基于 Flink 的实时计算平台在58同城的架构实践
58同城作为覆盖生活全领域的服务平台,业务覆盖招聘、房产、汽车、金融、二手及本地服务等各个方面。丰富的业务线和庞大的用户数每天产生海量用户数据需要实时化的计算分析,实时计算平台定位于为集团海量数据提供高效、稳定、分布式实时计算的基础服务。本文主要介绍58同城基于Flink打造的一站式实时计算平台Wstream。
实时计算场景
和很多互联网公司一样,实时计算在58拥有丰富的场景需求,主要包括以下几类:
平台演进
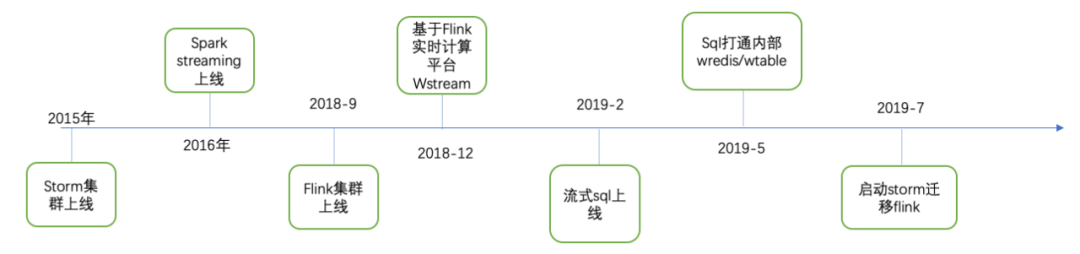
平台规模

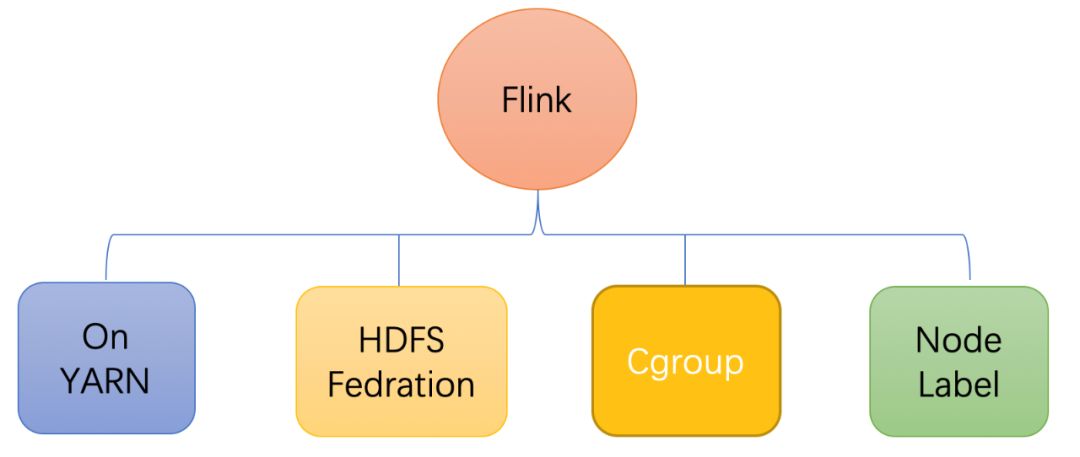
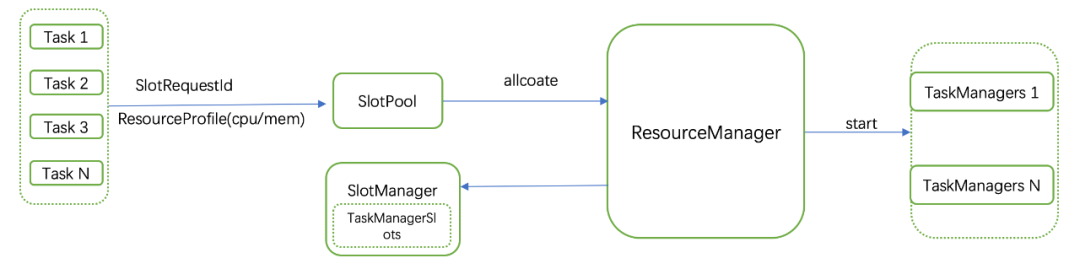
Flink稳定性
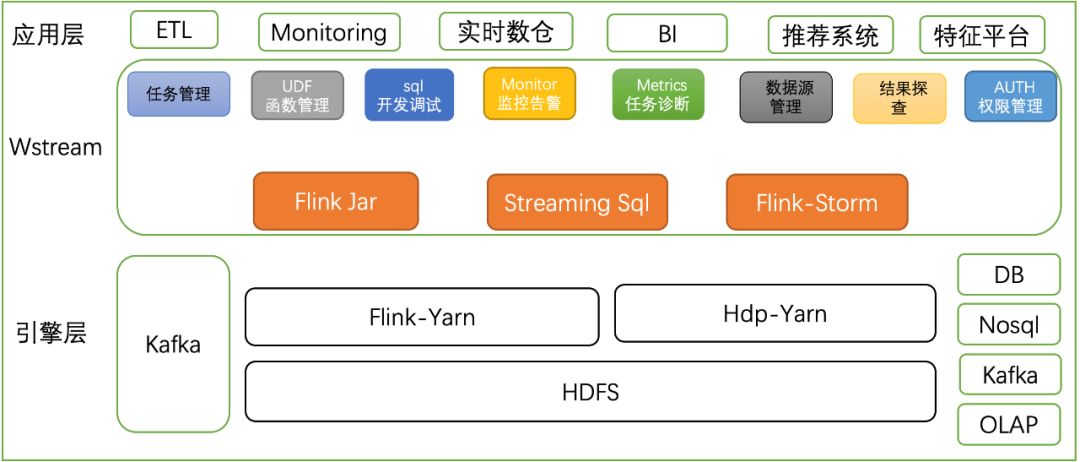
平台化管理
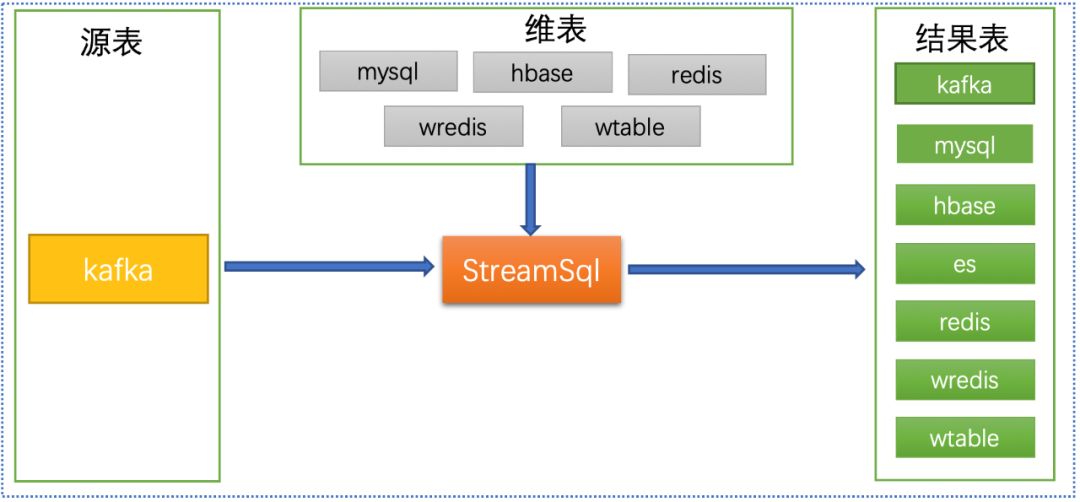
