独家 | 哈佛教授公开R语言源码,教你用R制作gif动图

原文标题:Code for my educational gifs
作者:Rafael Irizarry
翻译:贾琳
本文长度为1800字,建议阅读4分钟
Rafael Irizarry是哈佛大学以及the Dana-Farber Cancer Institute的应用统计教授,他专注于研究基因组学,并且教授数门数据科学课程。在本文中他公开了自己授课时所使用的gif动图的R语言源码,同时也对涉及的几个话题进行了简单的论述,对于希望了解数据科学原理、如何使用R语言来进行可视化的读者都有所助益。
在日常教学的过程中,我有时会用动画来形象地解释概念,并且通过 @rafalab账号(https://twitter.com/rafalab)在社交媒体上分享。
John Storey最近问我是否可以公开这些源代码。由于我不甚有条理,而且这些动画都是灵机一动想出来的,所以之前这些代码分散在几个不相关联的文件中。John的请求促使我把这些代码整理在一起发布在这里。
所有的gif动图都是用R语言绘制的数张图片的叠加。在代码中你可以发现,我用几种不同的方法将单独的图片转化成动态gif图。第一种方法(不推荐)是将图片文件存储下来,然后调用ImageMagick转化工具(https://www.imagemagick.org/script/index.php)。在R环境下,我现在使用的方法是animation包的saveGIF函数,这是通过读者Yihui Xie在我simplystats博客下面的评论学习到的。当用ggplot画图时,我会使用David Robinson的gganimate包(https://github.com/dgrtwo/gganimate)。最后一种方法是我在加特效(例如调相)时会用到的:在线Animated GIF maker(https://ezgif.com/maker)。
以下就是这些gif动图的源代码,我大致按流行程度排序。因为代码是很着急写出来的,请不要过于苛责我。事实上,你可以随意批判,这就是我们学习的方式。
辛普森悖论
这张gif阐述的是辛普森悖论:我们看到X变量和Y变量有很强的负相关关系。不过,一旦我们用一个混杂因素Z变量进行分层,用不同颜色来表示Z,每一层中的相关性就会转化为正相关。这里的数据是虚构的,不过假设说X代表学生参加辅导的次数,Y代表九年级的测验分数,然后再用八年级的测验分数Z来对学生进行分层,我们也会发现这样的现象。
