逼真3D人脸动画等,德国马普所三篇CVPR 2019论文推荐
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文转载自机器之心
计算机视觉领域顶级会议 CVPR 2019 已于近日在美国加州长滩落幕。 CVPR 2019 共收到 5165 篇有效提交论文,相比去年增加了 56%; 接收论文 1300 篇,接收率接近 25.2%。
据了解,德国马克思·普朗克研究所马普智能系统所共有 14 篇论文入选 CVPR 2019,本文简要介绍了其中三篇。
论文 1:Capture, Learning, and Synthesis of 3D Speaking Styles
作者:Daniel Cudeiro、Timo Bolkart、Cassidy Laidlaw、Anurag Ranjan、Michael J. Black
论文链接:
https://ps.is.tuebingen.mpg.de/uploads_file/attachment/attachment/510/paper_final.pdf
项目页面:https://voca.is.tue.mpg.de/
GitHub页面:
https://github.com/TimoBolkart/voca
摘要:音频驱动的 3D 人脸动画已经得到了广泛探索,但该领域仍未达到逼真、类似人类的效果。其原因在于缺乏可用的 3D 数据集、模型和标准评估度量指标。为此,我们创建了一个独特的 4D 人脸数据集 VOCASET,它包括以 60 fps 的帧速率捕捉到的 4D 扫描(共 29 分钟),以及来自 12 名说话者的同期声。然后我们在该数据集上训练一个神经网络,它可以将人物和人脸运动分离开来。学到的模型 VOCA (Voice Operated Character Animation) 可使用任意语音信号作为输入(即使不是英语也可以),然后将大量成人面部转化为逼真的动图。
