社区分享 | TensorFlow Lite C++ API 开源案例教程

文 / 本文来自社区投稿与征集,作者:胡旭华,Google Developers Expert。
本文转自:https://github.com/SunAriesCN
前言
众所周知,C/C++ 语言具备很强可移植性,作为高级的底层语言能兼容各式各样的系统环境或应用。因此很多企业更偏向于将算法用 C/C++ 实现,从而减少不同业务平台下的算法维护成本。所以,我们对 TensorFlow Lite 的 C++ 接口有很强的现实需求。然而,关于 TensorFlow Lite C++ 接口的详细教程和案例不太常见,但它实际上并不复杂。因而,我参考 MediaPipe 整理一个案例项目分享到社区,希望能帮助有需要的同学。
项目地址:
https://github.com/SunAriesCN/image-classifier参考
https://github.com/google/mediapipe
编译构建
我们创建一个 C++ 项目后,一般会先考虑编译环境的搭建问题。
Bazel 是一个类似 Make、Maven 和 Gradle 的构建与测试工具。它的高级构建语言具有很好的可读性。Bazel 支持多语言跨平台的构建项目。它还支持大量用户协作开发涵盖多个代码仓库的大型代码库。它具有构建语言可读性强、构建高速可靠、跨平台兼容、大规模构建和扩展构建等优点。因此,我们这个项目采用 Bazel 作为构建工具,方便 TensorFlow Lite 与 OpenCV 等第三方库的代码版本管理。首先,我们一起了解一下如何用 Bazel 构建 C++ 项目。
设置构建环境
-
WORKSPACE,它一般被放在项目的根目录底下,负责导入第三方库的代码控制与管理。 BUILD,通常一个项目有很多个,它们负责告诉 Bazel 如何编译项目的各个不同模块。通常,构建环境下的每个模块包 (Package) 目录下都会有一个 BUILD。
下面是我们案例项目的目录结构:
image-classifier
├── LICENSE
├── README.md
├── WORKSPACE
├── image_classifier
│ ├── BUILD
│ ├── apps
│ │ ├── desktop
│ │ │ ├── BUILD
│ │ │ └── main.cc
│ └── cc
│ ├── BUILD
│ ├── classifier_float_mobilenet.cc
│ ├── classifier_float_mobilenet.h
│ ├── image_classifier.cc
│ ├── image_classifier.h
│ ├── image_classify_service.cc
│ ├── image_classify_service.h
│ └── utils.h
└── third_party
├── BUILD
├── com_google_absl_f863b622fe13612433fdf43f76547d5edda0c93001.diff
├── opencv_linux.BUILD
├── opencv_macos.BUILD
└── org_tensorflow_compatibility_fixes.diff
我们将项目划分成两个模块,第三方库 third_party 和图像分类模块 image_classifier,其中 image_classifier 又分成 apps 应用模块和 cc 代码实现模块。每模块的具体设计后文详细介绍,我们先看看构建环境的细节配置。
workspace(name = "image_classifier")
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
skylib_version = "0.9.0"
http_archive(
name = "bazel_skylib",
type = "tar.gz",
url = "https://github.com/bazelbuild/bazel-skylib/releases/download/{}/bazel_skylib-{}.tar.gz".format (skylib_version, skylib_version),
sha256 = "1dde365491125a3db70731e25658dfdd3bc5dbdfd11b840b3e987ecf043c7ca0",
)
load("@bazel_skylib//lib:versions.bzl", "versions")
versions.check(minimum_bazel_version = "2.0.0")
