BAT题库 | 机器学习面试1000题系列(第241~245题)

241.下图是同一个SVM模型, 但是使用了不同的径向基核函数的gamma参数, 依次是g1, g2, g3 , 下面大小比较正确的是 :
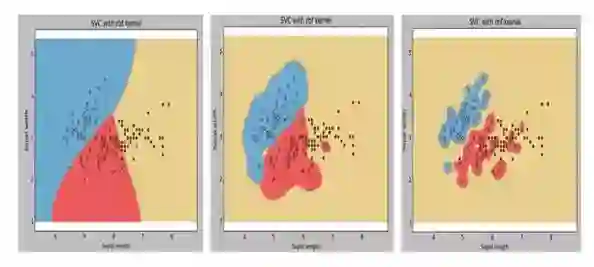
A. g1 > g2 > g3
B. g1 = g2 = g3
C. g1 < g2 < g3
D. g1 >= g2 >= g3
E. g1 <= g2 <= g3
答案: C
242.假设我们要解决一个二类分类问题, 我们已经建立好了模型, 输出是0或1, 初始时设阈值为0.5, 超过0.5概率估计, 就判别为1, 否则就判别为0 ; 如果我们现在用另一个大于0.5的阈值, 那么现在关于模型说法, 正确的是 :
A. 模型分类的召回率会降低或不变
B. 模型分类的召回率会升高
C. 模型分类准确率会升高或不变
D. 模型分类准确率会降低
A. 1
B. 2
C.1和3
D. 2和4
E. 以上都不是
答案: C
这篇文章讲述了阈值对准确率和召回率影响 :
Confidence Splitting Criterions Can Improve Precision And Recall in Random Forest Classifiers
243.”点击率问题”是这样一个预测问题, 99%的人是不会点击的, 而1%的人是会点击进去的, 所以这是一个非常不平衡的数据集. 假设, 现在我们已经建了一个模型来分类, 而且有了99%的预测准确率, 我们可以下的结论是 :
A. 模型预测准确率已经很高了, 我们不需要做什么了
B. 模型预测准确率不高, 我们需要做点什么改进模型
C. 无法下结论
D. 以上都不对
答案: B
99%的预测准确率可能说明, 你预测的没有点进去的人很准确 (因为有99%的人是不会点进去的, 这很好预测). 不能说明你的模型对点进去的人预测准确, 所以, 对于这样的非平衡数据集, 我们要把注意力放在小部分的数据上, 即那些点击进去的人.
详细参考: https://www.analyticsvidhya.com/blog/2016/03/practical-guide-deal-imbalanced-classification-problems/
244.使用k=1的knn算法, 下图二类分类问题, “+” 和 “o” 分别代表两个类, 那么, 用仅拿出一个测试样本的交叉验证方法, 交叉验证的错误率是多少 :
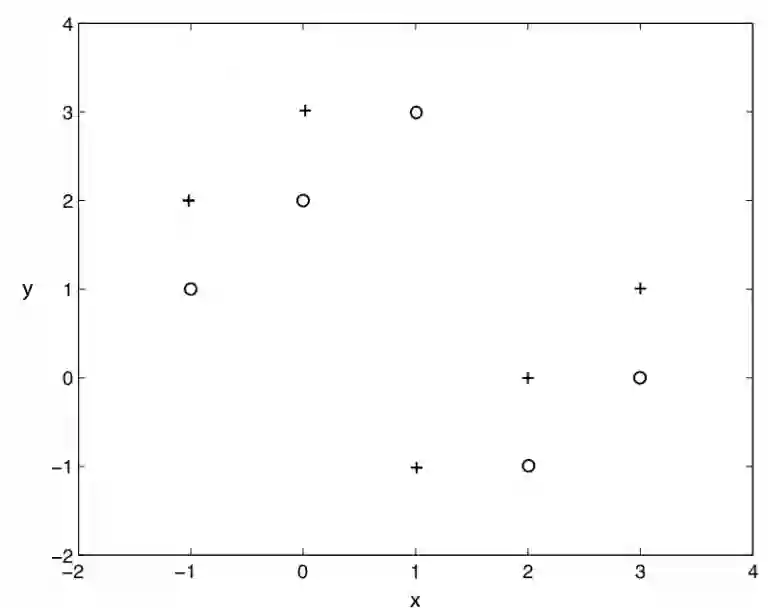
A. 0%
B. 100%
C. 0% 到 100%
D. 以上都不是
答案: B
knn算法就是, 在样本周围看k个样本, 其中大多数样本的分类是A类, 我们就把这个样本分成A类. 显然, k=1 的knn在上图不是一个好选择, 分类的错误率始终是100%
245.我们想在大数据集上训练决策树, 为了使用较少时间, 我们可以 :
A. 增加树的深度
B. 增加学习率 (learning rate)
C. 减少树的深度
D. 减少树的数量
答案: C
A.增加树的深度, 会导致所有节点不断分裂, 直到叶子节点是纯的为止. 所以, 增加深度, 会延长训练时间.
B.决策树没有学习率参数可以调. (不像集成学习和其它有步长的学习方法)
D.决策树只有一棵树, 不是随机森林.
往期题目:

课程咨询|微信:julyedukefu
七月热线:010-82712840



