本文介绍一篇香港中文大学发表于 ICLR 2020 的论文《Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification》[1],其旨在解决更实际的开放集无监督领域自适应问题,所谓开放集指预先无法获知目标域所含的类别。
这项工作在多个行人重识别任务上验证其有效性,精度显著地超过最先进技术 13%-18%,大幅度逼近有监督学习性能。这也是 ICLR 收录的第一篇行人重识别任务相关的论文,代码和模型均已公开。
论文链接:https://openreview.net/forum?id=rJlnOhVYPS
代码链接:https://github.com/yxgeee/MMT
行人重识别(Person ReID)旨在跨相机下检索出特定行人的图像,被广泛应用于监控场景。如今许多带有人工标注的大规模数据集推动了这项任务的快速发展,也为这项任务带来了精度上质的提升。然而,在实际应用中,即使是用大规模数据集训练好的模型,若直接部署于一个新的监控系统,显著的领域差异通常会导致明显的精度下降。在每个监控系统上都重新进行数据采集和人工标注由于太过费时费力,也很难实现。所以无监督领域自适应(Unsupervised Domain Adaptation)的任务被提出以解决上述问题,让在有标注的源域(Source Domain)上训练好的模型适应于无标注的目标域(Target Domain),以获得在目标域上检索精度的提升。值得注意的是,有别于一般的无监督领域自适应问题(目标域与源域共享类别),行人重识别的任务中目标域的类别数无法预知,且通常与源域没有重复,这里称之为开放集(Open-set)的无监督领域自适应任务,该任务更为实际,也更具挑战性。
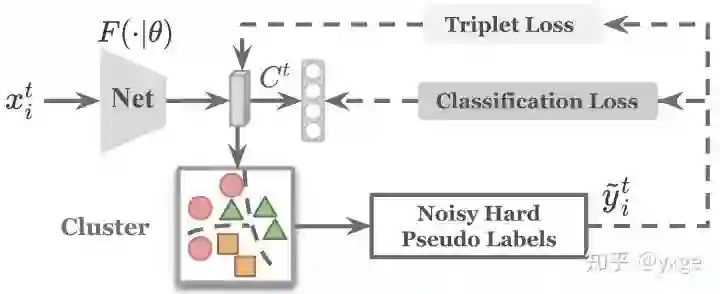
无监督领域自适应在行人重识别上的现有技术方案主要分为基于聚类的伪标签法、领域转换法、基于图像或特征相似度的伪标签法,其中基于聚类的伪标签法被证实较为有效,且保持目前最先进的精度 [2,3],所以该论文主要围绕该类方法进行展开。基于聚类的伪标签法,顾名思义,(i) 首先用聚类算法(K-Means, DBSCAN 等)对无标签的目标域图像特征进行聚类,从而生成伪标签,(ii) 再用该伪标签监督网络在目标域上的学习。以上两步循环直至收敛,如下图所示:
基于聚类的伪标签法通用框架,该框架可视作 a strong baseline for UDA ReID,在 GitHub repo 中也已一并开源
尽管该类方法可以一定程度上随着模型的优化改善伪标签质量,但是模型的训练往往被无法避免的伪标签噪声所干扰,并且在初始伪标签噪声较大的情况下,模型有较大的崩溃风险。所谓伪标签噪声主要来自于源域预训练的网络在目标域上有限的表现力、未知的目标域类别数、聚类算法本身的局限性等等。所以如何处理伪标签噪声对网络最终的性能产生了至关重要的影响,但现有方案并没有有效地解决它。
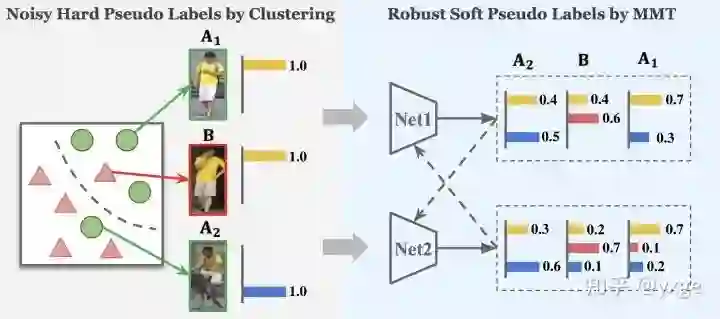
为了有效地解决基于聚类的算法中的伪标签噪声的问题,该文提出利用"同步平均教学"框架进行伪标签优化,核心思想是利用更为鲁棒的"软"标签对伪标签进行在线优化。在这里,"硬"标签指代置信度为 100% 的标签,如常用的 one-hot 标签 [0,1,0,0],而"软"标签指代置信度<100% 的标签,如 [0.1,0.6,0.2,0.1]。
