干货 | 用于深度强化学习的结构化控制网络(ICML 论文讲解)

本文为 AI 研习社编译的技术博客,原标题 :
Structured Control Nets for Deep Reinforcement Learning Tutorial (ICML Published Long Talk Paper)
作者 | Mario Srouji
翻译 | 永恒如新的日常、召唤神龙
校对 | 斯蒂芬·二狗子 审核 | 酱番梨 整理 | 立鱼王
原文链接:
https://medium.com/@mariosrouji/structured-control-nets-for-deep-reinforcement-learning-tutorial-icml-published-long-talk-paper-2ff99a73c8b

摘要:近年来,深度强化学习在解决序列决策的几个重要基准问题方面取得了令人瞩目的进展。许多控制应用程序使用通用多层感知器(MLP),用于策略网络的非视觉部分。在本工作中,我们为策略网络表示提出了一种新的神经网络架构,该架构简单而有效。所提出的结构化控制网(Structured Control Net ,SCN)将通用多层感知器MLP分成两个独立的子模块:非线性控制模块和线性控制模块。直观地,非线性控制用于前视角和全局控制,而线性控制围绕全局控制以外的局部动态变量的稳定。我们假设这这种方法具有线性和非线性策略的优点:可以提高训练效率、最终的奖励得分,以及保证学习策略的泛化性能,同时只需要较小的网络并可以使用不同的通用训练方法。我们通过OpenAI MuJoCo,Roboschool,Atari和定制的2维城市驾驶环境的模拟验证了我们的假设的正确性,其中包括多种泛化性测试,使用多种黑盒和策略梯度训练方法进行训练。通过将特定问题的先验结合到架构中,所提出的架构有可能改进更广泛的控制任务。我们采用生物中心模拟生成器(CPG)作为非线性控制模块部分的结构来研究运动任务这个案例,结果了表面的该运动任务的性能被极大提高。
介绍
在本教程中,我想介绍一下我们在ICML上发表的工作中提出的结构化控制网络的简单实现,并在最后展示了案例研究的介绍。 我鼓励您在完成本教程之前先阅读本文。
这项工作是我在Apple AI Research实习时完成的,是我实习工作的一部分,击败了众多强化学习控制环境中最先进的技术,包括MuJoCo,Roboschool,Atari,OpenAI Gym,甚至自动驾驶。 我们计划将这项工作扩展到包含机器人环境和高级操作。
以下是该论文的一些结果。 在采样效率,最终奖励和鲁棒性方面,我们击败了当前在众多环境中最先进的MLP网络。 此外,我将通过一个研究案例,逐步展示如何根据特定任务量身定制结构化控制网络模型,以进一步提高性能!
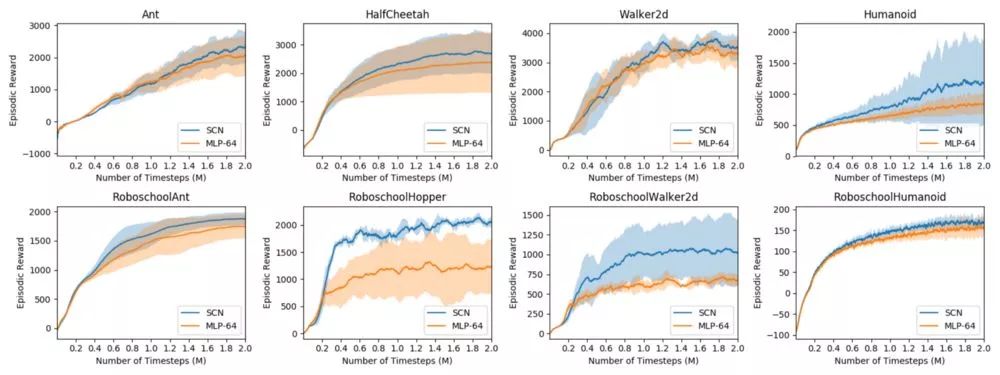
使用PPO作为训练算法,训练结构化控制网络(蓝色)与多层感知器(橙色),在2M时间步长time steps下的训练曲线。与现有的先进技术相比,我们在最终奖励和采样效率方面都显示出了显着的提高。
我希望这个介绍能够解开您复现本工作时遇到的困惑,并为该领域的深入研究提供良好的开端。 我将略过底层的细节,正如文中所述。 让我们开始吧!