# ABSL cpp library lts_2020_02_25
http_archive(
name = "com_google_absl",
urls = [
"https://github.com/abseil/abseil-cpp/archive/20200225.tar.gz",
],
# Remove after https://github.com/abseil/abseil-cpp/issues/326 is solved.
patches = [
"@//third_party:com_google_absl_f863b622fe13612433fdf43f76547d5edda0c93001.diff"
],
patch_args = [
"-p1",
],
strip_prefix = "abseil-cpp-20200225",
sha256 = "728a813291bdec2aa46eab8356ace9f75ac2ed9dfe2df5ab603c4e6c09f1c353"
)
new_local_repository(
name = "linux_opencv",
path = "/usr",
build_file="@//third_party:opencv_linux.BUILD"
)
new_local_repository(
name = "macos_opencv",
build_file = "@//third_party:opencv_macos.BUILD",
path = "/usr",
)
# Needed by TensorFlow
http_archive(
name = "io_bazel_rules_closure",
sha256 = "e0a111000aeed2051f29fcc7a3f83be3ad8c6c93c186e64beb1ad313f0c7f9f9",
strip_prefix = "rules_closure-cf1e44edb908e9616030cc83d085989b8e6cd6df",
urls = [
"http://mirror.tensorflow.org/github.com/bazelbuild/rules_closure/archive/cf1e44edb908e9616030cc83d085989b8e6cd6df.tar.gz",
"https://github.com/bazelbuild/rules_closure/archive/cf1e44edb908e9616030cc83d085989b8e6cd6df.tar.gz", # 2019-04-04
],
)
#Tensorflow repo should always go after the other external dependencies.
# 2020-08-30
_TENSORFLOW_GIT_COMMIT = "57b009e31e59bd1a7ae85ef8c0232ed86c9b71db"
_TENSORFLOW_SHA256= "de7f5f06204e057383028c7e53f3b352cdf85b3a40981b1a770c9a415a792c0e"
http_archive(
name = "org_tensorflow",
urls = [
"https://github.com/tensorflow/tensorflow/archive/%s.tar.gz" % _TENSORFLOW_GIT_COMMIT,
],
patches = [
"@//third_party:org_tensorflow_compatibility_fixes.diff",
],
patch_args = [
"-p1",
],
strip_prefix = "tensorflow-%s" % _TENSORFLOW_GIT_COMMIT,
sha256 = _TENSORFLOW_SHA256,
)
load("@org_tensorflow//tensorflow:workspace.bzl", "tf_workspace")
tf_workspace(tf_repo_name = "org_tensorflow")
上面是 image-classifier 的 WORKSPACE 配置,他导入 versions 对象检查 Bazel 版本,加载 http_archive 函数管理 org_tensorflow、opencv、abseil 等类似的第三方库。其中 abseil 库很值得推荐,它是集成不少 C++14/17 新特性的工具库,类似于 Boost 却体积特别轻巧方便。我们经常会在 Google 开源代码中看见它们的身影,如 absl::make_unique,absl::StrJoin 等等,因此我把这个项目引入到代码里方便一些字符串和智能指针的处理。
接着,我们看看不同目录下的 BUILD 文件是如何配置的。
image_classifier/apps/desktop/BUILD
cc_binary(
name = "image_classifier.exe",
srcs = ["main.cc"],
deps = [
"@//third_party:opencv",
"//image_classifier/cc:image_classifier",
],
)
