演讲实录丨吴家祥:PocketFlow--赋能移动端AI 应用开发
5月25日-26日,由中国人工智能学会主办,南京市麒麟科技创新园管理委员会与京东云共同承办的2019全球人工智能技术大会(2019 GAITC)在南京紫金山庄成功举行。
在第二天的人工智能开放平台与产业发展论坛上,腾讯AI Lab 高级研究员吴家祥发表了主题为《PocketFlow--赋能移动端AI 应用开发》的精彩演讲。

吴家祥
腾讯AI Lab 高级研究员
以下是吴家祥的演讲实录:
我的报告主要分为三个部分,首先介绍移动端 AI 生态,包括硬件的芯片、软件的框架和算法、应用;然后介绍 PocketFlow框架;最后部分如何基于 PocketFlow 框架,赋能移动端 AI 应用开发。
一、移动端AI生态
1. 目前移动端 AI 生态发展状况
在以往的很多移动端 AI 应用场景中,考虑到计算资源的限制,我们会把大量计算放在服务器端,移动端只做少量计算,但实际上这样做问题很多。
第一,比如用相机拍照,用户对实时性的要求非常高,不希望有明显的延迟,我们希望在移动端本地做处理。
第二,在涉及语音的实时交互场景,例如车载导航,如果把语音交互放到本地,它的反馈速度会非常快,对用户来说感受也更好一些。
第三,现在很多人家里有智能家居,它可能会需要收集并分析你的日常行为或者健康检测数据 , 很多人考虑到隐私问题,并不希望分享这部分数据,我们可以把它放在本地去做。
第四,考虑网络情况比较差的或者没有网络的地方,比如出国旅游,如果在这种情况下做准确的离线翻译,用户使用起来很方便。
第五,可以在很大程度上降低运维成本,避免繁复的服务器端开发工作。
因此,从整体上来看,做移动端 AI 生态开发是有必要的,它有很好的应用价值。
2. 移动端 AI 发展状况
从四个方面分析。第一是硬件,包括通用型的和 AI 专用的芯片;第二是框架;第三是更加精简的网络结构;第四是模型压缩,给定一个模型,我们可以对它做权重稀疏化或者还是低秩分解,都可以保证这个模型在识别精度不变的情况,大幅度降低其计算开销,提升整体运行速度,提升用户使用体验。总之,这四个方面促进了移动端 AI的开发。我们希望提出更高效的,或者更方便使用的模型压缩工具,对于不太了解 AI专业知识的移动应用开发者,可以借助我们的工具,可以快速地把模型应用到移动端。
二、PocketFlow框架
PocketFlow 框架有哪些功能,怎样去使用它。首先看传统的收集数据到训练模型,以及实际使用的过程,比如人脸识别需要大量的人脸标注数据,这里涉及到如何高效地训练模型,以及在训练结束后如何使用该模型。对于移动端应用场景,传统做法中需要把数据传到服务器端处理后再传回来,这里涉及网络传输和数据隐私等因素,并不是一个最优的解决方案,因此我们提出可以基于 PocketFlow 框架首先对模型进行压缩,得到一个更为高效的模型之后,再直接将该模型部署到移动端上。
PocketFlow 的整体设计框架为:① 用户提供原始模型以及自定义的压缩偏好,比如用户希望是一个体积更小的模型,还是运行速度更快的模型,这会反映到最终得到的压缩后模型的具体性能。② 得到这些信息,我们会提供很多模型压缩方法,从不同层面降低计算复杂度,基于特定的模型压缩算法训练原始模型,使它更高效。③ 为了提高模型的训练效率,我们提供了基于数据的快速训练、完整训练和网络蒸馏训练、多机多卡分布式训练。最后,因为移动应用开发者不一定很了解底层的 AI 算法细节,对于模型压缩过程中的超参数,可能选择不好,我们会基于 AutoML 方法,对超参数进行自动优化,最终得到一个计算更为高效的模型,提供给移动端的应用开发者,这样他就可以把模型直接部署到移动设备上,比如智能手机或者监控摄像头。
