CCCF专栏 | 从2018年的戈登•贝尔奖说起
2018年11月16日,第三十届全球超级计算大会(SC18)在美国达拉斯落幕。会上揭晓了2018年戈登•贝尔奖(ACM Gordon Bell Prize)。异构架构在超算系统构建层面被广泛接受。人工智能应用有望成为超算的主流应用之一。

2018年11月16日,第三十届全球超级计算大会(SC18)在美国达拉斯落幕,美国两大国家实验室(美国能源部下属的橡树岭国家实验室和劳伦斯·利弗莫尔国家实验室)的新一代基于图形加速器的异构超级计算机位列TOP500[1]前两名,首个每秒百亿亿次(ExaOps)计算能力的基因组学计算应用与最大规模的深度学习应用双双摘得2018年戈登·贝尔奖(ACM Gordon Bell Prize)。
2018年顶级超级计算系统发展
表1中列出了2018年排名(2018年11月发布)TOP500榜单中TOP10超级计算机的具体信息,包括该机器在2017年的排名(2017年11月发布)、峰值性能、LINPACK效率、HPCG排名及其峰值效率、所采用的架构和加速器类型。从表中的数据可以看出:
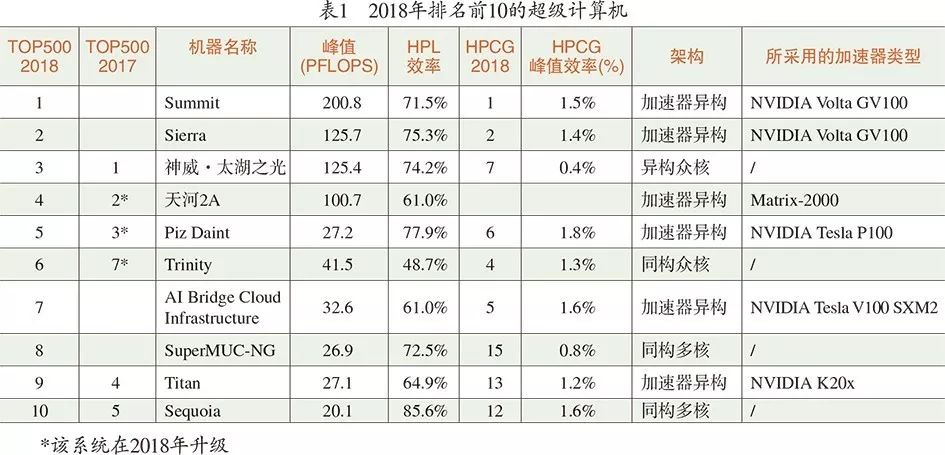
● 2018年TOP10超级计算机快速更新。与2017年相比,TOP10中增加了4个新系统,分别是Summit[2]、Sierra[2]、AI Bridge CloudInfrastructure(简称ABCI)和SuperMUC-NG;同时,3个2017年的TOP10系统得到进一步升级继续保持在TOP10之列。这也反映了目前应用对更高计算能力的迫切需求。
● 新一代基于图形加速器的异构超级计算机(Summit, Sierra, PizDaint)在LINPACK效率方面较上一代系统Titan有显著提升,LINPACK效率均超过70%。当前TOP10系统当中,LINPACK效率能与其媲美的仅有神威·太湖之光和两个同构多核系统SuperMUC-NG和Sequoia。
● 新一代顶级计算系统在稀疏问题求解效率方面有所进步。得益于持续的软硬件创新,TOP500性能最高的Summit和Sierra两个系统在HPCG测试中的效率并没有因大量使用图形加速硬件而明显下降,与新建的两个同构系统Trinity和SuperMUC-NG相比,其HPCG效率反而更高。最终,这两个新系统也在HPCG总性能的排名中取得前两名,超越之前多年在HPCG测试中领跑的京系统。这也使得大家对传统科学计算应用有效利用加速器异构架构有了更多信心。
● 基于图形加速器的异构架构在最新TOP10系统中已占据5席,成为目前构建顶级超算系统的主要方式之一。与前一代图形加速器异构系统Titan相比,美国国家实验室采用的新一代异构系统采用了高密度节点(一机多GPU卡)的设计,在功耗和节点数量方面有着明显优势,NVLink技术的引入缓解了节点内多个计算设备间数据传输能力不足的困境。
2018年戈登·贝尔奖入围工作
一年一度颁发的戈登·贝尔奖用于表彰世界范围内高性能计算的杰出成就,尤其是高性能计算应用于科学、工程和大规模数据分析领域的创新工作[3]。2018年入围最终评奖的工作一共有6项,分别来自不同领域,既有传统的科学计算应用,也有新兴的深度学习和图计算应用。其中,有5项均以TOP500最高性能机器Summit作为测试和优化平台,仅有1项围绕我国的神威·太湖之光展开。
持续峰值性能奖:应用超级计算机来应对药物流行病[4]
本次获得戈登·贝尔奖持续峰值性能奖的应用来自基因组学计算领域,由橡树岭国家实验室的研究团队领衔完成,是首个达到每秒钟百亿亿次计算能力的科学计算应用。该工作在橡树岭国家实验室的Summit上采用混合精度计算模式,峰值性能达到2.3 ExaOps。该研究是高性能计算与生物信息学、医学相结合的一个典范。
药物滥用是世界级难题。根据美国疾病控制和预防中心的统计,每天有115人死于阿片类(类鸦片)药物过度使用,而该问题还在持续恶化中。如何通过基因组学的分析来寻找致病原因并积极研制治疗方案迫在眉睫。橡树岭国家实验室的研究团队利用超级计算机Summit和Titan,开发了用于大规模上位基因组全关联研究和多效性研究的高性能计算工具CoMet。研究人员希望利用该工具,基于美国百万退伍军人计划收集的大量基因数据,通过对遗传过程的理解,尝试帮助解决长期慢性疼痛和阿片类药物上瘾问题。
