大会 | 亲历NIPS 2017:收获与思考
编者按:今年的NIPS大会就在本月刚刚落下帷幕,微软亚洲研究院机器学习组实习生汪跃亲身参与了本次大会,并为我们带来了参加本次大会的见闻和感受。想知道大会上到底发生了什么,那就跟我们一起来看看吧。
机器学习领域的顶会NIPS 2017于12月3日至9日在美丽的加州长滩(Long Beach)举办,长滩的好天气也带给了我一个好心情,让我精神饱满地去迎接来自前沿知识的洗礼。

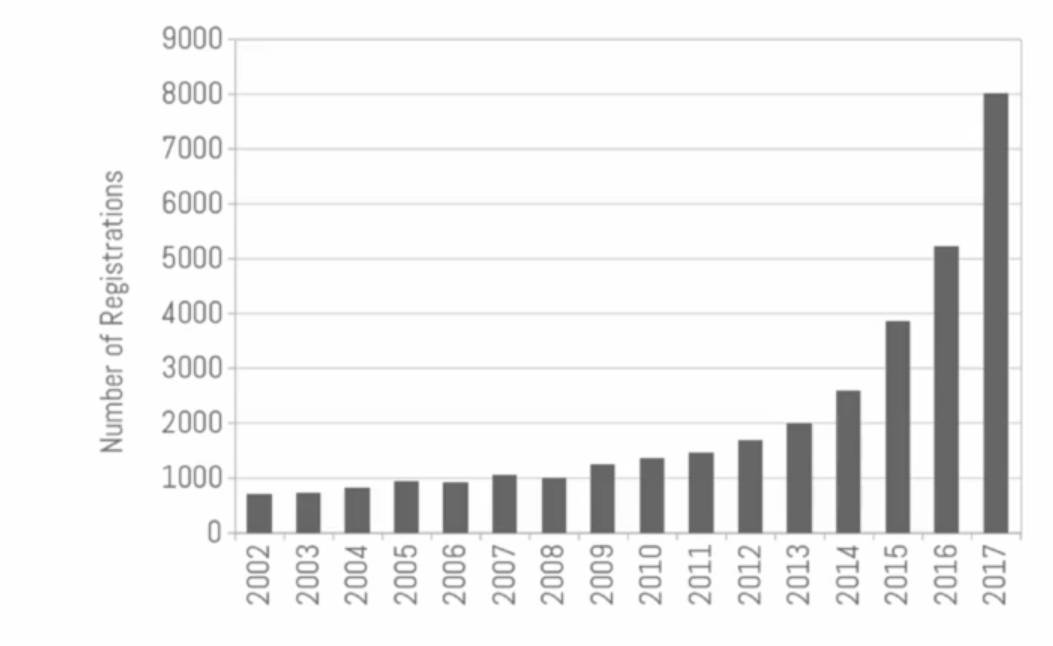
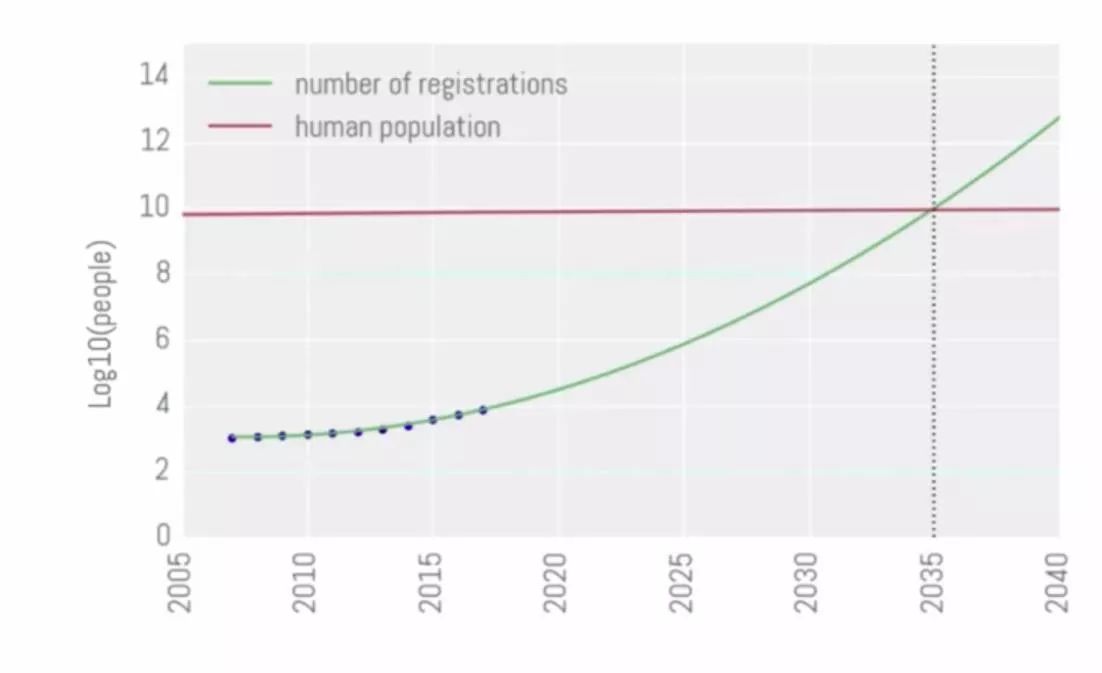
今年共有超过8000名来自世界各地的研究人员注册并参加了会议,相比去年,参与人数大幅度增长。在致开幕辞的时候,组织者开了个玩笑,如果会议的增长速度一直保持,那么会议的注册人数将在2035年超过世界人口的数量。这个让人忍俊不禁的玩笑就是NIPS 2017在我记忆中留下的绚烂画面的起笔。
