MySQL高可用数据库内核深度优化的四重定制

作者介绍
王松磊,现任职于UCloud,从事MySQL数据库内核研发工作。主要负责UCloud云数据库UDB的内核故障排查工作以及数据库新特性的研发工作。
近期我们的数据库团队对原生复制的多个方面进行了深度优化,提升了UDB高可用数据库的功能和性能。今天借社群这个平台,跟大家分享一二。
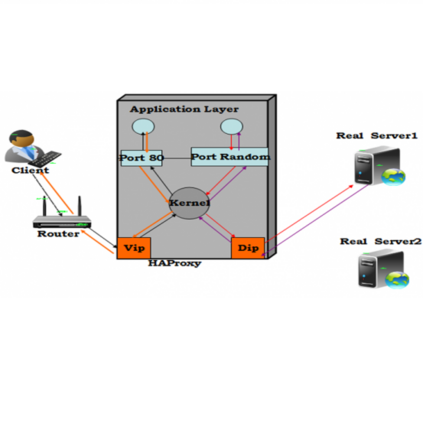
一、UDB高可用数据库架构
UDB以虚拟IP、HAProxy、单节点UDB数据库搭建双节点高可用架构:
双节点的UDB数据库保证数据库数据的全量冗余,同时保证数据库的可用性;
HAProxy在同一时间只连接一个UDB节点,避免多点写入带来的数据冲突问题;
双节点HAProxy保证Proxy的可用性;
虚拟IP在HAProxy发生宕机时通过IP漂移的方式对HAProxy进行切换,用户不需要再次修改IP。
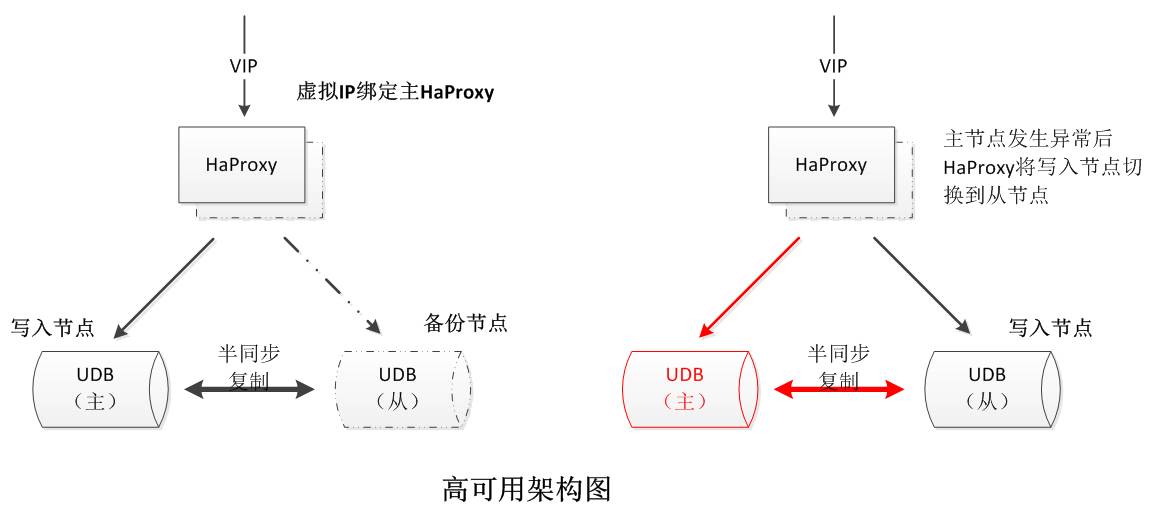
在上述架构中,从节点UDB的数据是否完整、是否与主库保证数据一致性是整个高可用架构的关键,所以用于数据传输的半同步复制起着至关重要的作用。针对原生的半同步复制,我们作了内核层面的深度优化。
二、UDB数据库深度优化
UDB是以开源数据库MySQL Community Server 5.7.16为基线版本,围绕高可用架构做内核深度优化。
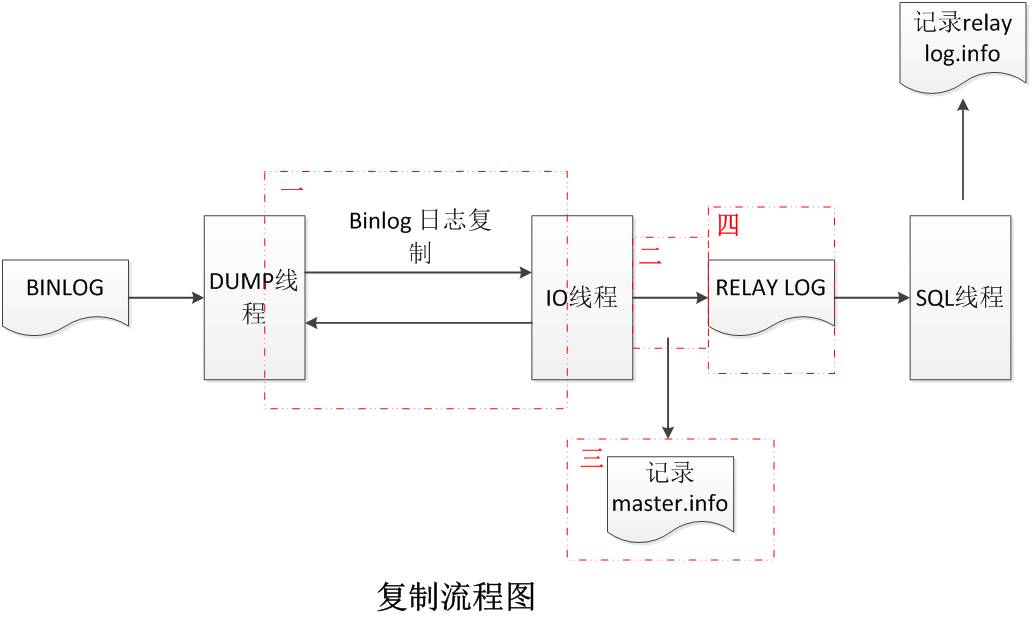
复制流程,如上图所示,主要经过如下几个步骤:
MySQL Server执行SQL成功后,记录binlog;
Dump线程读取binlog后,发送到从机IO线程;
IO线程将接收到的binlog记录到relay log中,同时记录接收进度到master.info中;