我们看到 image_classifier/apps/desktop/BUILD 正在描述一个可执行文件的编译依赖关系。其中,cc_binary 就表示编译的输出结果是二进制可执行文件,name 表示这个输出文件的名字,srcs 是可执行文件编译时依赖的一些源文件,deps 是指编译链接过程中依赖的其他模块目录。我们很容易观察出,这个目录的 BUILD 其实描述的是一个桌面应用的主函数编译过程,毕竟 srcs 依赖了一个 apps/desktop/main.cc (码农们的命名习惯)。另外,还可以看到 deps 的依赖表里面的 "@//third_party:opencv" 比 "//image_classifier/cc:image_classifier" 多了一个 @ 符号,它表示外部第三方库的依赖。而 "//image_classifier/cc:image_classifier" 表示我们从目录 image_classifier/cc 引用 image_classifier 模块。
image_classifier 模块的 BUILD 描述如下:
image_classifier/cc/BUILD
cc_library(
name = "image_classifier",
srcs = glob(["*.cc"]),
hdrs = glob(["*.h"]),
visibility = ["//visibility:public"],
deps = [
"@com_google_absl//absl/memory",
"@org_tensorflow//tensorflow/lite:builtin_op_data",
"@org_tensorflow//tensorflow/lite/kernels:builtin_ops",
"@org_tensorflow//tensorflow/lite:framework",
"@//third_party:opencv",
],
)
image_classifier/cc/BUILD 正在描述一个 C++ 库文件的编译依赖关系。很容易注意到,这个 BUILD 文件与前面都写区别。首先,我用 cc_library 函数告诉 Bazel 这个目录的编译输出的结果是一个库文件。其次,我用 glob 函数实现对 image_classifier/cc/ 目录下所有 .cc 和 .h 文件进行依赖,hdrs 表示需要依赖包含的头文件。然后,我通过 visiblity 属性对外部模块公开 API 的细节,方便 apps/desktop 等其他模块的调用,具体细节可以参考 Bazel 的编译规则说明。最后,不难发现我的 deps 引用了 TensorFlow Lite 的关键模块,因为 TensorFlow Lite 在我的案例项目中属于外部第三方库,所以关键模块的路径前面有一个 @ 符号。
Bazel 的编译规则说明
https://docs.bazel.build/versions/3.6.0/be/c-cpp.html
构建环境搭建完成后,我们就可以运行 Bazel 进行项目的编译构建。
$ bazel build -c opt --experimental_repo_remote_exec //image_classifier/apps/desktop:image_classifier.exe
其中 -c opt 表示 C 的编译优化,--experimental_repo_remote_exec 仅为处理第三方库的编译问题。最后,以 MacOS 为例,我们可以执行这个二进制可执行文件。
$ ./bazel-bin/image_classifier/apps/desktop/image_classifier.exe
如果有同学在构建过程中遇到问题,请到 Issue 反馈你构建的情况。
代码结构
我们结合目录结构和构建文件配置,分析源码可以得到下面的代码结构示意图。
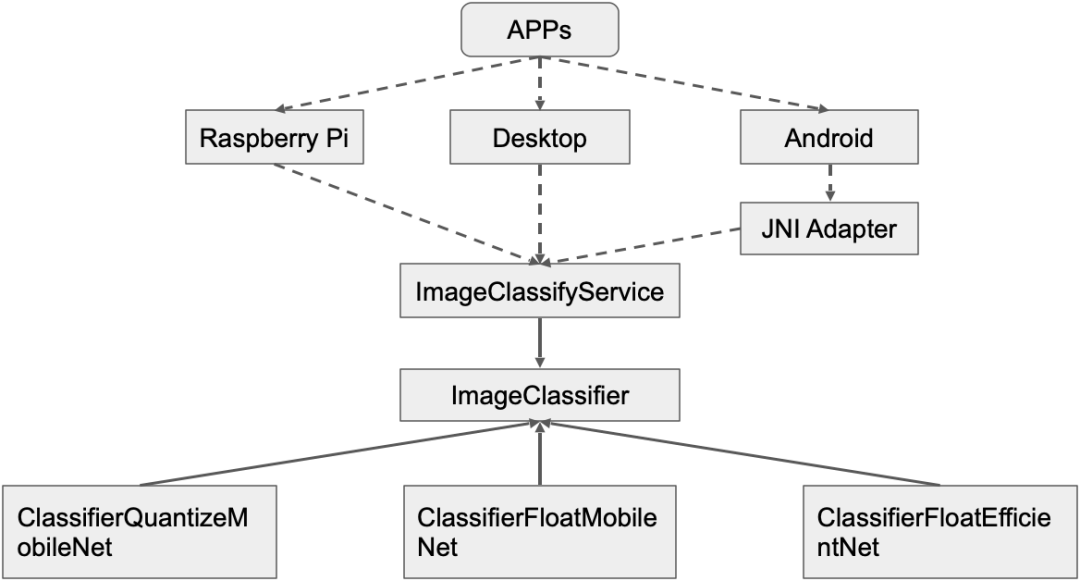
这是案例项目的代码结构设计,在企业开发中我们总是希望自己的算法代码无须修改即可跨平台复用,减少维护成本,但算法的实现却总会不断地被优化。因此,我设计一个 ImageClassifyService 作为业务算法代理提供服务,不同平台的 APP 开发者根据需求平台的情况在接口适配层调用这个代理为应用提供接口。比如,Android 平台的开发者可以在 JNI 层调用 C++ 类 ImageClassifyService 的 RecognizeImage 接口封装图像分类识别的功能给 Java 层使用。一般这种情况,我会把 ImageClassifyService 设计成单例方便管理,毕竟移动端资源紧张,不会同时运行两个分类服务。哪怕出现墨菲定律的情况,我们也应该修改 ImageClassifyService,让他提供两个适合同时分类服务的接口。但是,这对于一个入门教程案例来说过于复杂,所以我没在案例代码做类似的实现。
然后,ImageClassifyService 有一个 ImageClassifier 抽象成员负责完成具体的分类任务。前面说过,具体的图像分类实现会经常被修改优化,甚至会做 A/B 测试。因此,我沿用 TFLite Android 官方案例的设计模式,让 ImageClassifier 组合不同的实现,如 ClassifierFloatMobileNet,ClassifierEfficientNet 等。
TFLite Android 官方案例
https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android
模型分析