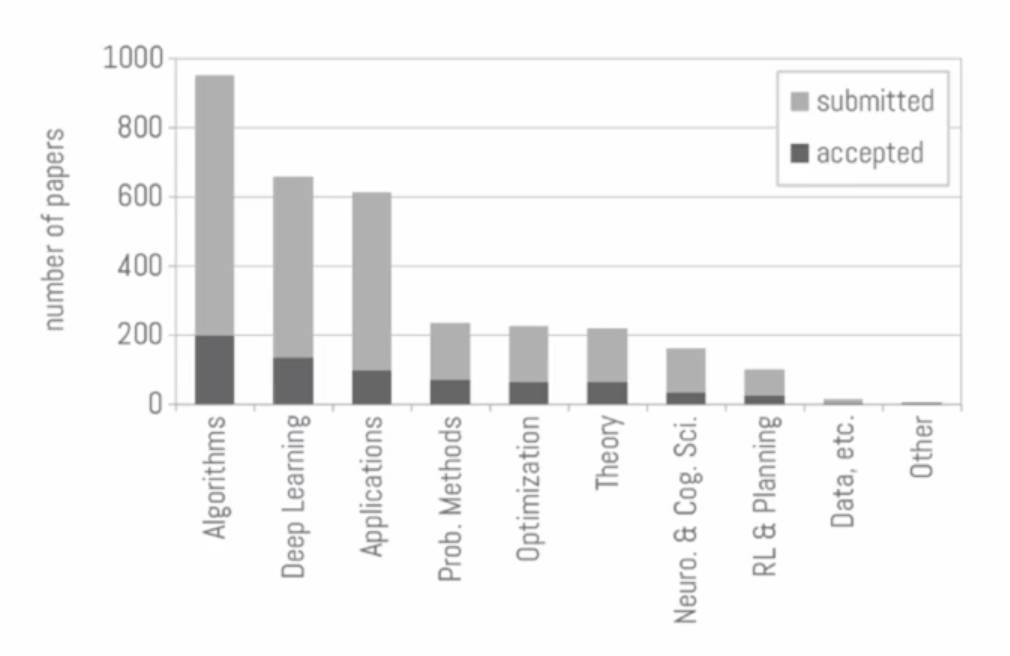
本次大会的内容涵盖了机器学习、神经科学、认知科学、心理学、计算机视觉、统计语言学和信息论等156个领域。在今年提交的3240篇论文中,679篇被接受,接受比例只有21%,入选论文中有527篇posters,112篇spotlights和40篇orals。
本次NIPS大会共评选出三篇最佳论文(Best paper awards)和一篇Test of time award,分别是:
Best paper awards:
Noam Brown, Tuomas Sandholm. Safe and Nested Subgame Solving for Imperfect-Information Games.