如上图所示,A1 与 A2 为同一类,外貌相似的 B 实际为另一类,由于姿态多样性,聚类算法产生的伪标签错误地将 A1 与 B 分为一类,而将 A1 与 A2 分为不同类,使用错误的伪标签进行训练会造成误差的不断放大。该文指出,网络由于具备学习和捕获数据分布的能力,所以网络的输出本身就可以作为一种有效的监督。然而,利用网络的输出来训练自己是不可取的,会无法避免地造成误差的放大。所以该文提出同步训练对称的网络,在协同训练下达到相互监督的效果,从而避免对网络自身的输出误差形成过拟合。在实际操作中,该文利用"平均模型"进行监督,提供更为可信和稳定的"软"标签,将在下文进行描述。总的来说,该文
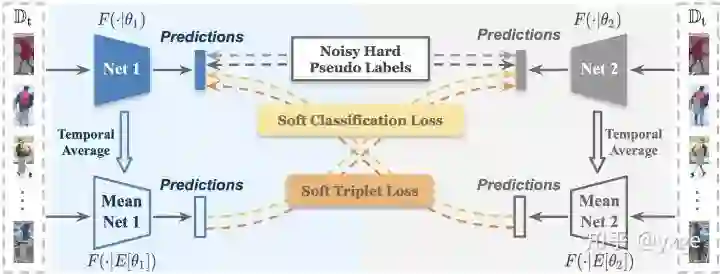
如上图所示,该文提出的「相互平均教学」框架利用离线优化的"硬"伪标签与在线优化的"软"伪标签进行联合训练。「硬」伪标签由聚类生成,在每个训练 epoch 前进行单独更新;「软」伪标签由协同训练的网络生成,随着网络的更新被在线优化。直观地来说,该框架利用同行网络(Peer Networks)的输出来减轻伪标签中的噪声,并利用该输出的互补性来优化彼此。而为了增强该互补性,主要采取以下措施:
对两个网络 Net 1 和 Net 2 使用不同的初始化参数;
随机产生不同干扰,例如,对输入两个网络的图像采用不同的随机增强方式,如随机裁剪、随机翻转、随机擦除等,对两个网络的输出特征采用随机 dropout;
训练 Net 1 和 Net 2 时采用不同的"软"监督,i.e. "软"标签来自对方网络的"平均模型";
采用网络的"平均模型"Mean-Net 1/2 而不是当前的网络本身 Net 1/2 进行相互监督。
此处,"平均模型"的参数 ![]() 是对应网络参数
是对应网络参数 ![]() 的累计平均值,具体来说,"平均模型"的参数不是由损失函数的反向传播来进行更新的,而是在每次损失函数的反向传播后,利用以下公式将对应的网络参数以
的累计平均值,具体来说,"平均模型"的参数不是由损失函数的反向传播来进行更新的,而是在每次损失函数的反向传播后,利用以下公式将对应的网络参数以 ![]() 进行加权平均:
这里,
进行加权平均:
这里,![]() 指第
指第 ![]() 个 iteration,
个 iteration,![]() 和
和 ![]() 分别为 Net 1 和 Net 2 的当前参数。在初始化时,
分别为 Net 1 和 Net 2 的当前参数。在初始化时,![]() ,
,![]() 。故「平均模型」可以看作对网络过去的参数进行平均,两个"平均模型"由于具有时间上的累积,解耦性更强,输出更加独立和互补。有一种简单的协同学习方案是将此处的「平均模型」去除,直接使用网络自己的输出去监督对称的网络,如利用 Net 1 的输出去监督 Net 2。而在这样的方案下存在两点弊端,(1) 由于网络本身靠反向传播参数更新较快,受噪声影响更严重,所以用这样不稳定的监督容易对网络的学习造成影响,文章 4.4 的消融学习中进行了比较,(2) 该简化方案让网络直接训练逼近彼此,会使得网络迅速收敛至相似,降低输出的互补性,文章附录 A.1 中进行了详细说明。值得注意的是,由于"平均模型"不会进行反向传播,所以不需要计算和存储梯度,并不会大规模增加显存和计算复杂度。在测试时,只使用其中一个网络进行推理,相比较 baseline,不会增加测试时的计算复杂度。
在行人重识别任务中,通常使用分类损失与三元损失进行联合训练以达到较好的精度。其中分类损失作用于分类器的预测值,而三元损失直接作用于图像特征。为了方便展示,下文中,我们使用