问题描述
我们在标准的强化学习设置中描述问题。 在t时刻,智能体根据策略π(在我们的设置中,该策略是结构化控制网络),在给定当前观测序列o的情况下选择动作a。 r为该环境中提供的奖励,并返回下一个状态。
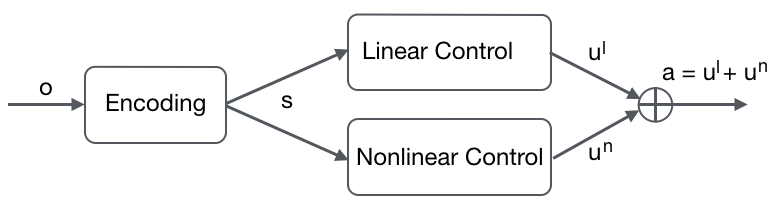
结构化控制网络体系结构
该架构概述非常简单; 它从环境中获取状态编码并将其提供给两个独立的流:线性控制流和非线性控制流。 这两个流可以被视为独立的子策略,其输出被融合为强化学习的策略网络。
此体系结构概述的目的是证明这两个模块可以使用策略实现,这些策略在策略网络上强制执行特定于任务的先验条件,以更好地提高采样效率和最终性能。
线性控制
在实现中,线性控制器由K * s + b表示,其中,K是学习的线性控制增益矩阵,b是学习的偏置(s是当前状态)。
要实现线性控制器,这里给出了模型设置的代码片段。 input_size是抽象状态向量的大小,而output_size是特定环境的动作向量的大小。 我将以OpenAI Gym的walker2d环境为例。 这里的偏置b被忽略(仅使用增益矩阵K)。
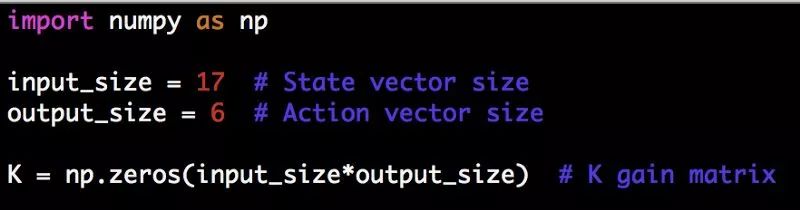
当你设置好增益矩阵K,就可以使用任何强化学习训练算法来学习权重(为简单起见,权重被初始化为0)。 增益矩阵K在环境的每个完整迭代之后更新,甚至可以使用延迟更新(例如每10次迭代进行一次更新)。 我将使用Evolutionary Strategies作为本教程中的训练算法。
以下示例代码段给出如何得到线性模块的动作输出。 这里介绍一个辅助函数,用于剪切输出操作向量以保持在环境的定义范围内(对于walker2d,这是[-1,1])。
生成动作输出的线性模块(U_l):

我将K增益矩阵向量调整为(input_size x output_size)大小的矩阵。 转置这个结果矩阵产生动作矩阵,大小为(output_size x input_size。)。这个动作矩阵乘以(input_size x 1)大小的状态向量后,可以得到一个(output_size x 1).大小的动作输出向量。
然后,您可以根据从环境接收的奖励信号更新K向量。 这就是线性控制的全部内容!