这篇文章解决了不完美信息博弈的问题,基于这项技术的Libratus项目,打败了德州扑克的几位人类顶级玩家。
Hongseok Namkoong, John Duchi. Variance-based Regularization with Convex Objectives.
这篇文章研究了随机优化风险最小化问题,给出了一个方差项的凸的替代项使得能在计算复杂度和计算误差精度之间实现权衡。
Wittawat Jitkrittum, Wenkai Xu, Zoltan Szabo, Kenji Fukumizu, Arthur Gretton. A Linear-Time Kernel Goodness-of-Fit Test.
这篇文章提出了一个全新的拟合优度(goodness-of-fit)的算法,新算法的样本复杂度随着样本量的增长线性增长。
Test of time award:
Ali Rahimi, Benjamen Recht. Random Features for Large-Scale Kernel Machines. NIPS 2007. Test of time award
奖励给十年前的一篇经典的文章。这篇文章通过利用随机特征映射来加速大规模核方法训练。
在参加NIPS 2017的过程中,我比较关注的是强化学习这一领域,其中有很多有意思的tutorial,poster和invited talk。从总体趋势来看,今年的NIPS 上不光有很多工作在做强化学习的应用,也有很多的目光被投向了对强化学习算法更深刻的理解以及基于这种理解所做的基础算法上的改进。这种对于基础算法本身的探讨和理解往往会告诉我们很多问题的本质,想法和结论也都让人感觉大受启发。
举几个例子来说,Zap Q-Learning通过分析Q-learning的方差,提出了名为zap Q-learning 的算法,使得新算法的渐进方差达到最优。具体来说,传统Q-learning算法的收敛慢、不稳定等问题一直困扰着大家。而这篇文章证明了一个定理:说明传统的Q-learning算法在一些假设下,渐进方差会趋于无穷,从而解释了Q-learning算法不稳定、难收敛的原因。进一步,作者根据matrix gain技术,提出了Zap Q-learning算法,使得新算法的方差达到最小,并且证明了算法的收敛性。



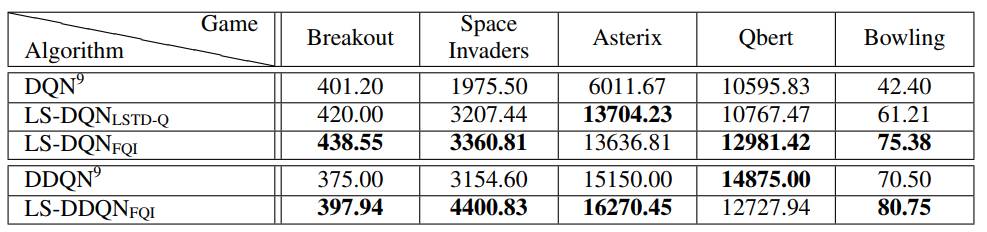
在Shallow Updates for Deep Reinforcement Learning中,作者将linear RL 和deep RL 结合起来,取长补短。具体来说,深度强化学习(DRL),例如DQN等方法,在最近一段时间取得了非常多的前沿的成就,但是有非常多的非常敏感的超参需要手动去调整。对于浅层强化学习来说,例如线性函数近似的方法,算法更加稳定,并且没有那么多的超参数需要去调整,但是往往需要精心设计过的特征提取。在这个工作中,作者提出了LS-DQN 的算法,结合了深度强化学习算法中的特征提取和浅层强化学习算法。具体做法是先训练深度强化学习网络,然后将神经网络的最后一层看成是浅层线性模型,将最后一层的参数利用传统浅层强化学习算法进行重新调整。最后作者在5个Atari游戏上做了实验,实验结果也是表现出来这一简单的idea非常的有效。

除了poster,NIPS上也有很多令人印象深刻的tutorial,invited talk 等,例如:卡耐基•梅隆大学的Emma Brunskill 做了题为Reinforcement Learning with People的tutorial。从强化学习帮助人(强化学习在生活中的应用)和人帮助强化学习(人参与到强化学习的学习中)两个角度,全面的介绍了强化学习最近一段时间的发展。其中提到的很多概念,也在poster环节看到了很多的paper做了具体的工作。比如Exploration-Expectation trade-off、multiagent reinforcement learning、Policy evaluation等。