基于多个人物标签训练使得模型可以学习多种逼真的说话风格。在动图化的过程中,VOCA 还提供动图控制器来改变说话风格、依赖于人物的人脸形状和姿势(即头、下巴和眼球转动)。据我们所知,VOCA 是目前唯一无需重定位即可应用于未见人物的 3D 人脸动图模型。这使得 VOCA 适合比赛录像、VR 头像,或者任何无法提前知道说话者、语音和语言的场景。出于研究目的,我们公开了该数据集和模型,参见:http://voca.is.tue.mpg.de。(http://voca.is.tue.mpg.de./)
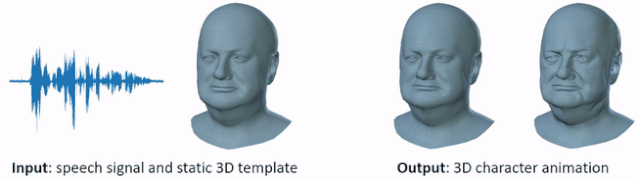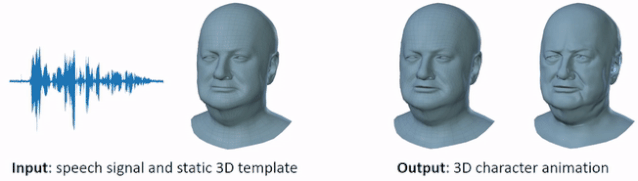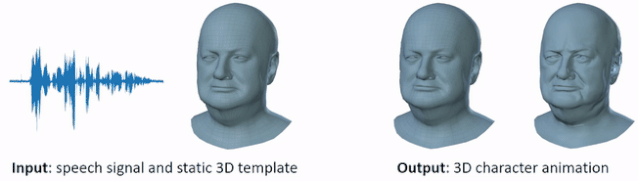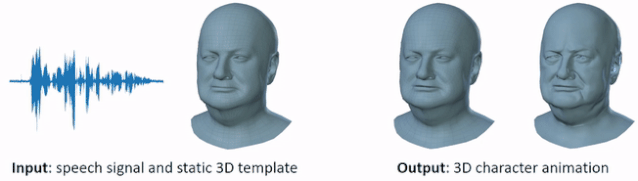
VOCA 是一个简单通用的语音驱动人脸动画框架,适用于大量不同人物。给定任意语音信号和静态 3D 人脸网格输入(左),VOCA 模型输出逼真的 3D 人物动图(右)。
VOCA 模型架构
VOCA 用人物特定的模板 T 和原始音频信号作为输入,研究者利用 DeepSpeech [29] 从中提取特征。期望输出是目标 3D 网格。VOCA 是一个编码器-解码器网络,编码器学习将音频特征转换为低维嵌入,解码器将低维嵌入映射到 3D 顶点位移的高维空间。
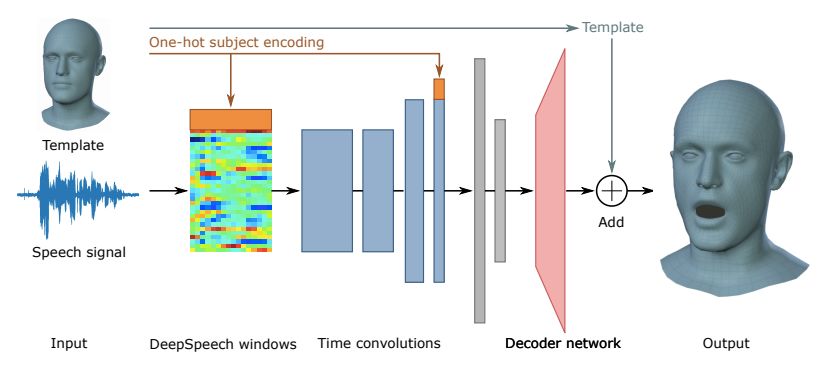
VOCA 网络架构。
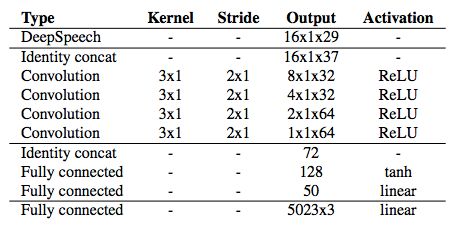
模型架构。
实验
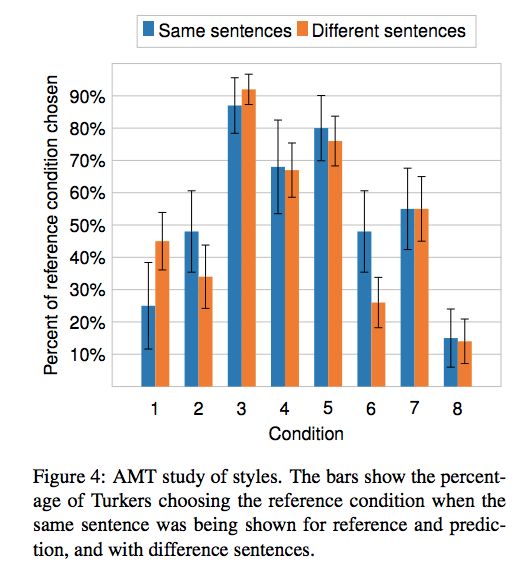

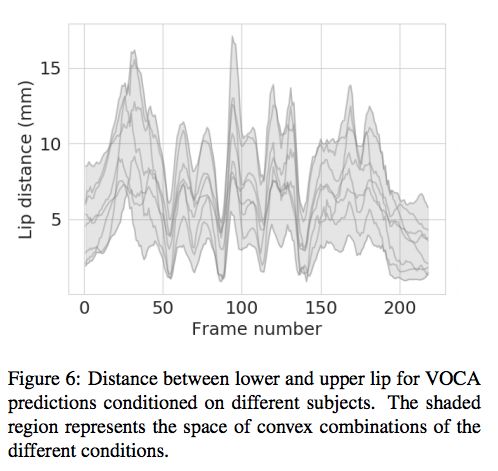

论文 2:Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
作者:Soubhik Sanyal、Timo Bolkart、Haiwen Feng、Michael J. Black
论文链接:
https://ps.is.tuebingen.mpg.de/uploads_file/attachment/attachment/509/paper_camera_ready.pdf