。故「平均模型」可以看作对网络过去的参数进行平均,两个"平均模型"由于具有时间上的累积,解耦性更强,输出更加独立和互补。有一种简单的协同学习方案是将此处的「平均模型」去除,直接使用网络自己的输出去监督对称的网络,如利用 Net 1 的输出去监督 Net 2。而在这样的方案下存在两点弊端,(1) 由于网络本身靠反向传播参数更新较快,受噪声影响更严重,所以用这样不稳定的监督容易对网络的学习造成影响,文章 4.4 的消融学习中进行了比较,(2) 该简化方案让网络直接训练逼近彼此,会使得网络迅速收敛至相似,降低输出的互补性,文章附录 A.1 中进行了详细说明。值得注意的是,由于"平均模型"不会进行反向传播,所以不需要计算和存储梯度,并不会大规模增加显存和计算复杂度。在测试时,只使用其中一个网络进行推理,相比较 baseline,不会增加测试时的计算复杂度。
在行人重识别任务中,通常使用分类损失与三元损失进行联合训练以达到较好的精度。其中分类损失作用于分类器的预测值,而三元损失直接作用于图像特征。为了方便展示,下文中,我们使用 ![]() 指代编码器,
指代编码器,![]() 指代分类器,每个 Net 都由一个编码器和一个分类器组成,我们用角标 1,2 来区分 Net 1 和 Net 2。我们使用角标 s,t 来区分源域和目标域,源域图像及其标签被表示为
指代分类器,每个 Net 都由一个编码器和一个分类器组成,我们用角标 1,2 来区分 Net 1 和 Net 2。我们使用角标 s,t 来区分源域和目标域,源域图像及其标签被表示为 ![]() ,目标域无标注的图像表示为
,目标域无标注的图像表示为 ![]() 。
利用「硬」伪标签进行监督时,分类损失可以用一般的多分类交叉熵损失函数
。
利用「硬」伪标签进行监督时,分类损失可以用一般的多分类交叉熵损失函数 ![]() 来表示:
上式中,
来表示:
上式中,![]() 为目标域图像
为目标域图像 ![]() 的「硬」伪标签,由聚类产生。在「相互平均教学」框架中,「软」分类损失中的「软」伪标签是「平均模型」Mean-Net 1/2 的分类预测值 [公式]。针对分类预测,很容易想到利用「软」交叉熵损失函数 [公式] 来进行监督,该损失函数被广泛应用于模型蒸馏,用以减小两个分布间的距离:
上式中
的「硬」伪标签,由聚类产生。在「相互平均教学」框架中,「软」分类损失中的「软」伪标签是「平均模型」Mean-Net 1/2 的分类预测值 [公式]。针对分类预测,很容易想到利用「软」交叉熵损失函数 [公式] 来进行监督,该损失函数被广泛应用于模型蒸馏,用以减小两个分布间的距离:
上式中 ![]() 和
和 ![]() 表示同一张图像经过不同的随机数据增强方式。该式旨在让 Net 1 的分类预测值逼近 Mean-Net 2 的分类预测值,让 Net 2 的分类预测值逼近 Mean-Net 1 的分类预测值。
传统的三元(anchor, positive, negative)损失函数表示为:
上式中
表示同一张图像经过不同的随机数据增强方式。该式旨在让 Net 1 的分类预测值逼近 Mean-Net 2 的分类预测值,让 Net 2 的分类预测值逼近 Mean-Net 1 的分类预测值。
传统的三元(anchor, positive, negative)损失函数表示为:
上式中 ![]() 表示欧氏距离,下角标
表示欧氏距离,下角标 ![]() 和
和 ![]() 分别表示
分别表示 ![]() 的正样本和负样本,
的正样本和负样本,![]() 是余量超参。这里,正负样本由聚类产生的伪标签判断,所以该式可以用以支持「硬」伪标签的训练。但是,不足以支持软标签的训练,减法形式的三元损失也无法直观地提供软标签。这里的难点在于,如何在三元组的图像特征基础上设计合理的「软」伪标签,以及如何设计对应的「软」三元损失函数。该文提出使用 softmax-triplet 来表示三元组内特征间的关系,表示为:
这里 softmax-triplet 的取值范围为