具体来说,tutorial 先是介绍了强化学习的相关背景和最近大家关注的一些题目。例如最基础的MDP 的定义,强化学习通常的setting,常用的解决强化学习问题的三个方法论:value function based、policy based、model based,以及它们之间的一些关系。
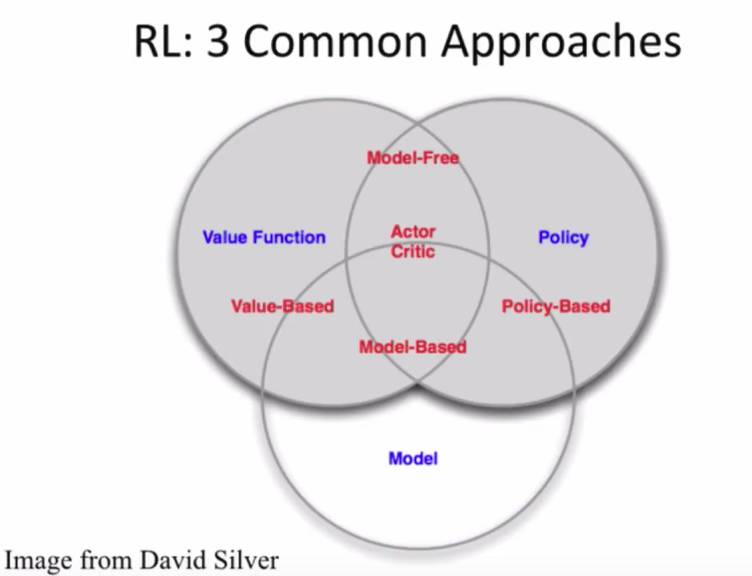
在介绍强化学习帮助人的环节,tutorial 主要集中在如何高效准确鲁棒地做policy evaluation的问题, 特别介绍了很对在off-policy setting下的batch RL算法的分析和改进。

在介绍人帮助强化学习的环节,tutorial主要从人在强化学习算法学习过程中所起的作用的角度,介绍了相关的工作。例如如何设计reward,如何给RL agent 做演示从而进行模仿学习,如何让人帮助RL agent 做好Exploration-Exploitation trade-off等等。

来自加拿大麦吉尔大学的Joelle Pineau 做了题为Reproducibility in Deep Reinforcement Learning and Beyond 的invited talk。内容是最近大家特别关注的强化学习中实验结果可重复性的相关内容,相信也引起了大部分强化学习领域的研究者的共鸣,引发了大家对于实验结论可靠性的思考和质疑。来自斯坦福大学的Ben Van Roy 做了题为Deep Exploration Via Randomized Value Functions的invited talk,带着大家一起探讨了deep exploration在强化学习问题中的重要性以及解决办法, 表明了更鲁棒的AI需要一个更有效的deep exploration策略的观点。

今年微软亚洲研究院机器学习组共有4篇文章发表在NIPS上,分别是关于机器翻译、GBDT、和强化学习的。其中有关机器翻译的两项工作着眼于把decoder做得更精细,分别引入了价值网络和“推敲”的思想;GBDT的利器LightGBM已经开源了几个月并在GitHub上积累了4371多颗星;有关强化学习的工作解决了在non-iid的情况下进行policy evaluation的重要理论问题。下面我来给大家展示一下我们的研究成果。
这四篇论文分别是:
Xia, Yingce, etal. "Deliberation networks:Sequence generation beyond one-passdecoding." Advances in Neural Information Processing Systems.2017.
He, Di, et al. "Decoding with value networks for neural machine translation." Advancesin Neural Information Processing Systems. 2017.
Wang, Yue, et al. "Finite sample analysis of the GTD Policy Evaluation Algorithms in MarkovSetting." Advances in Neural Information Processing Systems.2017.
Ke, Guolin, et al. "A Highly Efficient Gradient Boosting Decision Tree." Advances in Neural Information Processing Systems. 2017.