CoMet的核心操作是特定的相似性计算与相关系数计算,以向量比较操作为核心。该工作通过将向量比较操作转化为负载均衡的大规模分布式稠密线性代数操作,达到最佳利用异构计算资源的目的。同时,针对大规模和采用高密度节点的并行环境,该团队还设计了“计算-节点内传输-通信重叠”的计算通信模式,最终在Summit上取得了98%的弱可扩展性测试结果,相关系数计算达到2.3 ExaOps的计算性能,与以往工作相比取得了4~5个数量级的性能提升,实现了每秒接近30亿亿个比较计算。尽管CoMet达到了每秒E级计算次数,但仍不能算是传统意义上的仅考虑双精度浮点运算性能的E级应用,其性能指标计算所采用的总操作数同时包括了整型运算指令、浮点运算指令、位操作指令以及精度转换指令。
可扩展性与时效奖:利用高可扩展深度学习方法理解极端天气事件[5]
本次获得戈登·贝尔奖可扩展性与时效奖的应用来自气候变化研究领域,由劳伦斯伯克利国家实验室和NVIDIA公司的联合研究团队完成,是首个可以有效扩展到27360块GPU加速卡的深度学习应用,其半精度计算的峰值性能也达到每秒钟百亿亿次,成功提升了气候变化研究人员在高分辨率气候模拟数据集中有效识别极端天气模式的能力。
科学大数据分析,特别是针对高分辨率海量科学仿真数据的分析,是科学计算与人工智能技术相结合的机会,也是超算的核心应用之一。该研究团队尝试解决大规模深度神经网络训练过程中的共性计算问题,提出了面向异构超算上大规模深度学习训练过程的整体优化方案,重点解决了已有Tensorflow系统在IO、数据载入和通信优化等方面适应异构超算过程中出现的性能问题,以及现有深度学习算法在可扩展性上面临的困难。
利用Summit全机系统,该团队借鉴图像识别最新深度学习网络,完成了高分辨率大气模式(全球25km水平分辨率)输出结果(数十TB)的深度神经网络高效训练,半精度计算持续性能接近每秒钟百亿亿次,可有效识别极端天气事件空间结构。值得指出的是,该工作采用数据并行思想,使用更多的计算资源导致更大的批尺寸(batch size),大规模并行时可获得的收敛速度和精度成为关键。遗憾的是,可能是由于机时受限,获奖论文仅给出了1024节点(每节点1500文件)的收敛性分析结果。
国内团队入围应用:“神图”图计算框架[6]
此次入围戈登·贝尔奖唯一来自中国的应用是名为“神图”的图数据分析编程系统。“神图”所面向的对象不是传统的科学与工程计算应用,而是探索了在超级计算机上如何开展极大规模图数据的高效处理。图数据将数据抽象成点和边的数据形式,是一种典型的非结构化数据。图数据分析是大数据分析中的重要内容,在金融反欺诈、物联网管理、信息安全、网页搜索、社交网络分析、电网分析等领域具有广泛的应用前景。
“神图”基于神威·太湖之光超级计算机,针对极大规模随机通信、图结构的分布不均衡以及异构结点功能映射等问题,提出了中继消息聚合与路由、分化消息传播技术以及无锁数据分发技术等方法,有效利用了神威·太湖之光全机的处理能力和通信能力,能够高效扩展到全机千万核规模,在国际上首次实现了对包含4万亿个结点、70万亿条边的合成图的快速分析,每一轮PageRank算法的时间只需要半分钟。在应用方面,对于搜狗公司提供的12万亿条边的真实中文网页图,“神图”完成一轮PageRank算法仅需8.5秒。与文献中报道的业界最先进系统相比,处理规模增加了一个数量级,同时,处理性能提高了超过一个数量级,实现了图计算节点规模、图数据规模、运行时间上的突破。
“神图”系统并不是一个特定的应用程序,而是一个编程框架,为用户在神威·太湖之光超级计算机上编写多种图计算应用提供了极大的便利。一个基于“神图”的图分析算法通常只需要数十行代码即可完成原先需要编写近万行代码才能实现的图数据处理功能,大大提高了开发效率。
此项工作的研究单位是清华大学、北京费马科技有限公司、卡塔尔计算研究所、数学工程与先进计算国家重点实验室、苏黎世联邦理工学院、国家并行计算机工程技术研究中心、北京搜狗科技发展有限公司和国家超级计算无锡中心等。