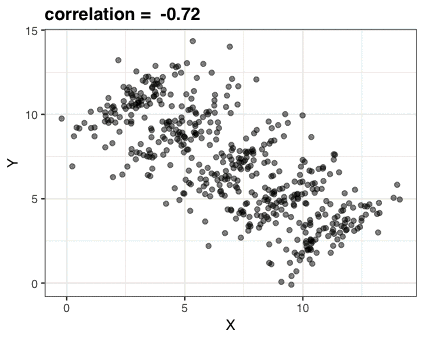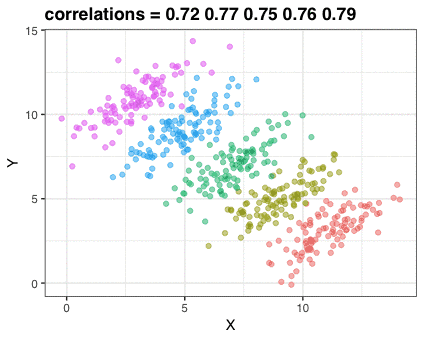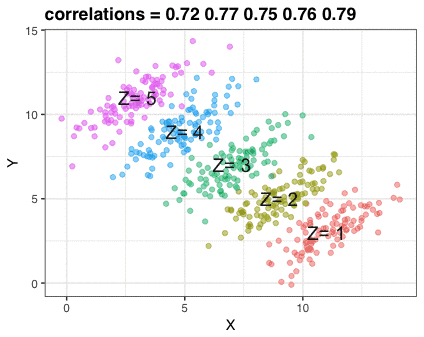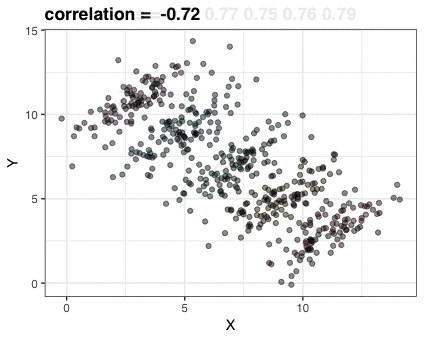
这张动图仅用三张图片组成。我用RStudio的Export功能将它们把存下来,然后用Animated GIF maker(https://ezgif.com/maker)来制作gif。以下是这三张图片的代码:

局部加权回归散点平滑法(Loess)
我分享的第一个教学动图是为了解释局部加权回归散点平滑法(Loess)的原理。具体来说,我们对于每一个自变量,比如x0,都让其对任何一个临近点有正的加权值,用加权回归拟合一条线,保留经过拟合所得的结果,然后移动向下一个点。
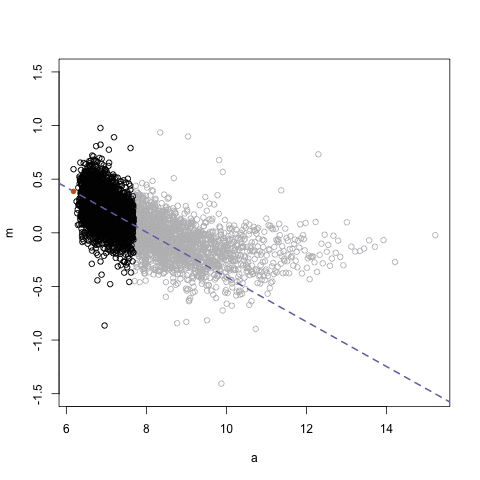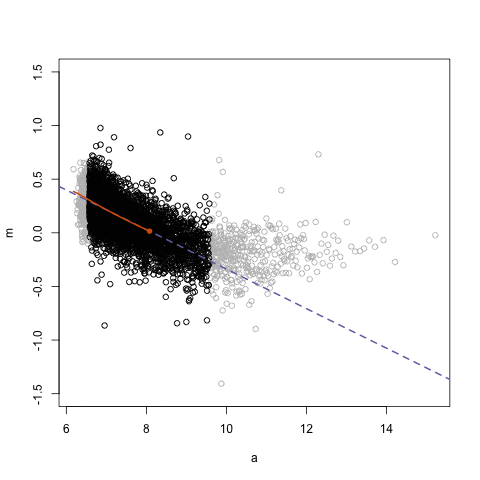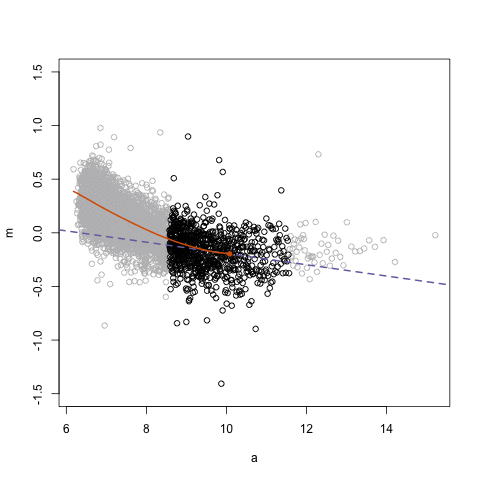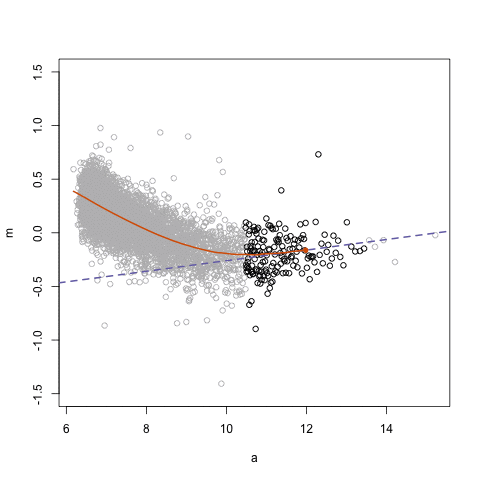