是余量超参。这里,正负样本由聚类产生的伪标签判断,所以该式可以用以支持「硬」伪标签的训练。但是,不足以支持软标签的训练,减法形式的三元损失也无法直观地提供软标签。这里的难点在于,如何在三元组的图像特征基础上设计合理的「软」伪标签,以及如何设计对应的「软」三元损失函数。该文提出使用 softmax-triplet 来表示三元组内特征间的关系,表示为:
这里 softmax-triplet 的取值范围为 ![]() ,可以用来替换传统的三元损失,当使用「硬」伪标签进行监督时,可以看作二分类问题,使用二元交叉熵损失函数
,可以用来替换传统的三元损失,当使用「硬」伪标签进行监督时,可以看作二分类问题,使用二元交叉熵损失函数 ![]() 进行训练:
这里的「1」指的是每个样本与其负样本的欧氏距离应该远远大于与正样本的欧氏距离。但由于伪标签存在噪声,并不能完全正确地区分正负样本,所以该文提出需要软化对三元组的监督(使用「平均模型」输出的特征距离比
进行训练:
这里的「1」指的是每个样本与其负样本的欧氏距离应该远远大于与正样本的欧氏距离。但由于伪标签存在噪声,并不能完全正确地区分正负样本,所以该文提出需要软化对三元组的监督(使用「平均模型」输出的特征距离比 ![]() 代替硬标签「1」,软化后标签取值范围在
代替硬标签「1」,软化后标签取值范围在 ![]() 之间)。具体来说,在「相互平均教学」框架中,「平均模型」编码的图像特征计算出的 softmax-triplet 可用作「软」伪标签以监督三元组的训练:
该损失函数旨在让 Net 1 输出的 softmax-triplet 逼近 Mean-Net 2 的 softmax-triplet 预测值,让 Net 2 输出的 softmax-triplet 逼近 Mean-Net 1 的 softmax-triplet 预测值。通过该损失函数的设计,该文有效地解决了传统三元损失函数无法支持"软"标签训练的局限性。「软」三元损失函数可以有效提升无监督领域自适应在行人重识别任务中的精度,实验详情参见原论文消融学习的对比实验。
该文提出的「相互平均教学」框架利用「硬」/「软」分类损失和「硬」/「软」三元损失联合训练,在每个训练 iteration 中,主要由三步组成:
之间)。具体来说,在「相互平均教学」框架中,「平均模型」编码的图像特征计算出的 softmax-triplet 可用作「软」伪标签以监督三元组的训练:
该损失函数旨在让 Net 1 输出的 softmax-triplet 逼近 Mean-Net 2 的 softmax-triplet 预测值,让 Net 2 输出的 softmax-triplet 逼近 Mean-Net 1 的 softmax-triplet 预测值。通过该损失函数的设计,该文有效地解决了传统三元损失函数无法支持"软"标签训练的局限性。「软」三元损失函数可以有效提升无监督领域自适应在行人重识别任务中的精度,实验详情参见原论文消融学习的对比实验。
该文提出的「相互平均教学」框架利用「硬」/「软」分类损失和「硬」/「软」三元损失联合训练,在每个训练 iteration 中,主要由三步组成:
通过「平均模型」计算分类预测和三元组特征的「软」伪标签;
通过损失函数的反向传播更新 Net 1 和 Net 2 的参数;
通过参数加权平均法更新 Mean-Net 1 和 Mean-Net 2 的参数。
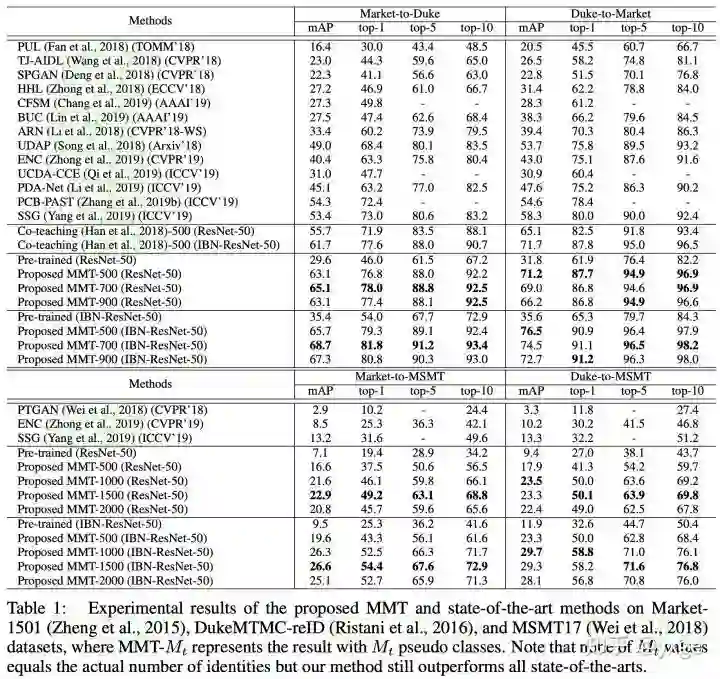