SQL读取relay log中的日志内容进行复现,同时记录复制日志的进度到relay-log.info中。
我们在原生复制的基础上做了内核的深度优化,针对上述流程中的部分步骤,在功能和性能上做了改进,使得 UDB更加稳定。
1、Binlog日志复制优化

原生半同步复制存在退化问题,在网络抖动导致超时或者从库追赶主库日志进度时,复制会由半同步复制退化为异步复制。
相比于可靠的半同步复制,异步复制过程中,从库是没有办法感知接收到relay log与主库的binlog是否一致。如果发生宕机,也就没有办法确认从库数据是否与主库一致,是否可以发生数据库切换,这种不确定的情况是我们不希望看到的。
建立双通道复制,在原有半同步复制的基础上增加一条UDB复制通道:
建立一条新的复制通道与原有的复制并行,两条通道互相独立;
新的复制通道不传输数据,只传输主库的SQL执行进度 (binlog的文件名和位置);
新的复制通道使用半同步复制协议,但是不退化,超时后重连,只接收最新的SQL执行进度 ;
新的复制通道不存在追补数据的问题,只要网络正常的情况下,从库永远可以感知SQL的执行进度。
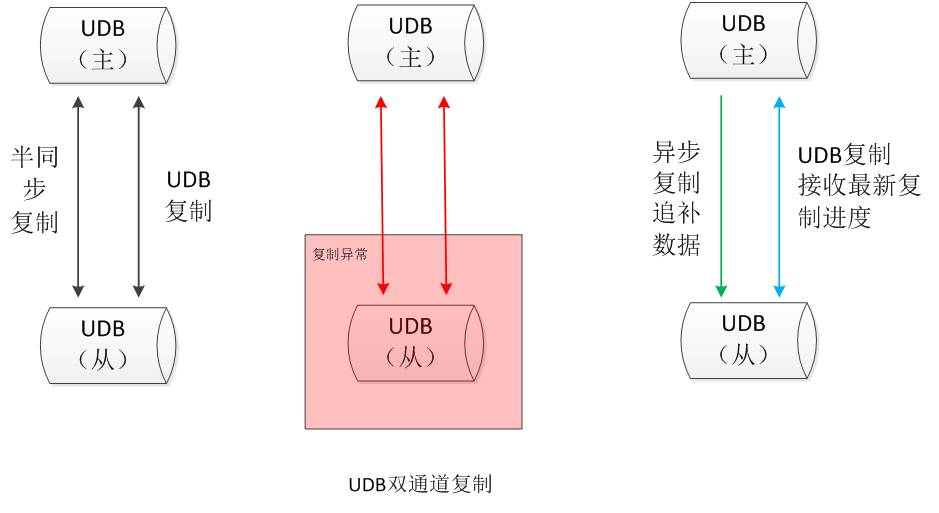
如上图所示,当从库发生宕机或者网络发生故障后,主从复制停止。当从库复制恢复正常后,原生复制通道通过异步复制的方式进行数据追补,UDB复制通道只接收最新的binlog记录位置,这样可以最大限度地减少主从之间异步复制的时间。即在网络可连通的情况下,无论何时发生宕机,从库均知道与主库是否处于数据一致的状态(或者落后了多少)。
2、Relay log文件记录的优化