这里的数据来源是某个基因芯片实验。图中所示的是MA图,即比例对数与对数平均值之间的关系。我用animation包来保存gif动图。
预期寿命 vs 生育率
这个gif动图是复制Hans Rosling (https://en.wikipedia.org/wiki/ Hans_Rosling)在他的演讲“关于贫穷的新发现”(New Insights on Poverty,(https://www.ted.com/talks/ hans_rosling_reveals_new_insights_on_poverty?language=en))中展示的动画。该图很好地展现出数据可视化在消除误解方面的作用,Hans Rosling通过这张动图展示了如今并不如40年前一样能够简单将世界划分成两半。之前,人们一般把世界分为拥有更长寿命、较少家庭人口的西方富有国家和较短寿命、较多家庭人口的发展中国家,而这个图向我们展示了这种划分的不合理性。
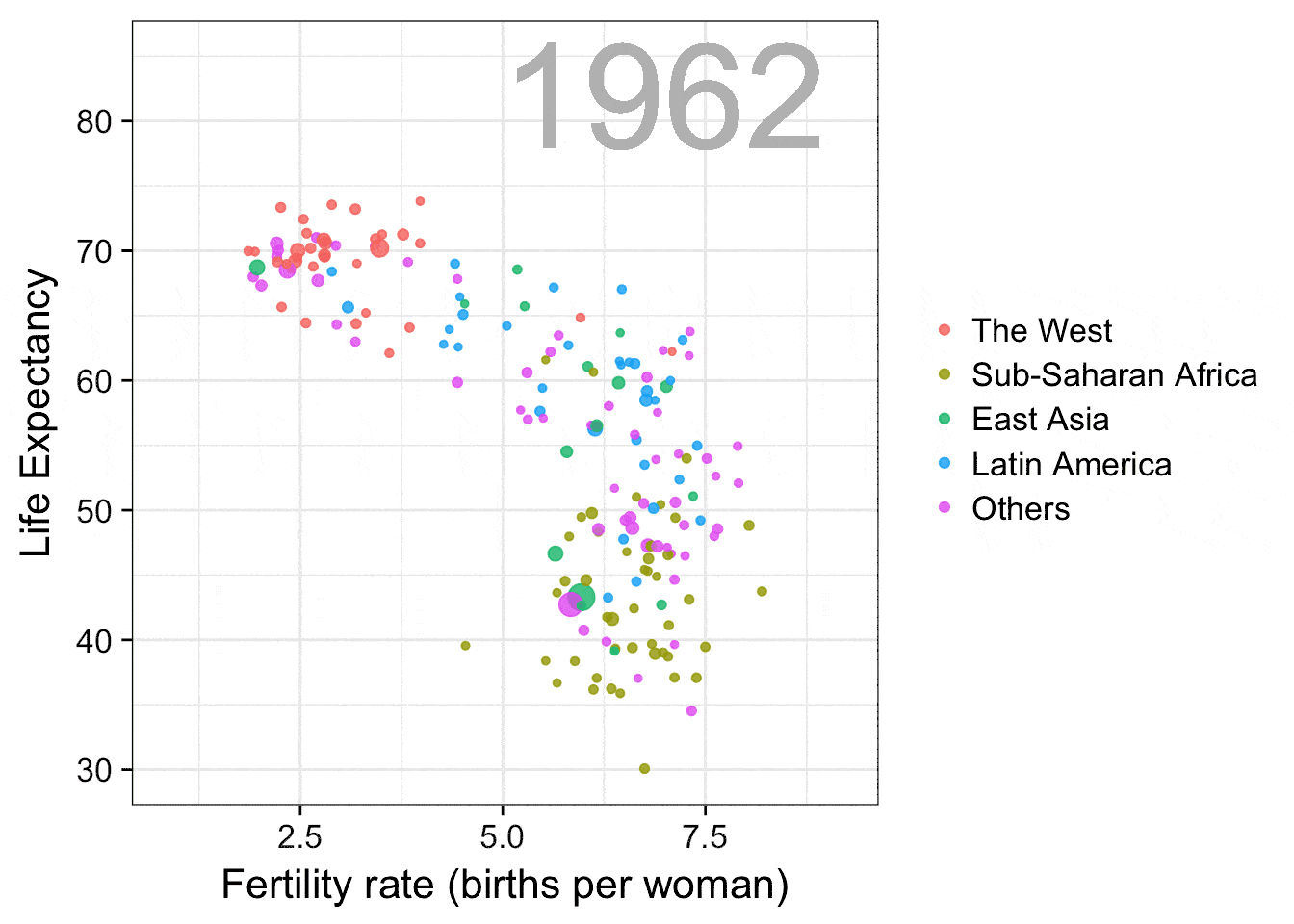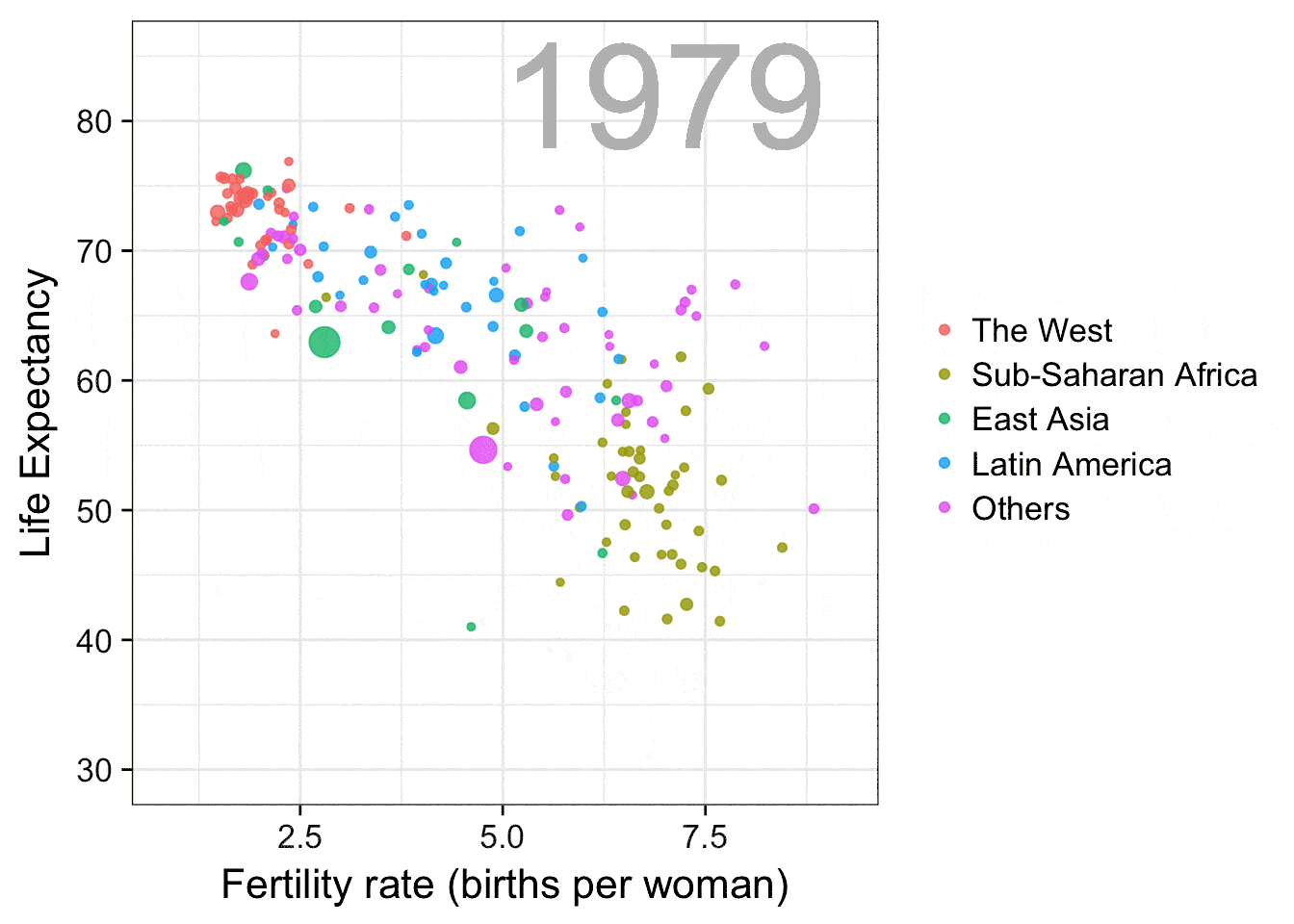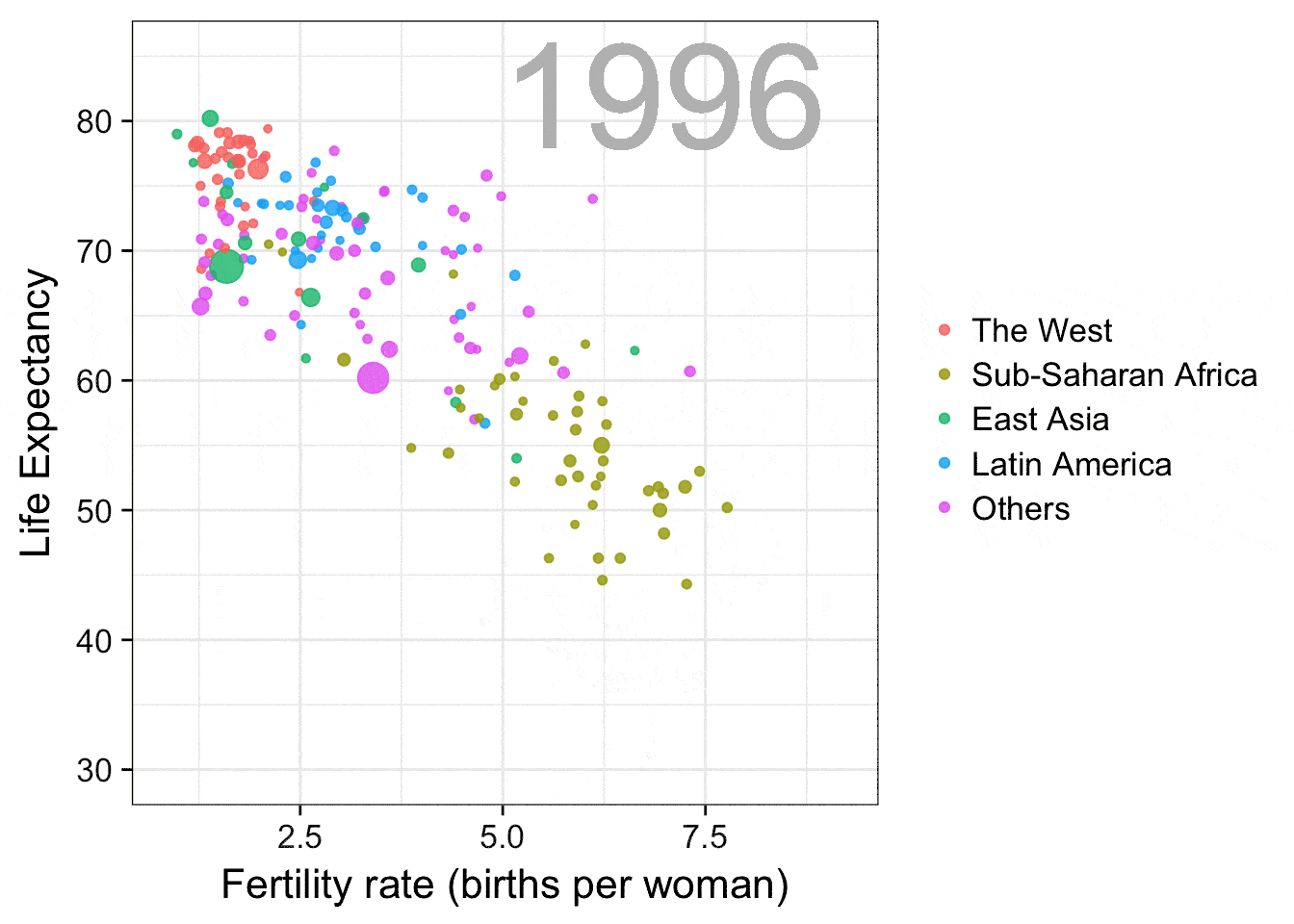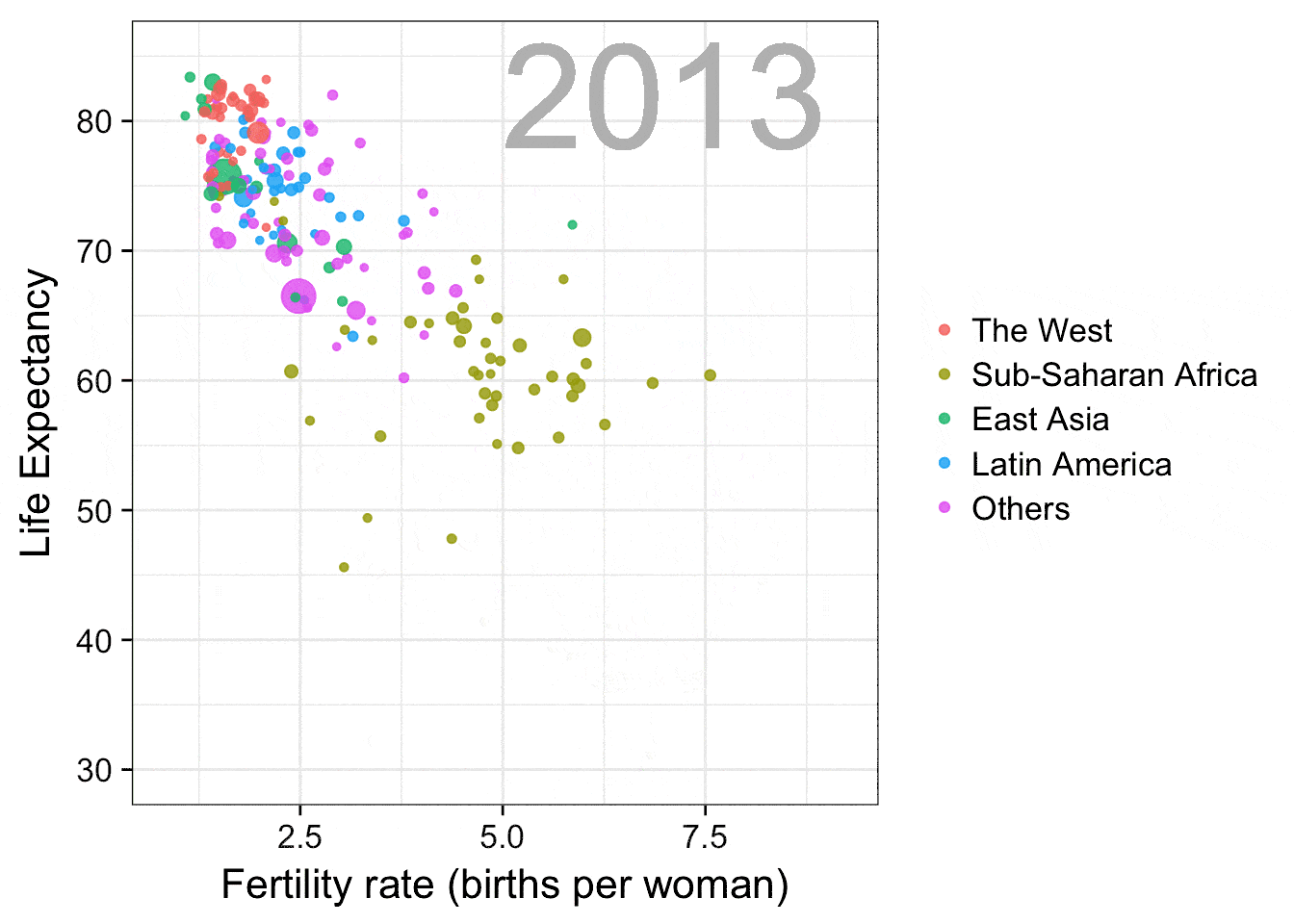