其中前两篇论文已经由我们组其他两位联合培养博士生做过详细讲解,有兴趣的同学可以点击下面链接:
● 干货 | NIPS 2017线上分享:利用价值网络改进神经机器翻译
接下来,我对另外两篇论文做一个简单的介绍。
A Highly Efficient Gradient Boosting Decision Tree
这篇论文提出了一个名为LightGBM的工具,解决了非常常用的梯度提升决策树Gradient Boosting Decision Tree (GBDT) 在大规模训练时非常耗时的问题。LightGBM 的设计的思路主要有两点:1. 单个机器在不牺牲速度的情况下,尽可能多地用上更多的数据;2.多机并行的时候,通信的代价尽可能地低,并且在计算上可以做到线性加速。
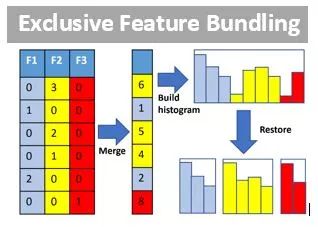
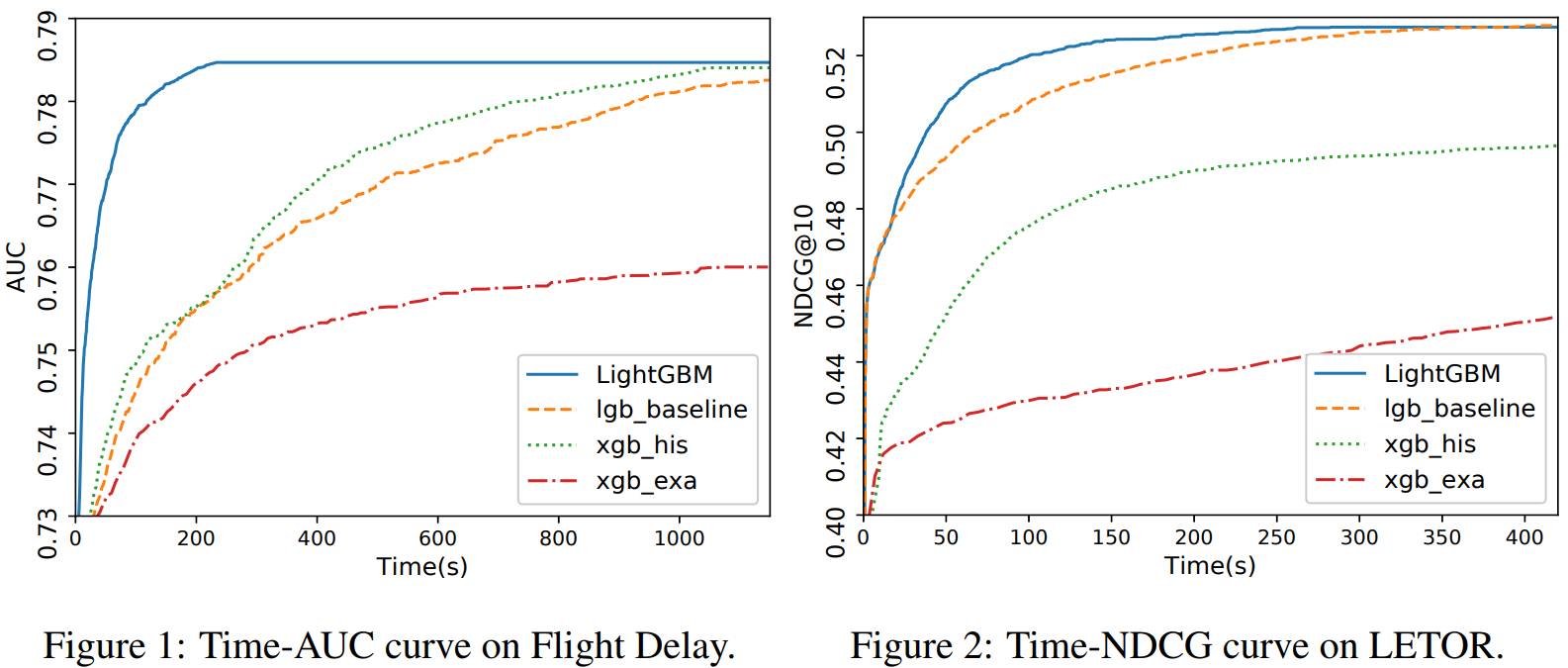
Gradient-based One-Side Sampling (GOSS) 和 Exclusive Feature Bundling (EFB)这两项技术分别减小了样本数和特征数,从而极大地加快了GBDT训练速度,并且提高了结果精度,从实验结果来看当然是又快又好。这个项目在GitHub上已经有4000+ 个星和1000+个fork,并且我们还提供了python, R等的接口,感兴趣的同学可以去试着用一用哦。
GitHub项目主页地址:https://github.com/Microsoft/LightGBM

Finite sample analysis of the GTD Policy Evaluation Algorithms in Markov Setting