该文在四个行人重识别任务上进行了验证,精度均比现有最先进的方法 [2,3] 提升十个点以上,媲美有监督学习的性能。论文中使用 K-Means 聚类进行实验,在每个行人重识别任务中都对不同的伪类别数(表格中表示为「MMT-伪类别数」)进行了验证。发现无需设定特定的数目,均可获得最先进的结果。另外,开源的代码中包含了基于 DBSCAN 的实验脚本,可以进一步提升性能,感兴趣的同学可以尝试。论文中的消融研究有效证明了「相互平均教学」框架的设计有效性和可解释性,在这里就不细细展开了。
该文针对基于聚类的无监督领域自适应方法中无法避免的伪标签噪声问题展开了研究,提出使用「相互平均教学」框架在线生成并优化更为鲁棒和可信的「软」伪标签,并设计了针对三元组的合理伪标签以及对应的损失函数,在四个行人重识别任务中获得超出最先进算法 13%-18% 的精度。
参考内容:
[1] Y. Ge, et al. Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification. ICLR, 2020.
[2] X. Zhang, et al. Self-training with progressive augmentation for unsupervised cross-domain person re-identification. ICCV, 2019.
[3] F. Yang, et al. Self-similarity grouping: A simple unsupervised cross domain adaptation approach for person re-identification. ICCV, 2019.
原文链接:https://zhuanlan.zhihu.com/p/116074945?utm_source=wechat_session&utm_medium=social&utm_oi=41299705069568
本文为机器之心经授权发布,转载请联系原作者获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

 是对应网络参数
是对应网络参数  的累计平均值,具体来说,"平均模型"的参数不是由损失函数的反向传播来进行更新的,而是在每次损失函数的反向传播后,利用以下公式将对应的网络参数以
的累计平均值,具体来说,"平均模型"的参数不是由损失函数的反向传播来进行更新的,而是在每次损失函数的反向传播后,利用以下公式将对应的网络参数以  进行加权平均:
进行加权平均:

 指第
指第  个 iteration,
个 iteration, 和
和  分别为 Net 1 和 Net 2 的当前参数。在初始化时,
分别为 Net 1 和 Net 2 的当前参数。在初始化时, ,
, 。故「平均模型」可以看作对网络过去的参数进行平均,两个"平均模型"由于具有时间上的累积,解耦性更强,输出更加独立和互补。有一种简单的协同学习方案是将此处的「平均模型」去除,直接使用网络自己的输出去监督对称的网络,如利用 Net 1 的输出去监督 Net 2。而在这样的方案下存在两点弊端,(1) 由于网络本身靠反向传播参数更新较快,受噪声影响更严重,所以用这样不稳定的监督容易对网络的学习造成影响,文章 4.4 的消融学习中进行了比较,(2) 该简化方案让网络直接训练逼近彼此,会使得网络迅速收敛至相似,降低输出的互补性,文章附录 A.1 中进行了详细说明。值得注意的是,由于"平均模型"不会进行反向传播,所以不需要计算和存储梯度,并不会大规模增加显存和计算复杂度。在测试时,只使用其中一个网络进行推理,相比较 baseline,不会增加测试时的计算复杂度。