因为我们正在开发的 C++ 项目与深度学习有关,所以我们很难避免模型在不同推理框架的转换问题。然而,本教程主要目的是 TensorFlow Lite C++ 部署流程说明,因此我不在本文详细描述模型的转换方法,有需要的读者可以参考官方文档。我的案例模型是从 TFLite Android 官方示例程序拷贝的,部署前我习惯于对准备使用的模型进行观察分析,以便关注到一些模型的输入预处理和输出后处理的注意事项。TFLite 的模型分析工具有 visualize 和 minimal,其中 visualize 是官方主推的分析工具,能图示模型的推理流程。而 minimal 作为 TFLite 的 Examples 也能显示 TFLite 模型的详情信息,但是无模型图示。
官方文档
https://tensorflow.google.cn/lite/convert?hl=zh_cnTFLite Android 官方示例程序
https://github.com/tensorflow/examples/tree/master/lite/examples/image_classification/android
Examples
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/examples/minimal
Interpreter has 103 tensors and 31 nodes
Inputs: 87
Outputs: 86
Tensor 0 MobilenetV1/Conv2d_0/weights kTfLiteFloat32 kTfLiteMmapRo 3456 bytes ( 0.0 MB) 32 3 3 3
Tensor 1 MobilenetV1/Conv2d_10_depthwise/depthwise_weights kTfLiteFloat32 kTfLiteMmapRo 18432 bytes ( 0.0 MB) 1 3 3 512
Tensor 2 MobilenetV1/Conv2d_10_pointwise/weights kTfLiteFloat32 kTfLiteMmapRo 1048576 bytes ( 1.0 MB) 512 1 1 512
...
Tensor 84 MobilenetV1/MobilenetV1/Conv2d_9_pointwise/Conv2D_bias kTfLiteFloat32 kTfLiteMmapRo 2048 bytes ( 0.0 MB) 512
Tensor 85 MobilenetV1/MobilenetV1/Conv2d_9_pointwise/Relu6 kTfLiteFloat32 kTfLiteArenaRw 401408 bytes ( 0.4 MB) 1 14 14 512
Tensor 86 MobilenetV1/Predictions/Reshape_1 kTfLiteFloat32 kTfLiteArenaRw 4004 bytes ( 0.0 MB) 1 1001
Tensor 87 input kTfLiteFloat32 kTfLiteArenaRw 602112 bytes ( 0.6 MB) 1 224 224 3
Tensor 88 (null) kTfLiteFloat32 kTfLiteArenaRwPersistent 3456 bytes ( 0.0 MB) 27 32
Tensor 89 (null) kTfLiteFloat32 kTfLiteArenaRwPersistent 8192 bytes ( 0.0 MB) 32 64
...Tensor 102 (null) kTfLiteFloat32 kTfLiteArenaRwPersistent 4100096 bytes ( 3.9 MB) 1024 1001
上面的 MobileNetV1 模型,我们可以看到它有 102 个张量 (tensor),其中 15 个中间特征映射 (Feature Map) 张量没有节点名字 (Node Name) 而不可见。我们分析模型的输入输出张量,Tensor 87 和 Tensor 86。这个 MobileNetV1 的张量索引 (Tensor Index) 比较独特,它的输入张量索引为 87 与输出索引的 86 邻近,张量索引其实只是 TensorFlow Lite 对模型参数和中间特征映射的内存进行编号标记,方便在 AllocateTensors 安排模型执行顺序时找到对应的张量。另外,我们还能看到这两个输入输出内存的 Memory 类型都是 kTfLiteArenaRw,它表示内存可读写。有的模型参数的 Memory 类型是 kTfLiteMmapRo 是只读内存,一般我们代码无法访问。还有的是 kTfLiteDynamic 类型,它会根据输入情况动态调整内存大小,我只在 ResizeOp 遇到过这种类型。有时 ResizeOp 的输出张量大小 (Size) 是固定 kTfLiteMmapRo 的,动态修改 ResizeOp 的输入大小会导致 AllocateTensors 分配内存不对的情况。关于这个 ResizeOp Dynamic Shape 的问题,我们将在后文详细讨论。现在,我们基本清楚 MobileNetV1 的 tflite 模型细节,下面我们看看如何利用这些模型细节进行推理实现图像分类算法。
算法实现
在了解模型细节信息后,我们就可以按照下面的基本流程实现算法的部署。
// minimal.cc 官方案例实现
// Load model
std::unique_ptr<tflite::FlatBufferModel> model =
tflite::FlatBufferModel::BuildFromFile(filename);
TFLITE_MINIMAL_CHECK(model != nullptr);
// Build the interpreter with the InterpreterBuilder.