项目页面:https://ringnet.is.tue.mpg.de/
GitHub 页面:
https://github.com/soubhiksanyal/RingNet
摘要:基于单个图像的 3D 人脸形状估计必须对光线、头部姿势、表情、胡须、妆容和遮挡等的变化具备稳健性。稳健性则需要大量野外图像作为训练数据,而它们缺少真值 3D 形状。为了在没有 2D-to-3D 监督的情况下训练网络,我们提出了 RingNet,它可以基于单个图像学习计算 3D 人脸形状。
我们的重要观察是,一个人在不同图像中不管表情、姿势、光线如何,人脸形状都是不变的。RingNet 利用一个人的多张图像自动检测 2D 人脸特征。它使用了一个新型损失函数,当图像中的人物相同时,人脸形状是类似的,当人物不同时,人脸形状是不同的。我们使用 FLAME 模型表示人脸,从而对表情保持不变性。
训练完成后,我们的方法可以基于单个图像输出 FLAME 参数,然后进行动图化。此外,我们还创建了一个新的三维人脸基准数据集(测试集)「not quite in-the-wild」(NoW)。我们评估了目前已有的公开方法,发现 RingNet 的准确率高于那些使用 3D 监督的方法。目前,该研究所用数据集、模型和结果均已开源:https://ringnet.is.tue.mpg.de/。

在没有 3D 监督的情况下,RingNet 学习从单个图像像素到 FLAME 模型 3D 人脸参数的映射。
第一行:来自 CelebA 数据集 [22] 的图像。
第二行:估计到的形状、姿势和表情。

NoW 数据集示例。
方法
该研究提出的 RingNet 架构如下图所示:
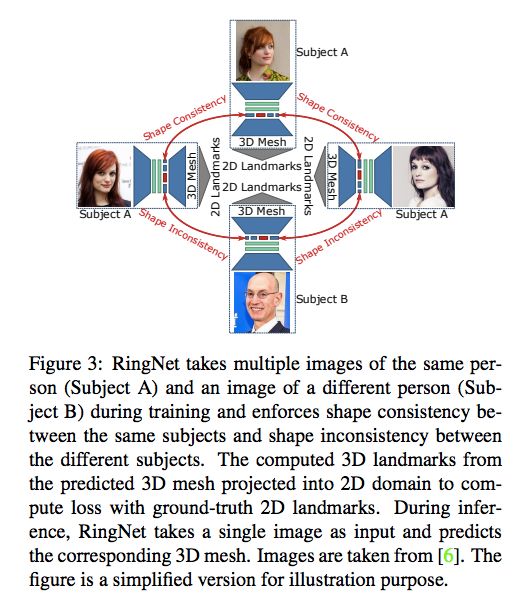
RingNet 在训练过程中使用人物 A 的多张图像和人物 B 的一张图像作为输入,然后识别出相同人物图像之间的形状一致性和不同人物图像之间的形状不一致性。
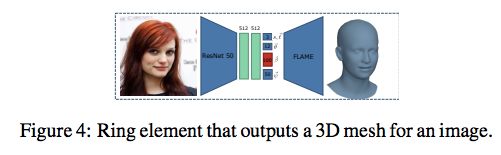
如上图所示,RingNet 被分割成 R 个 ring 元素 e^i=R_i=1,其中 e_i 包括一个编码器和一个解码器,如下图所示:
实验
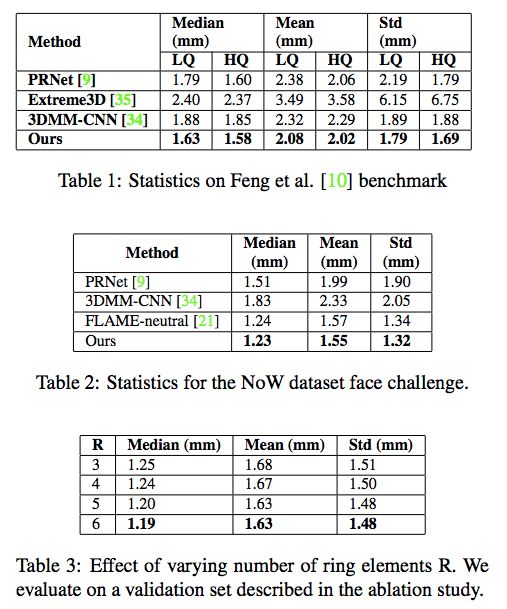
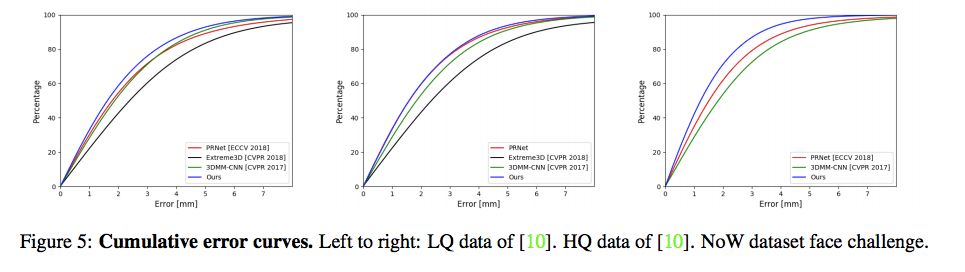
研究者对 RingNet 进行了定量和定性评估,并与已有的公开方法(PRNet (ECCV 2018 [9])、Extreme3D (CVPR 2018 [35])、3DMM-CNN (CVPR 2017 [34]))进行了对比

论文 3:Local Temporal Bilinear Pooling for Fine-grained Action Parsing
作者:Yan Zhang、Siyu Tang、Krikamol Muandet、Christian Jarvers、Heiko Neumann
论文链接:https://arxiv.org/abs/1812.01922
项目页面:
https://ps.is.tuebingen.mpg.de/publications/bilinear2018
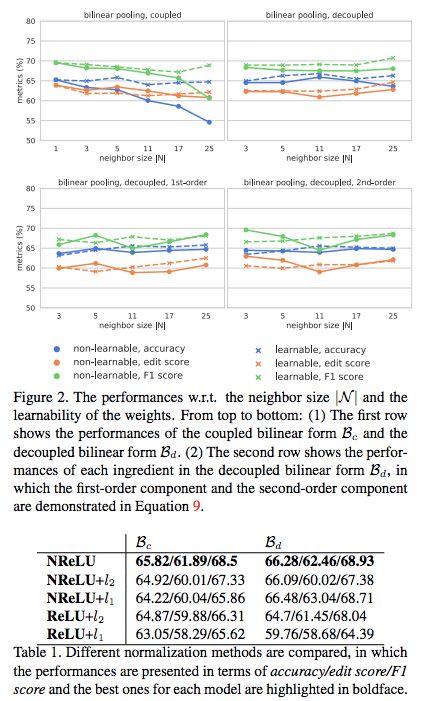
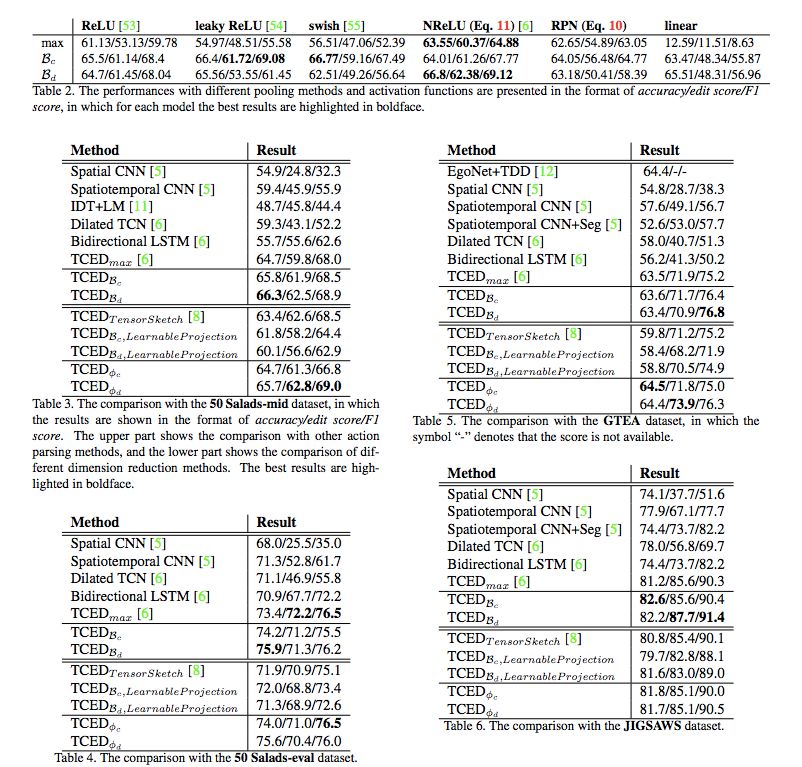
摘要:细粒度时序动作解析在很多应用中都很重要,比如日常活动理解、人类动作分析、手术机器人等需要在较长时间段内具备精密准确操作的应用。这篇论文提出了一种新型双线性池化操作,它被用作时序卷积编码器-解码器网络的中间层。与其他研究不同,该双线性池化操作是可学习的,因此它能够比传统的操作捕捉到更多复杂的局部统计数据。
此外,我们还引入了该双线性池化操作的确切低维表征,使得维度不会因为信息损失或过量计算而降低。我们执行了大量实验,对该模型进行了量化分析,结果表明该模型在多个数据集上展现出优于其他 SOTA 池化方法的性能。
(二级)实验
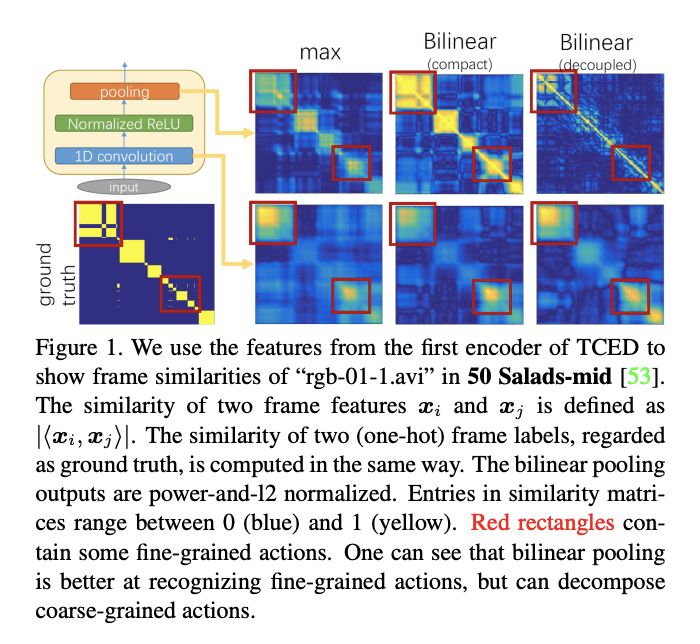

实验所用数据集示例。
(完)
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~