。故「平均模型」可以看作对网络过去的参数进行平均,两个"平均模型"由于具有时间上的累积,解耦性更强,输出更加独立和互补。有一种简单的协同学习方案是将此处的「平均模型」去除,直接使用网络自己的输出去监督对称的网络,如利用 Net 1 的输出去监督 Net 2。而在这样的方案下存在两点弊端,(1) 由于网络本身靠反向传播参数更新较快,受噪声影响更严重,所以用这样不稳定的监督容易对网络的学习造成影响,文章 4.4 的消融学习中进行了比较,(2) 该简化方案让网络直接训练逼近彼此,会使得网络迅速收敛至相似,降低输出的互补性,文章附录 A.1 中进行了详细说明。值得注意的是,由于"平均模型"不会进行反向传播,所以不需要计算和存储梯度,并不会大规模增加显存和计算复杂度。在测试时,只使用其中一个网络进行推理,相比较 baseline,不会增加测试时的计算复杂度。
 指代编码器,
指代编码器, 指代分类器,每个 Net 都由一个编码器和一个分类器组成,我们用角标 1,2 来区分 Net 1 和 Net 2。我们使用角标 s,t 来区分源域和目标域,源域图像及其标签被表示为
指代分类器,每个 Net 都由一个编码器和一个分类器组成,我们用角标 1,2 来区分 Net 1 和 Net 2。我们使用角标 s,t 来区分源域和目标域,源域图像及其标签被表示为  ,目标域无标注的图像表示为
,目标域无标注的图像表示为  。
。
 来表示:
来表示:

 为目标域图像
为目标域图像  的「硬」伪标签,由聚类产生。在「相互平均教学」框架中,「软」分类损失中的「软」伪标签是「平均模型」Mean-Net 1/2 的分类预测值 [公式]。针对分类预测,很容易想到利用「软」交叉熵损失函数 [公式] 来进行监督,该损失函数被广泛应用于模型蒸馏,用以减小两个分布间的距离:
的「硬」伪标签,由聚类产生。在「相互平均教学」框架中,「软」分类损失中的「软」伪标签是「平均模型」Mean-Net 1/2 的分类预测值 [公式]。针对分类预测,很容易想到利用「软」交叉熵损失函数 [公式] 来进行监督,该损失函数被广泛应用于模型蒸馏,用以减小两个分布间的距离:

 和
和  表示同一张图像经过不同的随机数据增强方式。该式旨在让 Net 1 的分类预测值逼近 Mean-Net 2 的分类预测值,让 Net 2 的分类预测值逼近 Mean-Net 1 的分类预测值。
表示同一张图像经过不同的随机数据增强方式。该式旨在让 Net 1 的分类预测值逼近 Mean-Net 2 的分类预测值,让 Net 2 的分类预测值逼近 Mean-Net 1 的分类预测值。

 表示欧氏距离,下角标
表示欧氏距离,下角标  和
和  分别表示
分别表示  是余量超参。这里,正负样本由聚类产生的伪标签判断,所以该式可以用以支持「硬」伪标签的训练。但是,不足以支持软标签的训练,减法形式的三元损失也无法直观地提供软标签。这里的难点在于,如何在三元组的图像特征基础上设计合理的「软」伪标签,以及如何设计对应的「软」三元损失函数。该文提出使用 softmax-triplet 来表示三元组内特征间的关系,表示为:
是余量超参。这里,正负样本由聚类产生的伪标签判断,所以该式可以用以支持「硬」伪标签的训练。但是,不足以支持软标签的训练,减法形式的三元损失也无法直观地提供软标签。这里的难点在于,如何在三元组的图像特征基础上设计合理的「软」伪标签,以及如何设计对应的「软」三元损失函数。该文提出使用 softmax-triplet 来表示三元组内特征间的关系,表示为:

 ,可以用来替换传统的三元损失,当使用「硬」伪标签进行监督时,可以看作二分类问题,使用二元交叉熵损失函数
,可以用来替换传统的三元损失,当使用「硬」伪标签进行监督时,可以看作二分类问题,使用二元交叉熵损失函数  进行训练:
进行训练:

 代替硬标签「1」,软化后标签取值范围在
代替硬标签「1」,软化后标签取值范围在