非线性控制
在本文的大部分实验中,我们使用一个简单的多层感知器(MLP)作为非线性控制模块。与线性控制类似,MLP的权值在每一个完整的episode中得到更新。
本文主要使用有两个隐藏层的MLP模型,其中每个隐藏层有16个隐藏单元,并使用tanh非线性作为激活函数。当使用ES作为训练算法时,由于训练算法固有的随机性,MLP是直接输出动作向量。而当采用PPO训练时,输出是一个具有可变标准差的高斯分布的均值。
为了简单起见,我不展示MLP的设置。您可以使用任何ML框架(TensorFlow、PyTorch等)来创建MLP模型本身。我们使用OpenAI 作为我们的训练算法和模型: https://github.com/openai/baselines. 。
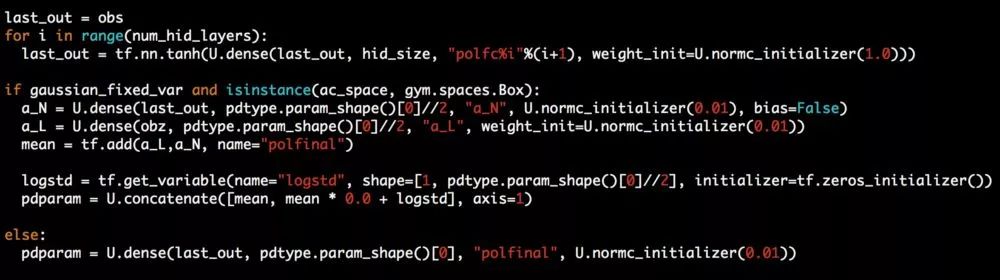
以下是在使用TensorFlow (tf) 无视觉输入的环境中使用的SCN的模型设置代码片段:
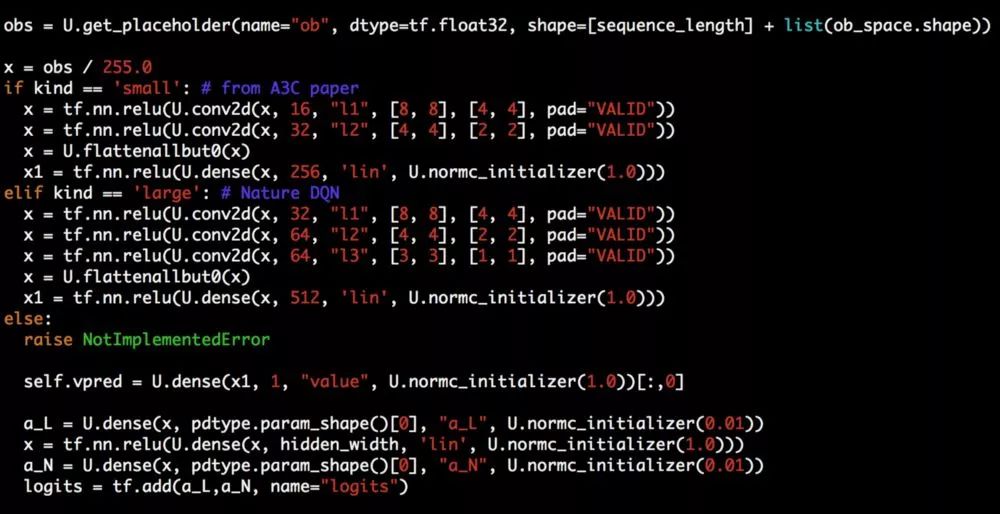
以下是使用Atari的卷积神经网络进行视觉输入的SCN模型设置的代码片段:
合并输出
当你获取了线性项和非线性项的输出后,对这两项的简单相加成为结构控制网络的输出。
当使用进化策略作为训练算法时,将输出合并就像将线性和非线性分量相加一样简单,可以直接产生输出动作(由于ES的固有随机性和无梯度算法的特性)。
当使用PPO或任何其他策略梯度训练算法时,请参考非线性部分中上面的代码片段,以了解输出是如何连接/添加在一起的。
案例研究:用一个特定运动的先验模型替换非线性模块中的MLP