感谢gganimate包,画这个图使用的代码非常简单。

联合国选举模式
这里,我们使用Erik Voeten和Anton Strezhnev提供的联合国选举数据来阐释距离的概念。
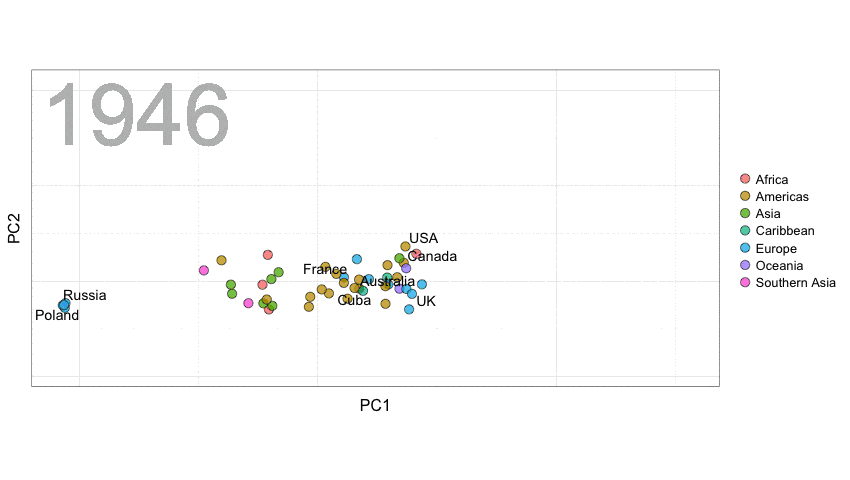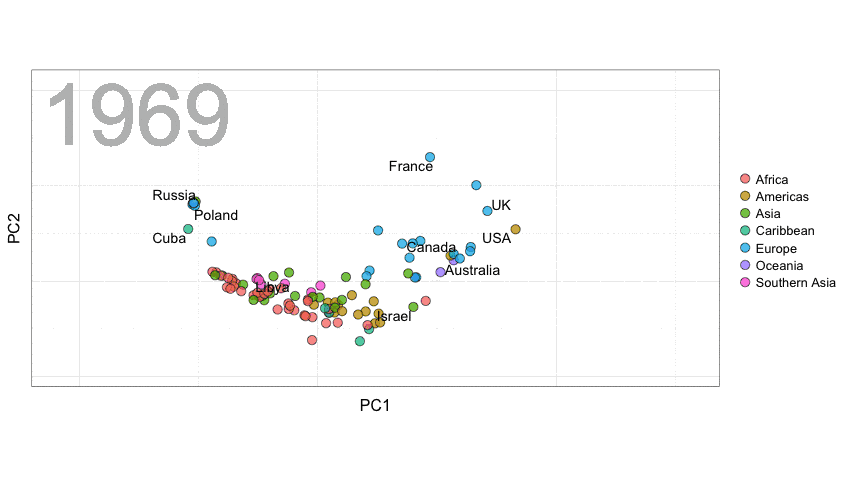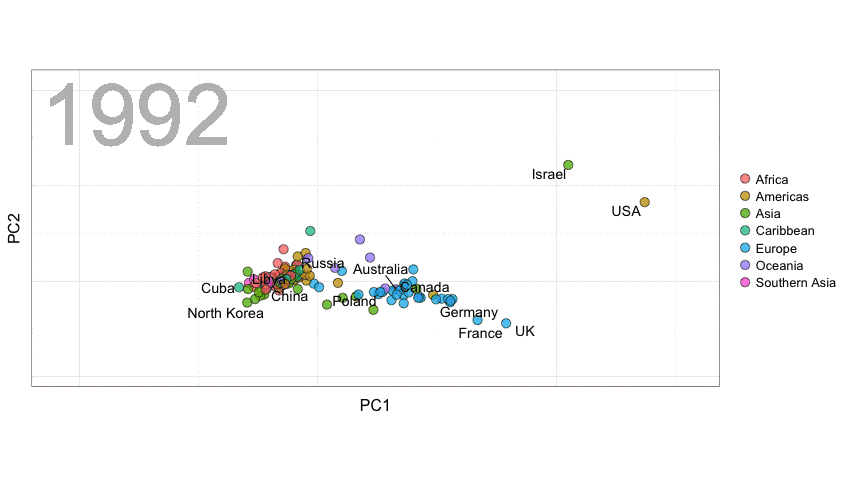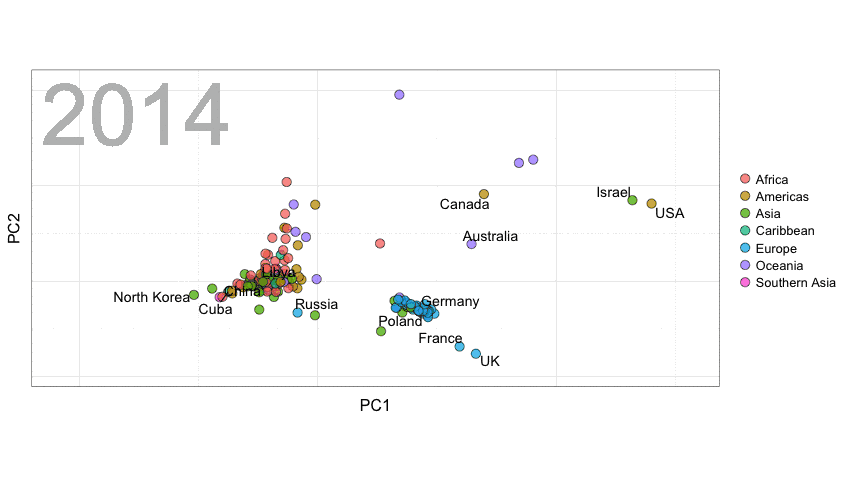
以下是代码。整理数据的代码是由David Robinson(https://twitter.com/drob)提供的。你会看到我们将随时间变化的距离进行了平滑处理,从而避免一些点跳动范围过大。



随机森林
在过去的很长一段时间里,我都觉得很难理解为何随机森林作为一种基于树的算法,却能够产生平滑的预测。这里的gif图帮助我理解了原因。我用的是2008年总统选举的数据库,因为我认为该数据的趋势总体是平滑的,但是有几个尖锐的边,就连局部加权回归散点平滑法都很难预测。需要注意的是,我们只有一个影响因素,这个gif并不能展示出随机森林的另一个重要特点:随机的特征选取可以减少树与树之间的相关程度。