在MySQL中,binlog是以event为基本单位进行记录,以MySQL 5.7 ROW格式(开启GTID)的binlog为例,一个DML(insert)会以5个event的格式记录到binlog中(其他操作均以一个或者多个event组成,不再一一罗列),分别为:
GTID_EVENT:记录当前事务的GTID
QUERY_EVENT:事务开始
TABLE_MAP_EVENT:操作对应的表
WRITE_ROW_EVENT:插入记录
XID_EVENT:提交事务
全部event组成一个完整的事务,完整的事务才会被SQL线程正确复现到从库上。当前IO线程接收binlog时,是以event为单位进行接收,即接收到一个event,记录到relay log中后再继续接收下一个。这种做法是低效的,也没有充分利用到MySQL本身的文件缓存。
优化IO线程记录relay log的方式,将以event为单位记录,修改为以事务为单位进行记录。合并IO线程小的IO操作,提高IO性能。
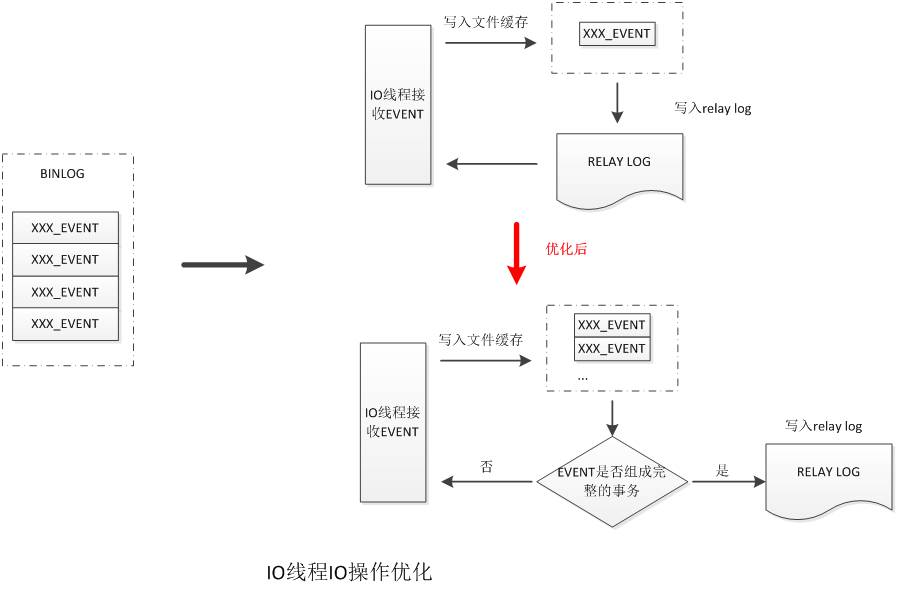
将单个的event写操作合并为多个event统一写操作,将小的IO操作合并成较大的IO操作,提高IO性能。
3、Master.info文件记录的优化
Master.info文件在搭建复制时,记录主库IP、PORT等连接主库的相关信息,在复制过程中,记录IO线程从主库接收到的binlog的文件名和位置,文件和位置会在每次记录relay log成功后更新。
在基于GTID搭建复制后,master.info中记录的binlog文件和位置不再作为复制的依据,所以master.info中记录的binlog的文件和位置不再是有效的数据,也就没有必要每次进行更新。
在IO线程记录relay log成功后,更新master.info文件之前,添加判断。如果开启了GTID并且使用GTID作为复制的依据(auto_position=1),那么不再更新master.info中binlog的文件和位置。