其他入围应用
另外三个戈登·贝尔奖入围应用也各具特色,分别在量子色动力学模拟、城市震害模拟和电子显微镜数据处理的高效异构计算上取得了突破。
量子色动力学模拟项目[7]属于传统的科学计算领域,其性能优化对Summit和Sierra的高密度节点配置做了深入考虑,主要关注三方面问题:(1)高密度节点的CPU开销最小化。CPU资源是高密度节点处理能力的短板,因而节点内数据传输和网络通信尽可能少占用CPU资源成为提升应用性能的关键之一;(2)通信策略和通信参数自动调优,高密度节点配置使得节点内不同设备间数据传输存在新的优化空间;(3)并发任务的最优调度,发掘多任务在同一节点内并发执行的可能性。上述工作均基于已有软件框架进行拓展实现,与图形加速器异构架构性能优化方面的长期投入与积累密不可分。该工作也从侧面说明了从关注单一应用到关注整个应用工作流的重要性和必要性。
城市震害模拟项目[8]关注的是非结构有限元计算中的大规模线性方程组求解问题。与已有工作不同的是,该工作在预处理中对难收敛区域引入局部操作来加速收敛,并引入混合精度计算来充分发挥GPU计算资源效能。对于时变计算问题中难收敛区域的识别更是采用了人工神经网络来预测,这也是人工智能技术在传统计算中应用的一个有趣实例。
电子显微镜数据处理项目[9]同样关注深度学习的大规模训练问题。其不同之处是采用了类似AutoML(谷歌在2017年创建的一个能够制造神经网络的AI系统)的思想,将深度神经网络结构优选和超参调优合并来考虑。由于利用遗传算法来进行网络优选,在传统的数据并行和模型并行的基础上开发了新的并行机会,可以更好地利用超大规模计算系统。该项目也有望推动实现全自动训练,并最终大幅加速训练过程和有效改进训练效果。
超级计算机与应用发展趋势
2018年超算领域在体系结构和应用方面的进步可圈可点,呈现两个重要趋势,一是异构架构在超算系统构建层面被广泛接受,二是人工智能应用有望成为超算的主流应用之一。
异构架构在超算系统构建层面被广泛接受
目前的TOP10系统中异构超算占据七成。其中,NVIDIA GPU构建的异构超算系统占5席。而且,随着人工智能技术在科学与工程计算中越来越广泛的应用,支持高性能张量计算的图形加速器硬件还可能越来越多地受到超算中心决策者的青睐。特别需要指出的是,该架构最初作为应对功耗墙挑战的一种可行方案起步,其构建的超算系统历经TSUBAME系列机、天河1A、Titan到如今的Summit已经有10年时间,从最初在应用移植优化方面饱受质疑到现在已经初步兼具功耗和性能优势,体现了高性能计算社区,特别是美国在这个方向上坚持投入,在应用、算法、软件和硬件等方面持续协同创新的成果[10]。从事核能研究为主,关注传统科学计算应用的美国劳伦斯·利佛莫尔国家实验室从上一代同构系统Sequoia转而采购图形加速器异构系统Sierra,也是对这一成果的重要认可。
在GPU加速器之外,异构系统天河2A选用Matrix-2000作为加速计算设备,NEC的SX-AURORA TSUBASA[11]选用向量处理单元作为加速器,相关技术的未来走向值得关注。
在同一芯片中集成不同计算核心的异构众核架构同样值得期待。该架构已经在我国的神威·太湖之光系统中实现并被证明有效。美国CORAL计划(the Collaboration of Oak Ridge,Argonne and Livermore)所支持的第一台E级系统Aurora(预计2021年前后建成)也将采用类似架构。
目前看来,异构架构已经成为构建顶级超算系统的大势所趋,加速器异构还是异构众核,争论仍将继续。
人工智能应用有望成为超算的主流应用之一
算力一直被认为是人工智能再次起飞的重要基础之一。随着深度神经网络规模的扩大,最新的网络生成和训练往往需要数万GPU小时(如BERT, NASNet等)甚至更多。具有顶级计算能力的超算系统理应为大规模人工智能应用提供助力,不断拓展后者的技术边界。2018年的戈登·贝尔奖选择大规模深度学习应用,入围应用中人工智能相关的项目也前所未有地占据了半壁江山,这一切都预示着人工智能与超算的结合将愈来愈紧密。