在我们的最后一组实验中,我们使用动态腿移动作为一个案例研究来演示如何使用特定于任务的先验来定制SCN以适应特定的任务。
我们用一个中央模式生成器(CPG)的模拟代替了MLP来充当非线性模块。这种CPG模拟对于具有重复/循环运动类型(如散步、游泳、跳跃等)的任务非常有效。
在自然界中,用于运动的神经控制器具有特定的结构,称为中央模式发生器(Central Pattern generator, CPGs),这是一种能够产生协调节奏模式的神经回路。虽然一般前馈MLP网络很难学习节律运动,但通过使用傅立叶级数模拟生物CPGs并训练傅立叶系数,我们能够提高这些任务的最终性能和采样效率。
因此,非线性项为:
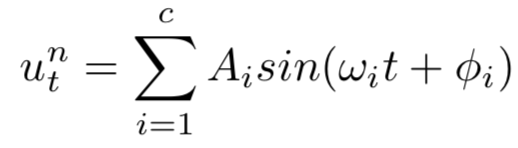
需要马上注意的是:我们不将状态作为输入提供给CPG仿真器。利用ES作为训练算法,我们可以非常有效地在没有状态信号的情况下对正弦信号进行调优。状态通过如上所示的线性控制项输入,然后根据SCN准则与CPG输出相结合。
在我们的实现中,我们学习了16个正弦波的振幅、频率和相位(对应于动作输出向量中的每个值)。动作输出是将所有16个正弦输出组合在一起形成非线性项。
让我们用python来完成这个模型的设置。
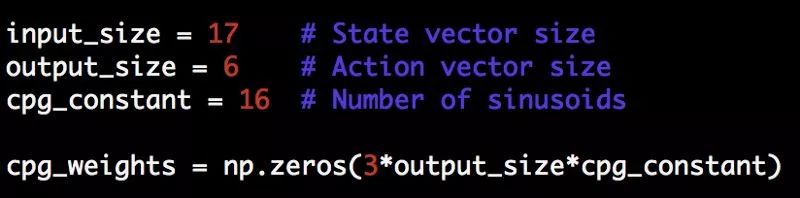
这里设置cpg_weights大小,对于每个正弦曲线的振幅、频率和相位都是设为3倍,而这里的output_size是下一个动作的向量大小(因为我们在这个状态下不再输入)。
我将重用helper函数来在界限内裁剪操作。让我们再添加一些函数来计算正弦输出(我将在下面解释它们的用法):
