基于决策树模型重用的分布变化流数据学习

在很多真实应用中,数据以流的形式不断被收集得到.由于数据收集环境往往发生动态变化,流数据的分布也会随时间不断变化.传统的机器学习技术依赖于数据独立同分布假设,因而在这类分布变化的流数据学习问题上难以奏效.本文提出一种基于决策树模型重用的算法进行分布变化的流数据学习.该算法是一种在线集成学习方法:算法将维护一个模型库,并通过决策树模型重用机制更新模型库.其核心思想是希望从历史数据中挖掘与当前学习相关的知识,从而抵御分布变化造成的影响.通过在合成数据集和真实数据集上进行实验,我们验证了本文提出方法的有效性.
https://engine.scichina.com/doi/10.1360/SSI-2020-0170
机器学习技术在诸多领域得到了广泛应用, 包括图像、视频、语音、文本处理等[1∼3] . 传统的机器 学习技术假定数据分布是恒定的, 但数据收集的环境通常是开放动态的, 因而数据分布恒定这一假设 往往难以满足. 特别在诸如天气预测、股票价格预测、语音识别等真实应用场景中, 数据以流的形式 不断被在线得到, 随着时间不断累积, 数据分布往往会随着收集环境的动态变化而不断变化. 传统的 机器学习算法及理论依赖于数据同分布假设, 难以适用于这类分布不断变化的流数据问题. 因而, 针 对分布变化的流数据, 如何设计性能良好且有理论保障的学习算法是非常重要的课题.
首先需要明确的是, 如果对流数据的分布变化一无所知, 甚至允许分布任意、敌对变化, 那么这样 的问题是不可学的. 分布变化流数据学习的基本假设是: 历史数据中包含对当前预测有价值的知识. 该领域以往有一些相关工作, 代表性方法如基于滑动窗口机制的学习算法 [4∼6]、基于遗忘加权机制的 学习算法[7, 8] 和基于集成学习机制的学习算法 [9∼11] , 均建立在前述基本假设之上, 区别在于如何建模 并利用当前预测和历史数据之间的相关性. 如果没有该基本假设, 分布变化的流数据学习将无从谈起.
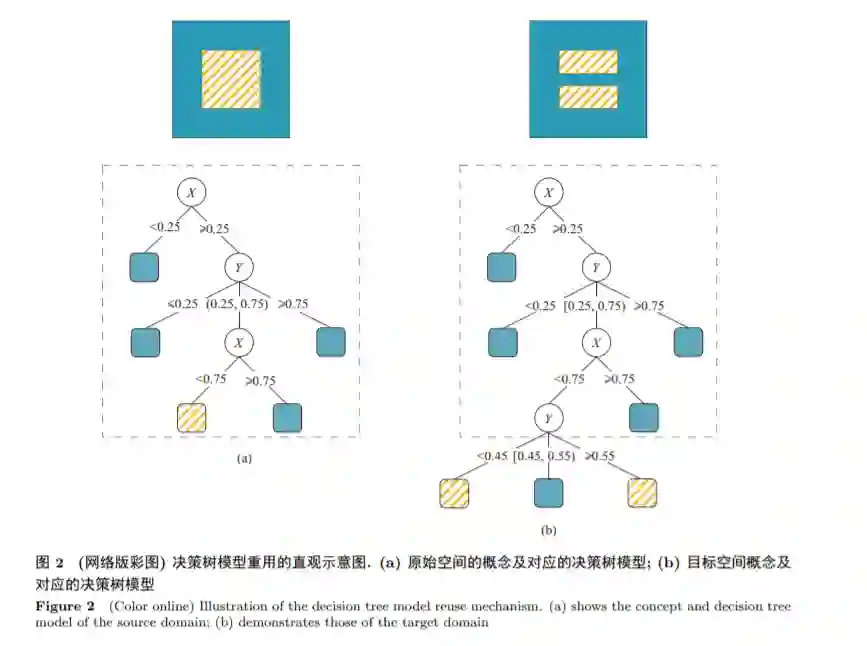
基于上述认知, 本文试图显式建模当前预测和历史数据之间的关系, 自适应挖掘历史数据中对当 前预测有用的知识, 并通过模型重用 (model reuse) 机制利用这些知识以辅助当前时刻的学习. 具体而 言, 本文采用在线集成学习的机制, 通过维持一个模型库并对其动态调整更新以对抗流数据中的分布 变化. 由于决策树模型的灵活性, 它特别适合集成学习框架, 并且决策树模型可以通过简单的伸展和 收缩操作实现模型知识的重用, 因而我们选择决策树模型作为基学习器. 本文提出 CondorForest 学习 算法. 在每次模型更新时刻, CondorForest 算法首先通过自适应权重调整机制, 给出历史模型相对当 前数据的可重用性权重. 然后算法根据可重用性权重重用历史的决策树模型学习得到新的决策树, 并 加入到模型库中进行更新. 我们通过在合成数据集以及真实数据集上进行实验, 验证了本文提出算法 的有效性.
本文第 2 节从分布变化的流数据学习和模型重用两个方面介绍相关工作. 第 3 节介绍本文提出 的 CondorForest 算法, 并给出了相应分析. 第 4 节通过在合成和真实数据集上的实验, 验证算法的有 效性. 最后总结全文, 并对未来工作做出展望.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“决策树模型” 可以获取《基于决策树模型重用的分布变化流数据学习》专知下载链接索引