目前真正具有高可扩展能力的人工智能算法与应用并不多。以应用最为广泛的深度学习为例,增大批尺寸来提升数据并行性有可能导致收敛问题,从而限制可利用的并行资源总量,而模型并行又存在通信瓶颈。因此,人工智能应用仍需要持续创新以更好地利用未来更大规模的超算系统。而最新出现的进化神经网络方法就是在该方向上努力的成果之一,其相比现有的深度强化学习方法更具扩展性,也更具充分利用超算资源的潜力。美国橡树岭国家实验室基于异构超算系统开发出的多节点深度学习进化神经网络(Multi-node Evolutionary Neural Networks for Deep Learning, MENNDL)能够通过遗传算法进行网络拓扑与超参数优化,以自动生成优化神经网络,上文提到入围今年戈登·贝尔奖的电子显微镜数据处理项目[9]就是MENNDL的一个应用示例。
可以预见,更好地将人工智能技术与已有科学规律结合,创新科学发现方法和科学计算模型,会为构建未来超算应用和研发高可扩展并行系统创造新的契机。
总结与展望
极大规模超级计算机的研制必须要回答的问题是:研制这么大的超级计算机有什么用处? 更大规模的计算机是否能够通过更大内存和更强的计算能力解决关键应用挑战,完成从“不能”到“能”的突破,从而为社会提供与其投入相匹配的回报?戈登·贝尔奖的设置为我们回答这个问题提供了一个窗口,可以看到在传统的基于数值模拟的科学计算应用之外,本次入围应用在人工智能、大数据处理等方面探索了新的方向。
我国在过去的三届戈登·贝尔奖评选中,以神威·太湖之光计算机为载体的应用共获得6项入围,2项得奖的好成绩,说明我国在超算系统研制取得突破的基础上,我国的高性能计算算法和应用研究者有能力开展世界最前沿的研究工作。
更进一步,我们认为获奖本身不是目的,我们希望能够超越戈登·贝尔奖,以科技进步和民生服务为目标,推动高性能计算应用和系统研发的广泛使用。例如我国获奖的高精度天气预报算法,能否尽快转化为实用的数值天气预报应用,提高天气预报的时效性和准确性,为减灾防灾做出切实的贡献?我们在此呼吁,科技部门应对相关领域给予长期稳定的支持,促进应用研发与系统研制的交互引领,形成正反馈机制,促进我国的超级计算领域健康持续发展。
作者介绍
郑纬民

•CCF会士、CCF 前理事长。
•清华大学教授
•并行/分布处理、网络存 储器等

薛 巍

•CCF高级会员、信息存储技术专委会委员。
•清华大学副教授。
•主要研究方向为大规模科学计算。
陈文光

•CCF副秘书长、理事。
•清华大学教授,兼任青海大学计算机系主任。
•主要研究方向为并行计算的编程模型、并行化编译和应用分析。
参考文献
[1] https://www.top500.org,2018.11.
[2] SudharshanS Vazhkudai, Bronis R de Supinski, Arthur S Bland, et al. The design,deployment, and evaluation of the CORAL pre-exascale systems[C]//The InternationalConference for High Performance Computing, Networking, Storage, and Analysis.2018.
[3] GordonBell, David Bailey, Alan H. Karp, et al. A look back on 30 years of the GordonBell Prize[J]. International Journal of High Performance Computing Applications,2017, 31(6): 469-484.
[4] JoubertW, Weighill D, Kainer D, et al. Attacking the opioid epidemic: Determining theepistatic and pleiotropic genetic architectures for chronic pain and opioidaddiction[C]// The International Conference for High Performance Computing,Networking, Storage, and Analysis. 2018.