// Note: all Interpreters should be built with the InterpreterBuilder,
// which allocates memory for the Intrepter and does various set up
// tasks so that the Interpreter can read the provided model.
tflite::ops::builtin::BuiltinOpResolver resolver;
tflite::InterpreterBuilder builder(*model, resolver);
std::unique_ptr<tflite::Interpreter> interpreter;
builder(&interpreter);
TFLITE_MINIMAL_CHECK(interpreter != nullptr);
// Allocate tensor buffers.
TFLITE_MINIMAL_CHECK(interpreter->AllocateTensors() == kTfLiteOk);
printf("=== Pre-invoke Interpreter State ===\n");
// This line can print the details of tflite model from interpreter.
tflite::PrintInterpreterState(interpreter.get());
// Fill input buffers
// TODO(user): Insert code to fill input tensors.
// Note: The buffer of the input tensor with index `i` of type T can
// be accessed with `T* input = interpreter->typed_input_tensor<T>(i);`
// Run inference
TFLITE_MINIMAL_CHECK(interpreter->Invoke() == kTfLiteOk);
printf("\n\n=== Post-invoke Interpreter State ===\n");
tflite::PrintInterpreterState(interpreter.get());
// Read output buffers
// TODO(user): Insert getting data out code.
// Note: The buffer of the output tensor with index `i` of type T can
// be accessed with `T* output = interpreter->typed_output_tensor<T>(i);`
官方文档
https://tensorflow.google.cn/lite/guide/ops_custom?hl=zh_cn
2. 分配张量推理运行内存 (Allocate tensor buffers),因为大多情况下深度学习模型的运行内存消耗都比较固定,所以提前计算分配有利于减少动态内存分配的资源消耗。然而,有时候我们会遇到类似人脸识别、文本识别等后级网络模型的输入图像的数量并不确定的情况,毕竟检测器能从图像定位多少个目标与场景有关,场景包含目标的个数是随机的。这时,我们可以利用 ResizeInputTensor 设置输入 batch size。代码片段如下:
// kInputIndex 是输入张量索引,kNum 是输入图片张数,即 batch size。
interpreter_->ResizeInputTensor(kInputIndex, {kNum, kInputHeight, kInputWidth, kInputChannels});
// 按照新的输入张量的大小重新分配内存。
interpreter_->AllocateTensors();
// 循环填充输入张量的内存,其中 kInputIndex 是输入张量索引。
float* input_buffer = interpreter_-> typed_tensor<float>(kInputIndex);
const int kInputBytes = sizeof(float)*kInputWidth*kInputHeight*kInputChannels;
cv::Size input_buffer_size(kInputWidth, kInputHeight);