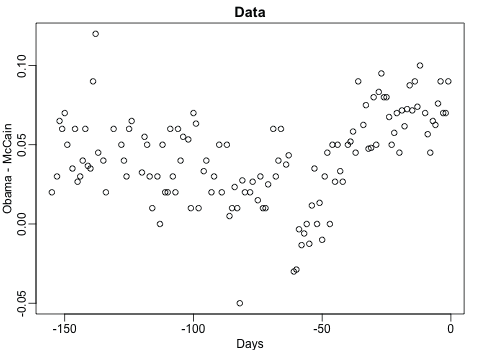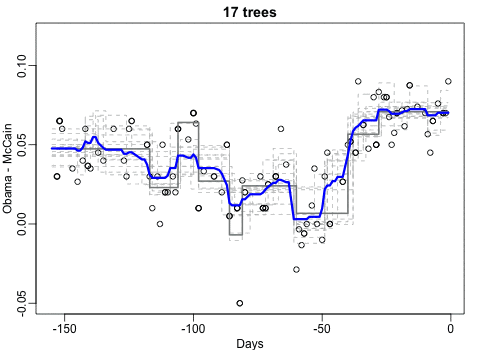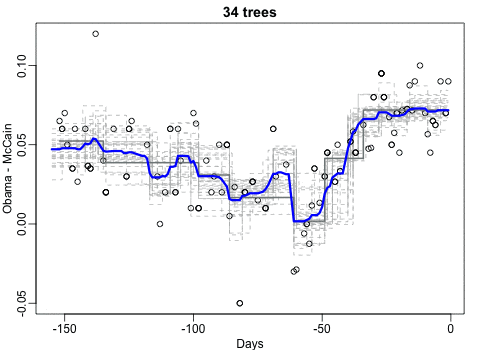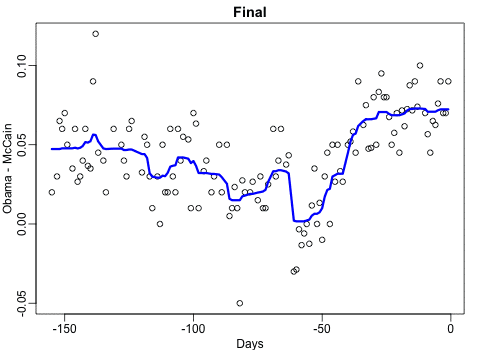
你可以看到我在代码中使用的方式是传统的、我并不推荐的方式:保存所有的图片文件然后调用系统指令转化。


生态谬误
在分享辛普森悖论的动图以后,有些人问我生态谬误是不是相同的情况。其实这二者是不同的。生态谬误是我们试图通过平均值的强相关性来推断个体之间的相关性。为了更好的解释,我用dslabs包中自带的gapminder的数据(http://gapminder.org/)画出了一个动图,展示新生儿存活率的对数与日均收入的对数之间的关系。可以看到在地区层面上二者相关度很高,但在各个国家层面上相关度很低。这是因为同一地区国家与国家之间的差异导致的。