流式sql能力建设
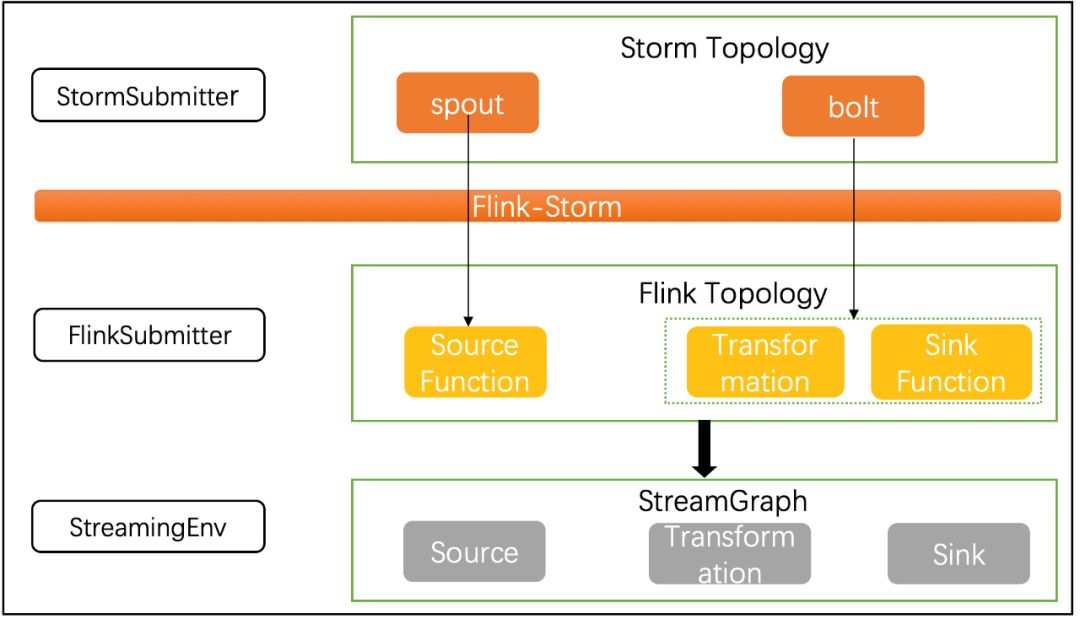
Storm任务迁移Flink
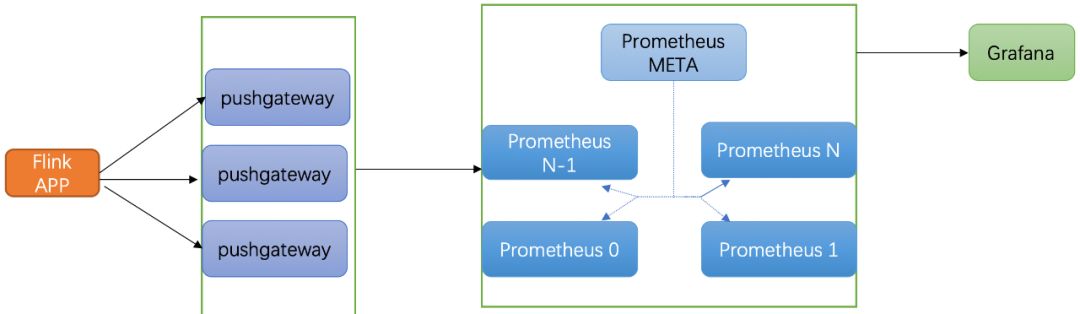
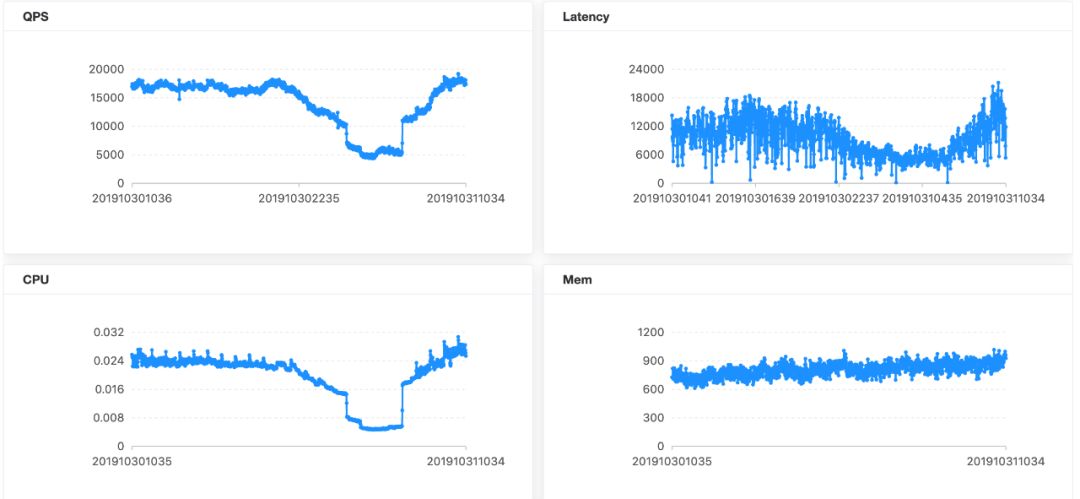
任务诊断
Flink优化
后续规划


登录查看更多
相关内容






相关VIP内容
相关资讯
相关论文