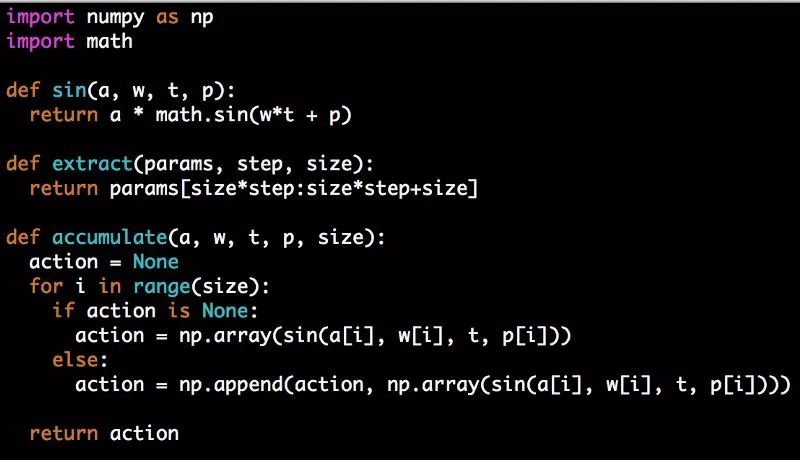
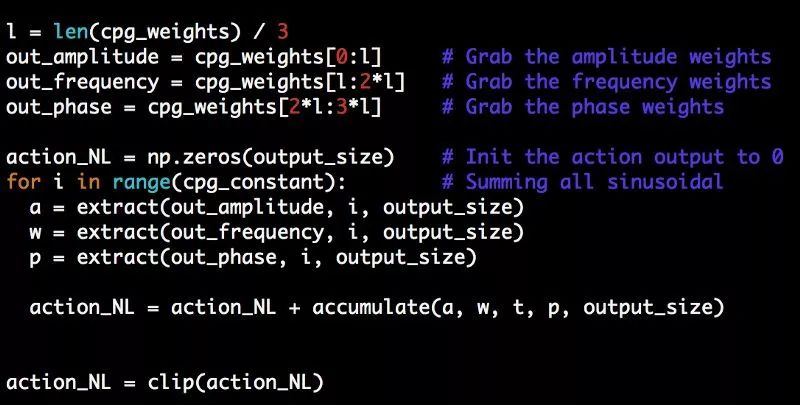
花一分钟来消化代码。本质上,这里所发生的是,对于output_size向量中的每个动作值,我们通过提取输入到正弦波中的振幅、频率和相位来产生正弦输出。我们对操作向量中的所有output_size项执行此操作,对于每个迭代,将所有cpg_constant迭代组合在一起(因此在我们的示例中,对每个操作项值将16个正弦输出相加)。最后,我们将输出向量与线性控制项相同地裁剪,然后根据SCN将这两项相加。
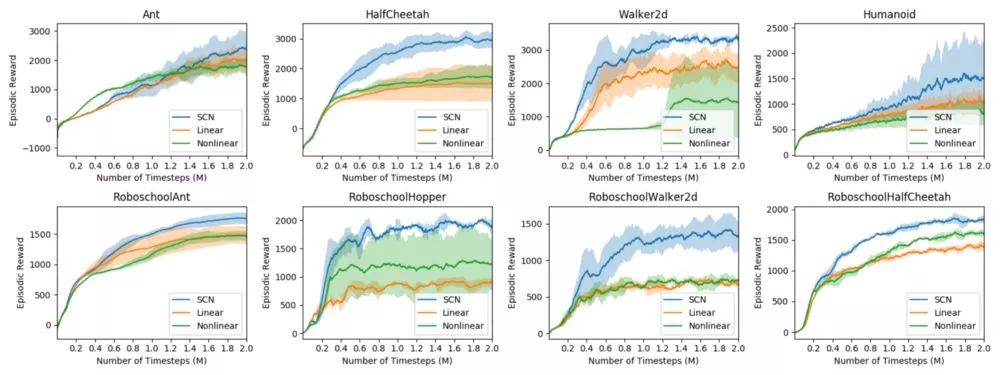
这种相当简单的方法在非线性项上优于MLP,在机车任务(如walker2d、swimmer、Ant等)上有显著的优势,因为它能够将这种有节奏的特定于任务的先验施加在结构化控制网络上。这里再次对性能进行了改进!
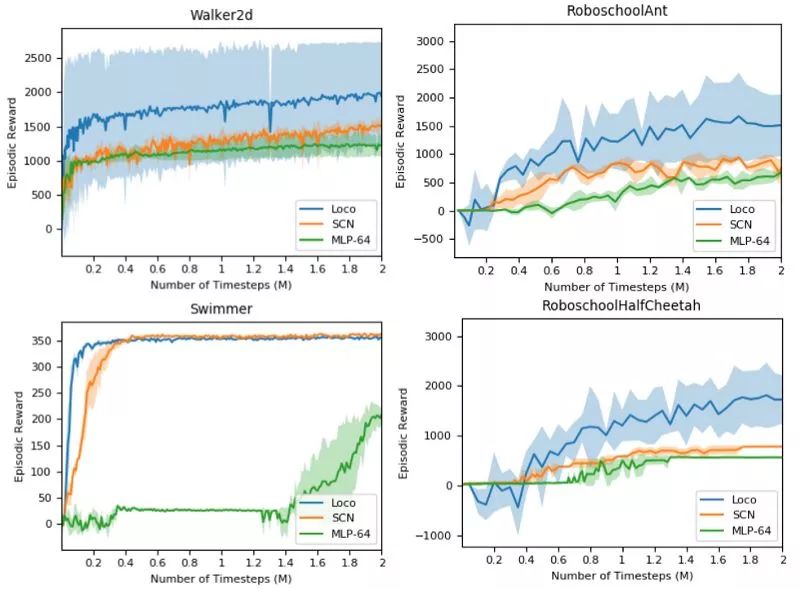
上图是采用ES训练运动神经网络(蓝色为案例研究网络)、结构控制网络(橙色为SCN)、基线多层感知机(绿色为MLP) 在2M时间步长的训练曲线。
结论
我希望本教程能够帮助您重现结果,并继续在这个领域进行研究。如果您想了解这方面讨论内容的更多信息,或者有任何疑惑,请在本文后面留下评论。
我们鼓励进一步研究探索SCN的不同应用(如案例研究所示),特别是在机器人控制领域。如果你发现任何有趣的东西,请告诉我们!
我们正继续研究深层强化学习的策略网络结构,希望在未来能有更多有趣的发现。下次再见!

点击阅读原文,回看ICML论文其他解读