PocketFlow 目前已经集成了一些压缩算法,包括几种通道剪枝算法,对移动端部署没有特殊要求,不需要专门定制硬件支持。此外还支持对模型权重进行稀疏化或者定点量化,从而使得模型更小,传输更快。
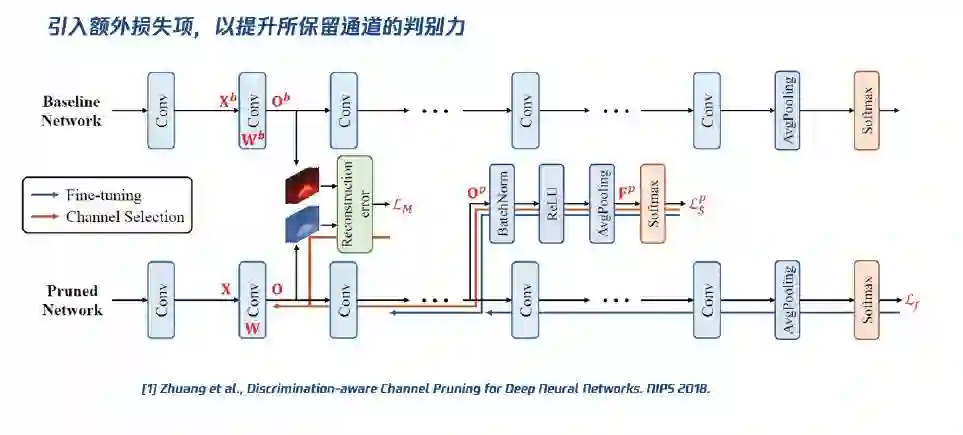
接下来,我们简单介绍这些模型压缩算法是怎样提高模型的计算效率的。第一,对通道剪枝,我们希望以更少的通道数量,最小化特征图重构损失 / 分类损失,因为如果可以保证这两个损失很小,就可以在一定程度上压缩之后的模型很大程度上接近原始模型。这是去年我们对通道剪枝做的改进,通过引入额外损失项,我们可以有效提升所保留通道的判别力(见下图)。第二,做权重稀疏化,因为很多神经网络模型中其实是有较大程度的冗余性的,去掉这部分冗余的模型参数对最终结果影响很小,而模型尺寸就可以大大降低。第三,做权重量化,我们既可以基于 PocketFlow均匀量化,也可以做非均匀量化,均匀量化就是有 N 个均匀分布的量化点,基于这种量化可以把浮点运算转换为更高效的定点运算;而非均匀量化则可以提供更高的量化自由度,从而达到更高的压缩比例。
PocketFlow 的一个主要出发点是希望降低移动端应用开发者进行 AI 应用开发时的成本。具体来说,我们通过 AutoML 以及强化学习等方法,可以对模型压缩算法中的超参数进行自动优化,在得到一个压缩好的模型后,我们可以对它进行性能评估,包括运行精度和运行效率等方面。评估结果会反馈到超参数优化模块中,从而在下一轮迭代中,选择更优的超参数组合,以期得到精度更高,计算更快的压缩模型。
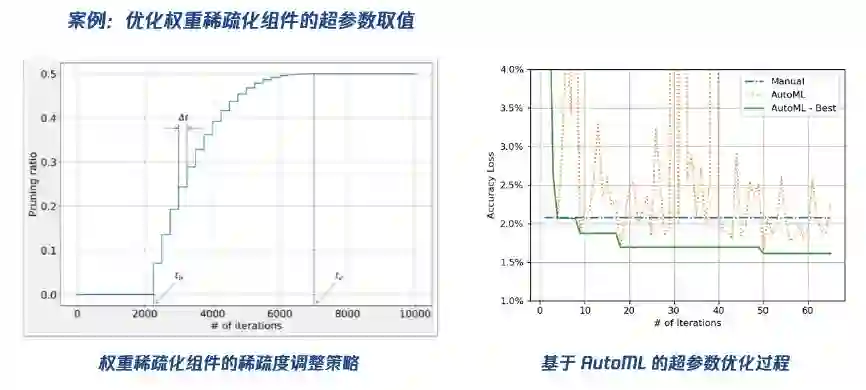
下面给出了一个具体的实验对比结果,我们通过 AutoML 算法,自动地选择权重稀疏化组建中的几个超参数取值组合。我们当然也可以基于过往经验去选择,但是需要一定的专业知识,并且可能会很耗时,因此希望这个过程可以更加自动化。从下图中可以看到,我们基于 AutoML 算法大约是在第 10 次迭代中就可以达到比手工调参更好的结果。
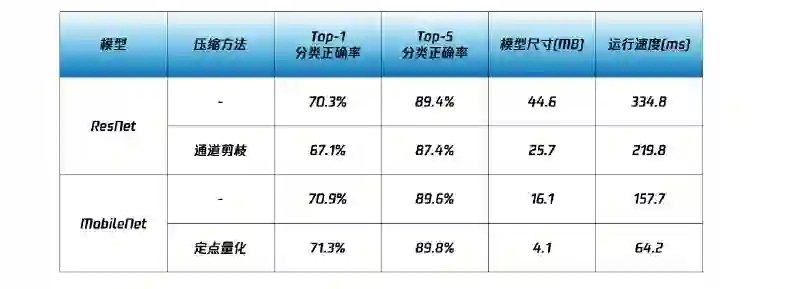
接下来,我们给出经 PocketFlow 压缩后的模型在移动端的实际运行效率对比,从下表中可以看到,对于 ResNet 模型,我们能把运行时间从原来的 334 ms 降到现在的 220 ms 左右,相当于把运行时间降低到原来的 60%~70%,精度损失大约为两个百分点;MobileNet 模型尺寸可以降低到原来的四分之一,精度方面相对于原始模型甚至还有小幅度的提升。
最后我们介绍几个 PocketFlow 在移动端场景下的实际应用案例。
第一个是对美颜相机中的人脸关键点定位模块进行优化。通过该模块,我们可以从人脸图像中准确地识别出 100 多个关键点的位置,从而对面部图像进行美化和修饰,提升视觉效果。我们通过通道剪枝方法对这其中的模型进行压缩,在非常精简的网络结构上仍能加速 40%~90%。
第二个应用案例是关于人体姿态识别的,也就是对人体四肢的各个关键性的骨骼点进行定位。基于我们的 PocektFlow 框架,可以在精度损失不影响使用体验情况下达到 3.5 倍的加速效果。
(本报告根据速记整理)
CAAI原创 丨 作者吴家祥
未经授权严禁转载及翻译
如需转载合作请向学会或本人申请
转发请注明转自中国人工智能学会