int buffer_index = 0;
for(auto& image : images) {
cv::Mat input_image;
// 输入预处理操作。
cv::resize(image, input_image, input_buffer_size);
cv::cvtColor(input_image, input_image, cv::COLOR_BGR2GRAY);
input_image.convertTo(input_image, CV_32F, 2.f/255, -0.5);
// 填充输入张量的内存,batch size > 1 时,注意
// input_buffer 的数据类型需要强制转换。因为 buffer_index 是按 byte 为单位进行地址偏移的。
memcpy((uchar*)(input_buffer)+ buffer_index, input_image.data, kInputBytes);
buffer_index += kInputBytes;
}
3. 将输入数据填入输入张量。一般我们会在这步做一些数据预处理操作比如白化、数据类型转换等。如果是多图片同时预测的情况,可以参考上面的代码片段。
4. 运行深度学习网络模型推断过程,这时候只用简单调用 Interpreter::Invoke 接口,检查是否有返回错误即可。
5. 如果模型推断过程没有发生错误,那么网络模型的推断结果就会被放到 Interpreter 的输出张量上。我们只需要读取并按照业务逻辑进行后处理解析,就能得到期望的业务结果。
值得注意的是,ResizeInputTensor,AllocateTensors,Invoke 都是有返回值可以检查的,我建议尽量不要直接用默认的 assert 断言处理。因为我在 MacOS 用 Bazel 构建时,发现 assert(interpreter_->AllocateTensors()) 竟然没有执行,这可能是 Bazel 构建程序时会默认屏蔽 assert 断言,具体情况请感兴趣的同学自行研究,所以我教程案例中写了一个 CHECK 宏函数处理这个问题。
另外,我们还需要注意 Interpreter::typed_tensor 与 Interpreter::typed_input_tensor 的细微差别,他们的输入参数虽然都是索引 (Index),但是 typed_tensor 的参数是张量索引,而 typed_input_tensor 是输入张量的序号,比如 MobileNetV1 模型的输入张量索引是 87 但序号是 0,假如我不小心错写成 float* input_buffer = interpreter_ -> typed_input_tensor<float>( interpreter_ -> inputs()[0] ),此时我们往 input_buffer 进行内存拷贝,就会出现内存写入错误的问题。因为,我们正在写的这个内存属性可能已经不是可读写的了。同理,typed_output_tensor 也需要关注类似的问题。
最后,我们讨论一下关于 ResizeOp 的问题。前文提到, AllocateTensor 有时无法正确推理 ResizeOp 的输出结果大小 (Size),从而导致内存错误的情况。发生该问题的主要原因是,模型转换器 (TFLite Converter) 一般会认为 ResizeOp 的输出大小 (Size) 是常量,并在转换过程对其常量化,导致缩放算子输出大小固定 (Fixed ResizeOp Output Size) 的情况。对于这个问题,我们讨论下面两种解决思路。
首先,我们考虑修改模型转换部分的 Python 代码,用 tf.shape 获取输入张量的大小,从而动态控制 ResizeOp 的缩放比例,实现对其输出结果大小的修改。代码片段大致如下:
import tensorflow.compat.v1 as tf
import numpy as np
tf.disable_v2_behavior()
input_t = tf.placeholder(dtype=tf.float32, shape=[1, None, None, 3])
shape = tf.shape(input_t)
h = shape[1] // 2
w = shape[2] // 2
out_t = tf.compat.v1.image.resize_bilinear(input_t, [h, w])
with tf.Session() as sess:
converter = tf.lite.TFLiteConverter(sess.graph_def, [input_t], [out_t])