[5] KurthT, Treichler S, Romero J, et al. Exascale deep learning for climateanalytics[C]// The International Conference for High Performance Computing,Networking, Storage, and Analysis. 2018.
[6] Lin H,Liu X, Zheng W, et al. Processing Multi-Trillion Edge Graphs on Millions ofCores in Seconds[C]//The International Conference for High PerformanceComputing, Networking, Storage, and Analysis. 2018.
[7] BerkowitzE, Clark M A, Gambhir A, et al. Simulating the weak death of the neutron in afemtoscale universe with near-exascale computing[C]//The InternationalConference for High Performance Computing, Networking, Storage, and Analysis.2018.
[8] TsuyoshiIchimura, Kohei Fujita, Takuma Yamaguchi et al. A fast scalable implicit solverfor nonlinear time-evolution earthquake city problem on low-orderedunstructured finite elements with artificial intelligence and transprecisioncomputing[C]//The International Conference for High Performance Computing,Networking, Storage, and Analysis. 2018.
[9] Robert M. Patton, Maxim A. Ziatdinov,Sergei V. Kalinin, et al. 167-PFlops deep learning for electron microscopy:From learning physics to atomic manipulation[C]//The International Conferencefor High Performance Computing, Networking, Storage, and Analysis. 2018.
[10] Joubert W, Archibald R, Berrill M, etal. Accelerated application development: The ORNL Titan experience[J]. Comput.Electr. Eng., 2015, 46(5):123-138.
[11] Kazuhiko Komatsu, Shintaro Momose, YokoIsobe, et al. Performance evaluation of a vector supercomputer SX-AuroraTSUBASA[C]//The International Conference for High Performance Computing,Networking, Storage, and Analysis. 2018.
中国计算机学会

长按识别二维码关注我们
CCF推荐
【精品文章】
点击“阅读原文”,加入CCF。