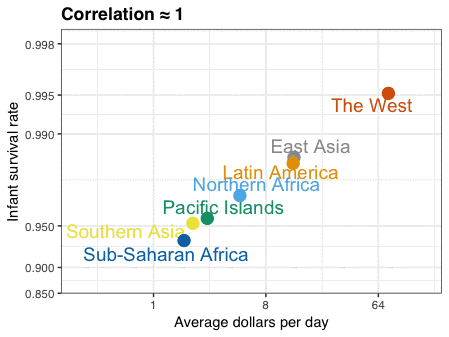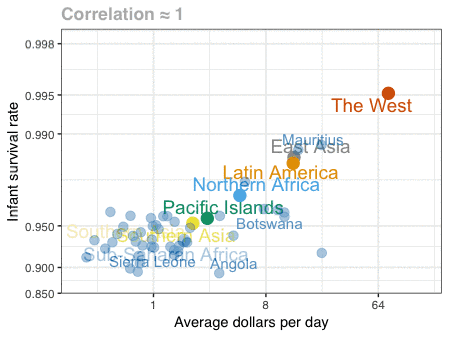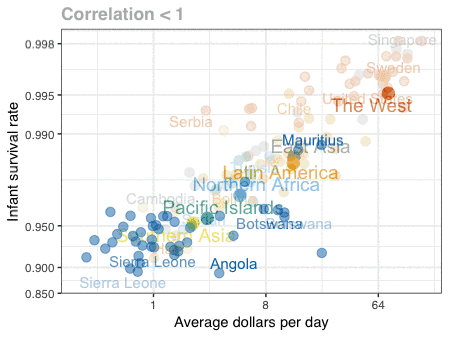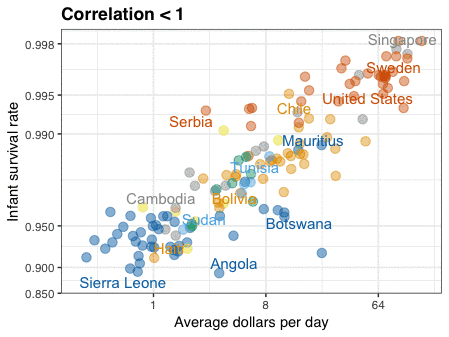
这张gif只由三张图构成。我用RStudio的Export功能保存图片,然后用Animated GIF maker(https://ezgif.com/maker)来制作gif。
第一张图是地区平均值;撒哈拉以南非洲国家的数值,你可以看到一个平均值被分成数个不同的数值;第三张是所有国家的情况。我标出了一些(与本地区相比)变化较大的国家,并且用了色盲也能识别的颜色。这里的代码有些复杂,原因是我不得不对Gapminder数据进行预处理。


贝叶斯定律
这个简单的动图展示的是将一种非常准确的诊断方法应用于一个发病率很低的群体的诊断结果。它展示出来的是,在已知诊断结果是阳性的情况下发病的先验概率,比该诊断方法的初试准确率要低。你可以用贝叶斯定律来确定真实的条件概率。更多细节请参考这里(https://simplystatistics.org/2014/10/17/bayes-rule-in-a-gif/)。