tfl_model = converter.convert()
interpreter = tf.lite.Interpreter(model_content=tfl_model)
input_index = (interpreter.get_input_details()[0]['index'])
interpreter.resize_tensor_input(input_index, tensor_size=[1, 300, 300, 3])
try:
interpreter.allocate_tensors()
except ValueError:
assert False
random_input = np.array(np.random.random([1, 300, 300, 3]), dtype=np.float32)
interpreter.set_tensor(input_index, random_input)
interpreter.invoke()
output_index = (interpreter.get_output_details()[0]['index'])
result = interpreter.get_tensor(output_index)
print(result.shape)
从上面的代码片段,我们只要修改 resize_tensor_input 的 tensor_size,result.shape 就是它的 0.5 倍。
另外,我们还可以考虑在模型转换时配置适合的输入大小,然后在预处理做一些 Crop-Padding-Resize 的操作,最后对模型的输出结果按照 Reisze 的比例进行解析得到我们期望的结果。具体的操作流程与原理如下图所示:
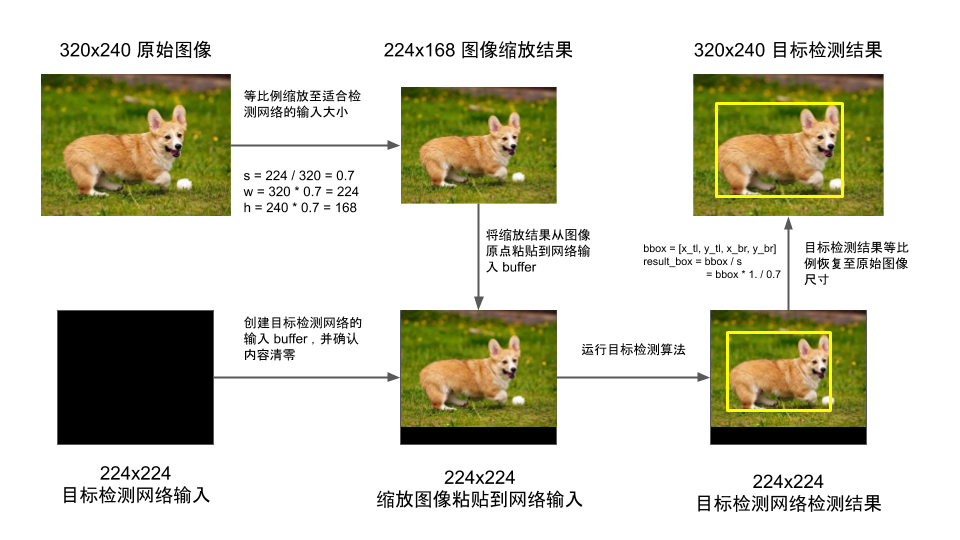
深度学习模型在训练阶段其实也是通过预处理固定输入大小的,因此推理阶段使用原有的输入大小其实并不会引入太多的误差。
TensorFlow Lite 现在也开始逐渐支持 Dynamic Shape ,同时也有一些修改 tflite::Interpreter 的模型信息的 Hack 技巧,这里我不一一介绍了,有兴趣可以关注我知乎的其他文章。
知乎
https://www.zhihu.com/people/hu-xu-hua-4
效果展现


可以看到我的教程案例效果与官方教程的效果基本一致。
未来的工作
有些同学可能发现我并没有把代码类图结构中的 Raspberry Pi 和 Android 部分进行实现。实际上,我只完成了 TFLite C++ API 应用的主干流程。因此,我仍需努力完成 Raspberry Pi 的编译支持与 Android 的应用层案例实现。而且,Tensorflow Lite 团队最近又推出了能减少开发工作量的新特性——Tensorflow Lite Library Task API,现在这一新特性在 tflite-support 的项目里面与 Android TFLite metadata 代码生成器放在一起。
tflite-support
https://github.com/tensorflow/tflite-support
所以,我希望未来能在这个教程案例项目集成类似 TFLite-support 的新特性帮助大家节省工作量。另外,这个案例代码只有 TFLite 算子的标准 C++ 实现,并未涉及 GPU 与 SIMD 等指令集优化的 TFLite Delegate API 应用。尽管这些算子指令优化受限于移动设备的访存带宽影响,未必达到显著优化效果,但我相信随着硬件设备与软件框架的更新迭代,这些问题终将被一一解决。
这个教程案例
http://github.com/SunAriesCN/image-classifierTFLite Delegate API
https://tensorflow.google.cn/lite/performance/delegates
这个开源的教程案例项目现在可能并不完美,毕竟我的个人的时间和能力都相当有限。然而,我期望这个项目最终能帮助各位开发者在人工智能时代展现出自身优势,应用开发者做有趣好玩的智能应用,架构性能优化师能让用户体验流畅的智能交互,算法研发人员能带来各种奇妙的黑科技等等。所以,如果你有兴趣参与到这个开发项目中,请不要犹豫的留言联系我,一起为人工智能努力吧!!
留言联系
https://github.com/SunAriesCN/image-classifier/issues/1


如果您想在 TensorFlow 社区分享经验与用例,点击 “阅读原文” 填写相关信息,我们会尽快与您联系。





