论文 | 中文词向量论文综述(三)
| 作者:黑龙江大学nlp实验室研究生刘宗林
导读
这是一篇2017年发表在EMNLP(Empirical Methods in Natural Language Processing)会议上的论文,作者来自于台湾大学 --- Tzu-Ray Su 和 Hung-Yi Lee。
Abstract
这篇论文的出发点也很新颖,中文汉字可以认为是由图形组件组成的,具有丰富的语义信息,基于此,提出了一个新的学习中文词向量的方法,通过图形字符(character glyphs)来增强词的表示,character glyphs通过图像卷积从位图(bitmaps)中编码得来,character glyphs特征加强了word的表示,也提高了character embedding。這篇论文虽然是在繁体中文进行的改进,不过idea同样也可以应用在简体中文中。在 Word Similarity 和 Word Analogy 上验证了其实验效果。
Model
這篇论文的模型参考了CWE模型和MGE模型,模型部分也是分为了几个阶段,第一个阶段是通过convAE从位图中抽取glyph特征,第二阶段是在已有的中文词向量模型中进行改进提高,像CWE,MGW模型,第三阶段是直接使用glyph特征学习中文词向量表示。
Character Bitmap Feature Extraction
前期把字符全部转换成图像,通过convAE对图像抽取特征,convAE的模型结构图如下图所示,通过convAE最后的输出得到的512维的特征,character的glyph特征表示为g_k。
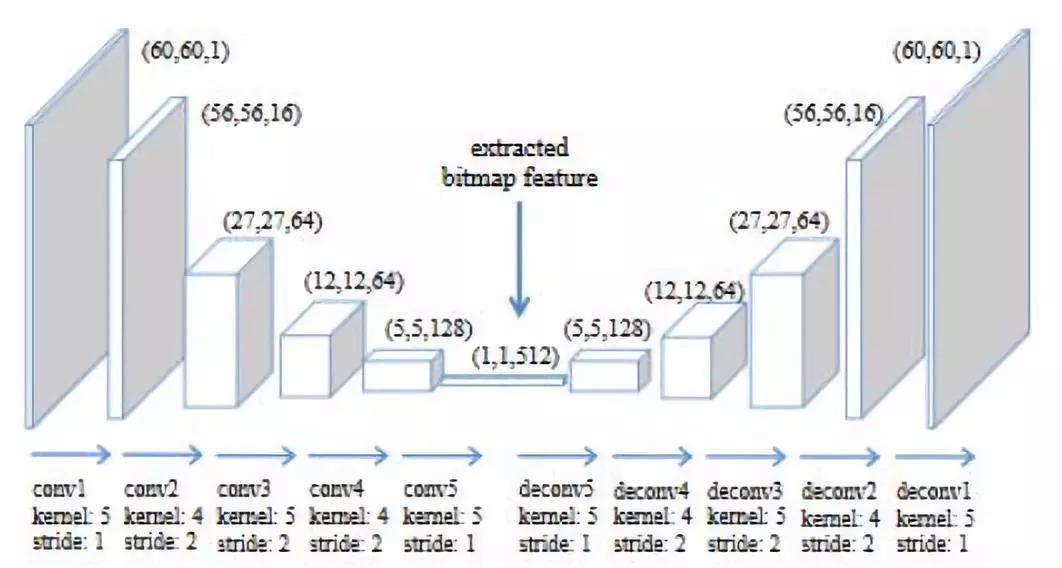
Glyph-Enhanced Word Embedding (GWE)