其它的master.info操作仍然保留,如change master、shutdown等操作。
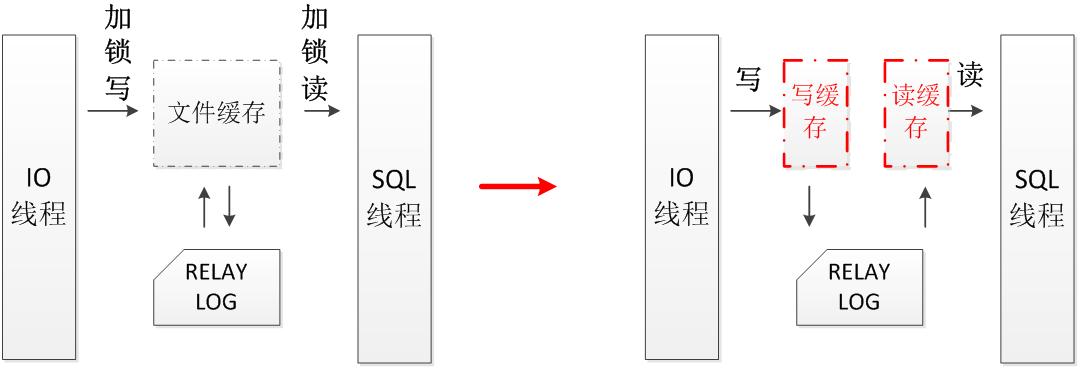
4、Relay log锁的优化
在IO线程和SQL线程复制进度相似的情况下,在操作relay log时,会使用同一块文件缓存,在读写文件缓存时,需要加锁来保证操作的正确性。而IO线程和SQL线程需要频繁地读写这块公共内存,就需要对同一把锁频繁的竞争,从而导致性能下降。
将IO线程和SQL线程对relay log的操作拆分开来,不再使用同一块文件缓存。虽然这样做会导致SQL线程增加一次读IO操作。但是消除了对锁的竞争,大大地提高了IO线程和SQL线程整体的性能。
三、总结
优化后的复制流程图如下:
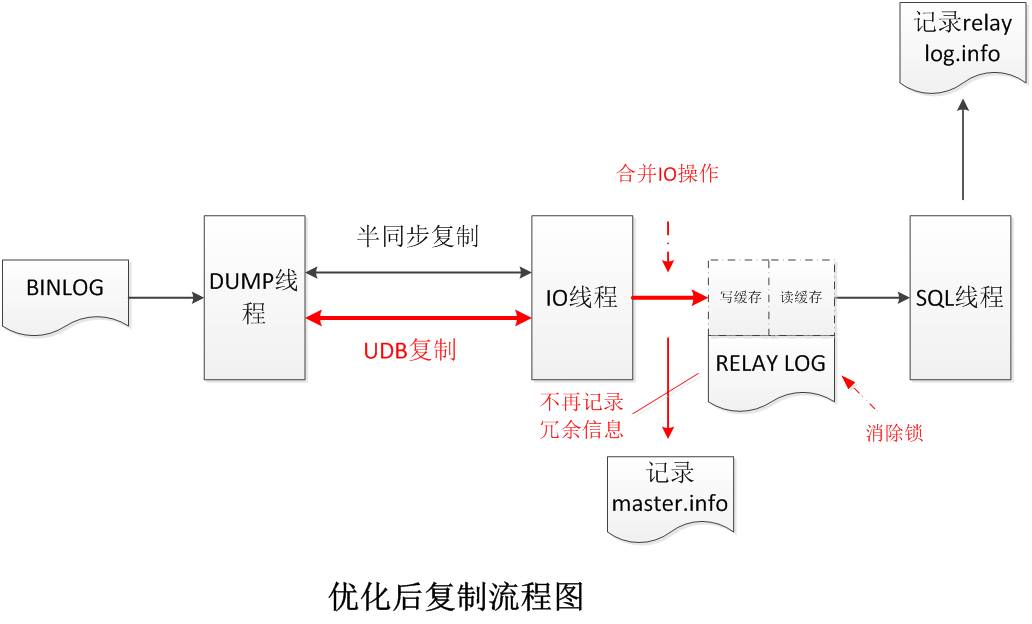
数据库原生复制流程中包括记录binlog、记录relay log、记录master.info、relay-log.info等,针对上述流程中的部分步骤以及其它未列出的优化,在功能和性能上进行改进,UDB高可用数据库在功能和性能上均得到了明显的提升。
-END-
不过瘾?
更多数据库干货
尽在全球敏捷运维峰会北京站!
9月15日 大牛亲授绝技 就差你了
58到家高级技术总监 ||| 京东金融运维负责人
当当网架构总监 ||| 饿了么技术总监
前亚马逊中国区SDM ||| 新炬网络执行副总裁
青岛航空高级架构师 ||| 润乾高级技术总监
爱钱进DBA团队负责人 ||| 京东资深架构师
滴滴出行云架构师 ||| 阿里云数据库开发负责人
美团点评基础服务平台负责人 ||| 携程机票大数据平台Leader
更多大咖在路上

近期热文:
新世界的大门由此打开