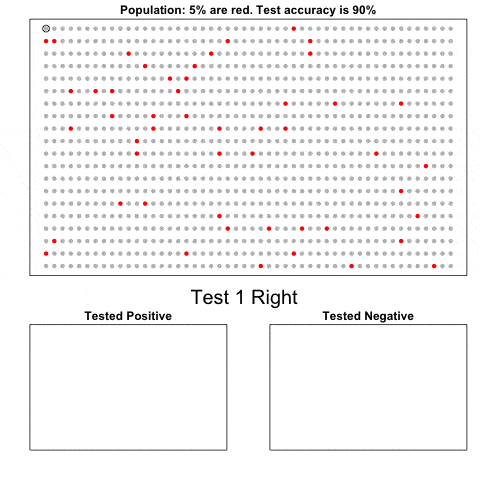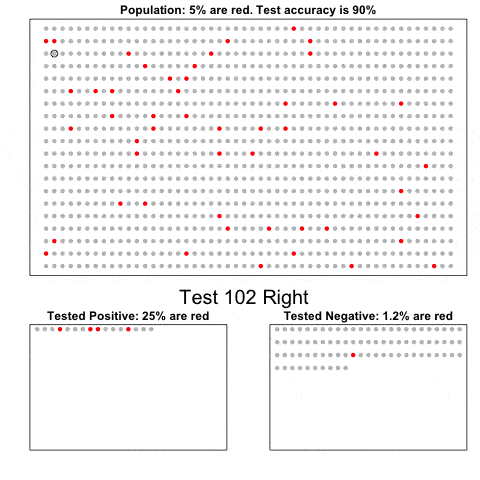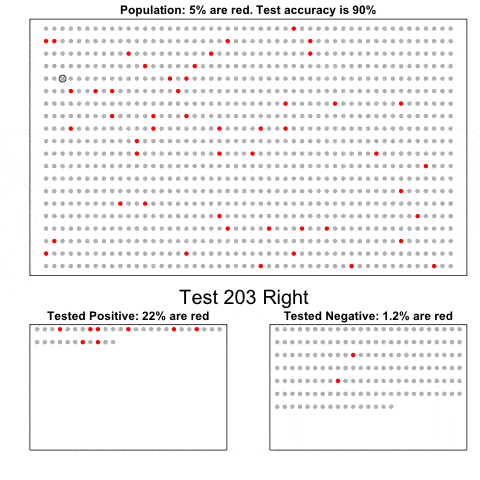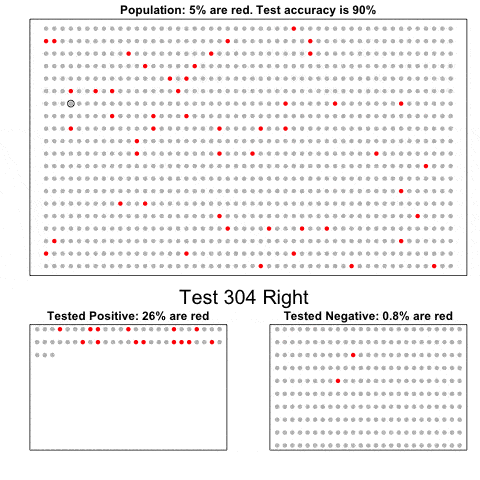
因为我们要做动态图,代码有一些复杂难懂。


吃豆子
最后,我做了这个动画,向你们展示饼图唯一的用处。


原文链接:
https://simplystatistics.org/2017/08/08/code-for-my-educational-gifs/
编辑:黄继彦

贾琳,清华大学2012级本科毕业生,现就读于美国达特茅斯学院工程管理硕士专业。爱好数据分析、数据科学,期待在数据派THU这个平台上向更多 志同道合的朋友学习和交流。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。
转载须知
如需转载文章,请做到 1、正文前标示:转自数据派THU(ID:DatapiTHU);2、文章结尾处附上数据派二维码。
申请转载,请发送邮件至datapi@tsingdata.com


点击“阅读原文”报名


