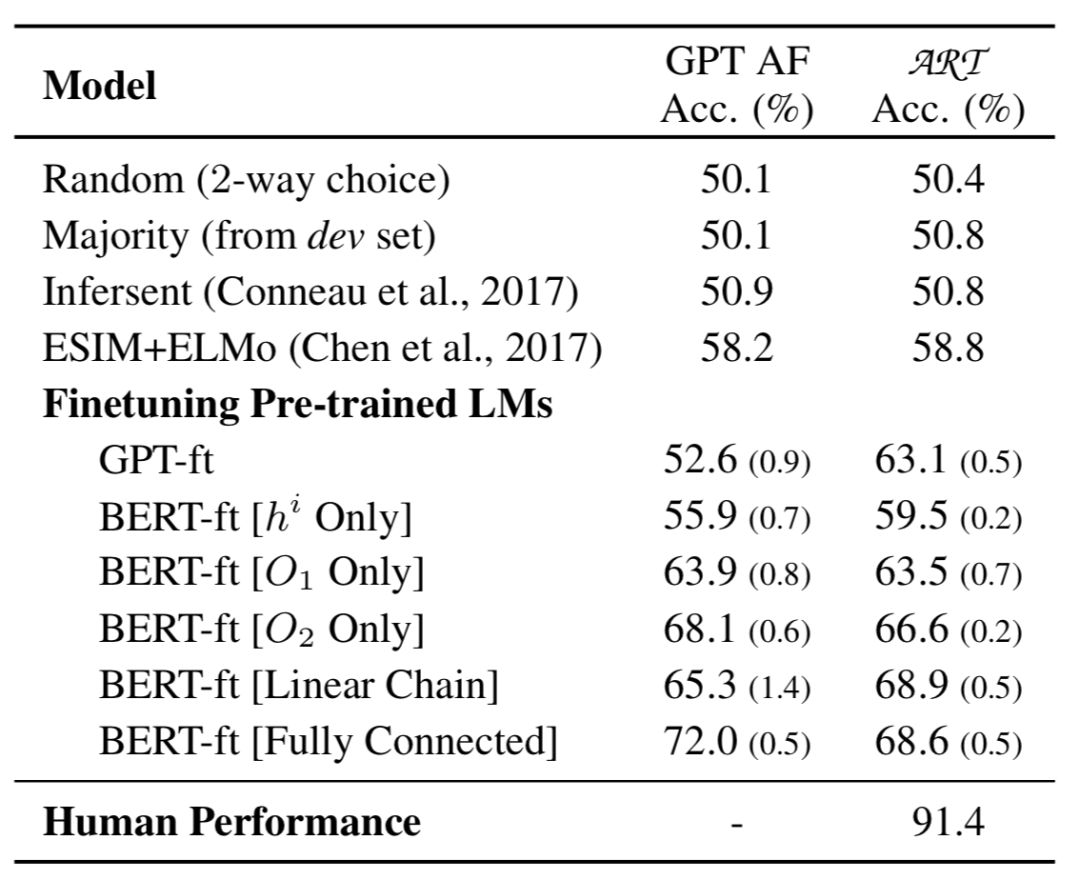
表1 基线和微调LM方法在ART测试集上的性能。
尽管在其他几个NLP的基准数据集上表现出色,但基于BERT的最佳基准模型在ART上的准确度仅为68.9%,而人类表现为91.4%。人与最佳系统之间的巨大差距为开发更复杂的归纳推理模型提供了广阔的空间。实验表明,在完全连接的模型上引入之前描述的其他独立性假设通常会降低系统性能(参见表1)。
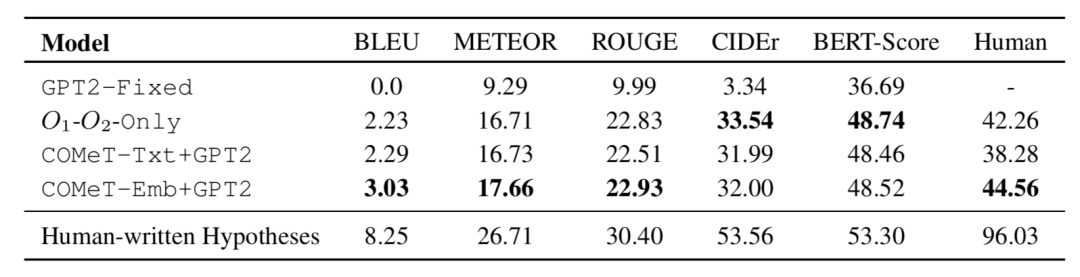
表2 生成模型在ART测试集上的性能。除GPT2-Fixed外,所有型号均在ART上进行了微调。
表2报告了有关αNLG任务的结果。在自动指标中,报告了BLEU-4、METEOR、ROUGE、CIDEr和BERT-Score((使用基于bert的无案例模型)。其中通过在AMT上进行众包来建立人的结果。向人群工作人员显示了成对的观察结果和生成的假设,并要求其标记假设是否解释了给定的观察结果。最后一栏报告人类评估得分。最后一行报告坚持的人类假设的得分,并作为模型性能的上限。发现人工编写的假设对96%的实例是正确的,而即使通过背景常识知识进行了改进,最好的生成模型也只能达到45%,这表明αNLG生成任务对于当前的状态尤其具有挑战性最好的文本生成器。
结论
本文提出了第一个基于语言的归纳推理的可行性的研究,概念化并介绍了归纳自然语言推理(αNLI)。这是一项新颖的任务,专注于叙事上下文中的归纳推理。该任务被表述为多项选择的回答问题。文章还介绍了归纳自然语言生成(αNLG)–这是一项新颖的任务,需要机器为给定的观察结果生成合理的假设。为了支持这些任务,作者创建并引入了一个新的挑战数据集ART,该数据集由20,000个常识性叙述以及200,000多个解释性假设组成。在实验中,基于最新的NLI和语言模型在此新任务上建立了全面的基线性能,导致了68.9%的准确度,与人类表现之间存在相当大的差距(91.4%)。αNLG的任务要艰巨得多,尽管人类可以96%地写出有效的解释,但是最好的生成器模型只能达到45%。文章的分析为深入的预训练语言模型无法执行的推理类型提供了新的见解,尽管它们在涉及NLI的紧密相关但又不同的任务中表现出色,最后指出了未来研究的有趣途径。作者们希望ART将成为未来基于语言的归纳推理研究的具有挑战性的baseline基准,并且αNLI和αNLG任务将鼓励在AI系统中实现复杂推理能力的表示学习。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