这是一篇强化学习方面的理论性论文,解决的是在 强化学习中一个重要问题——策略评估 (Policy Evaluation)在更贴近实际的假定下的收敛性分析。策略评估的目标是估计给定策略的价 值函数(从任一状态出发,依照给定的策略时,期望意义下未来的累计回报)。 当状态空间特别 大或者是连续空间的时候,线性函数近似下的 GTD 策略评估算法非常常用。考虑到收集数据的过 程非常耗费时间和代价,清楚地的理解 GTD算法在有限样本情况下的表现就显得非常重要。之前 的工作将 GTD 算法与鞍点问题建立了联系,并且在样本独立同分布和步长为定值的情况下给出了 GTD 算法的有限样本误差分析。但是,我们都知道,在实际的强化学习问题中,数据都是由马氏 决策过程产生的,并不是独立同分布的。并且在实际中,步长往往也不一定是一个定值。因此在我 们的工作中,我们首先证明了在数据来自于马尔科夫链的情况下,鞍点问题的期望意义下和高概率 意义下的有限样本误差,进而得到了更接近于实际情形下的 GTD 的算法的有限样本误差分析。
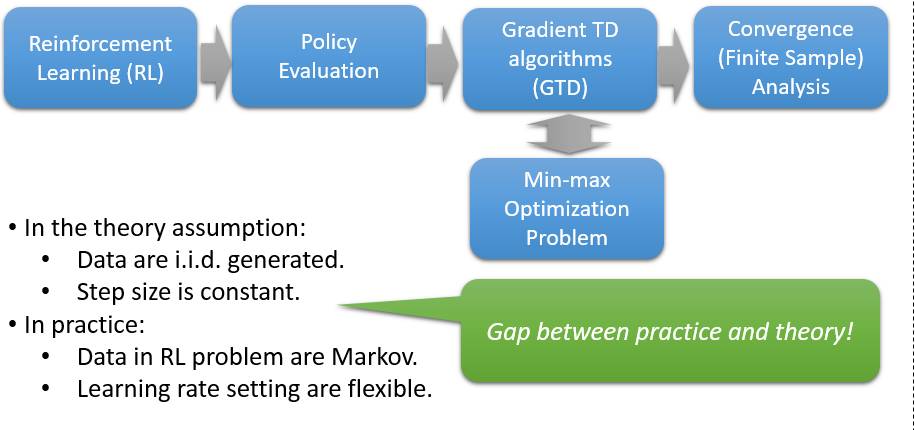


从我们的结果中可以看到, 在实际中的马尔科夫的情形下,(1)GTD算法确实依然收敛;(2) 收敛的速率依赖于步长的设定和马尔科夫链的混合时间这一属性;(3)通过混合时间的角度解释 了经验回放这一技巧的有效性,其有效性可以理解成缩短了马尔科夫链的混合时间。就我们所知, 我们的工作首次给出了 GTD 算法在马尔科夫情形下的有限样本误差分析。
短短几天的NIPS之行收获满满,也希望能和众多研究者一起继续探索科学的前沿。

汪跃,北京交通大学在读博士生,专业是概率论与数理统计,目前在微软亚洲研究院机器学习组做实习生,导师是陈薇研究员。感兴趣的研究方向是在强化学习中的算法理论分析和算法设计等方面,以及优化算法相关方向。
你也许还想看:
● 干货 | NIPS 2017线上分享:利用价值网络改进神经机器翻译

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