在這部分对CWE模型做了两个调整分别构建了CWE+ctxG模型和CWE+tarG模型。
Enhanced by Context Word Glyphs --- CWE+ctxG模型
在CWE的基础之上增加了上下文词的glyph特征, 模型图如下所示,
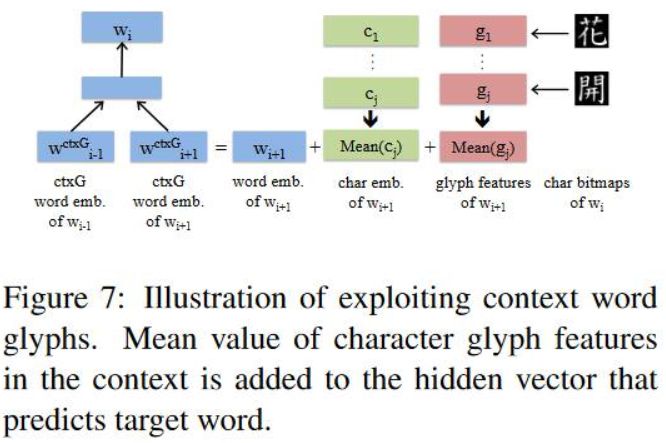
其中,W(ctxG)_i的表示如下,其实计算就是word embedding + avgall(character embedding + glyph embedding),
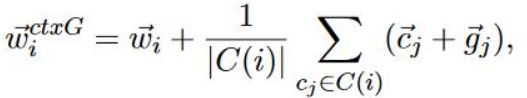
Enhanced by Target Word Glyphs --- CWE+tarG模型
CWE+tarG模型和上文差不多,不过这个加入的是目标词的glyph特征,具体的模型图如下。
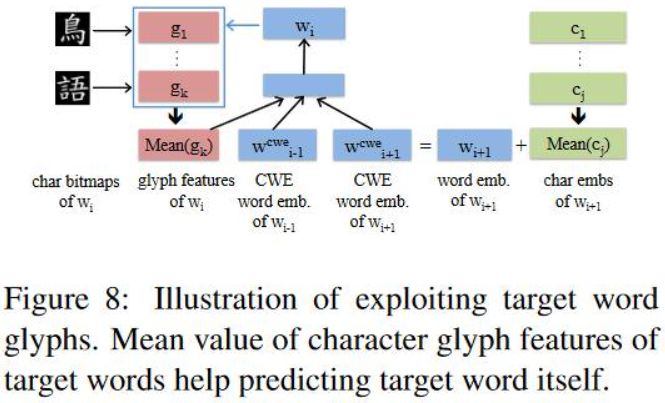
Directly Learn From Character Glyph Features
在这部分仅仅通过glyph特征与RNN循环神经网络构建了两个模型,分别是 RNN-Skipgram 和 RNN-Glove。
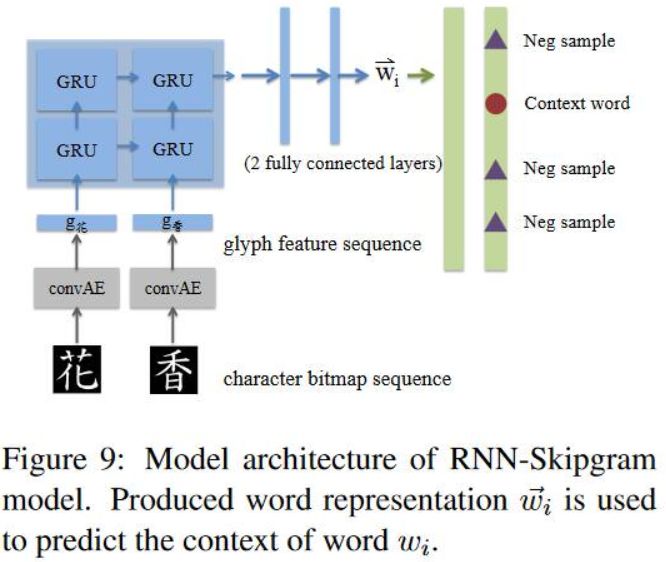
RNN-Skipgram
RNN-Skipgram是把RNN和skipgram结合,通过RNN对glyph特征进行编码,产生隐层表示,然后把隐层表示作为skipgram的输入,进行预测,具体的模型结构图如下图所示。
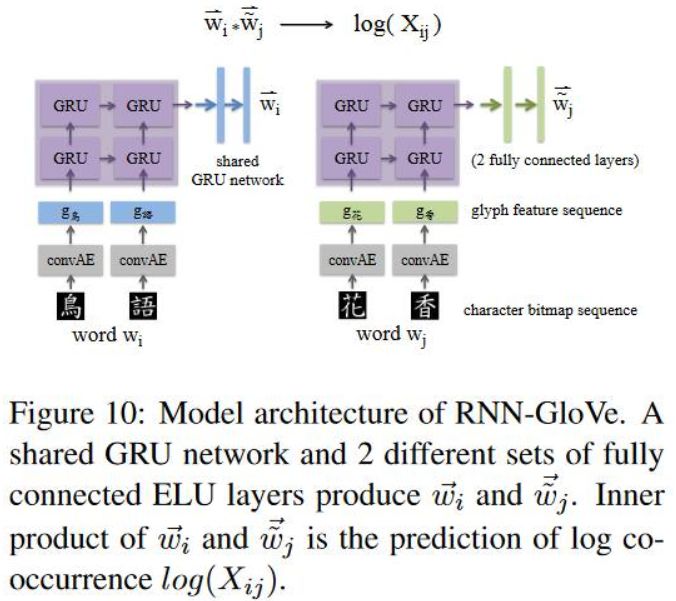
RNN-Glove
通过两个RNN循环神经网络,输入分别是中心词和上下文词的glyph特征,与RNN-Skipgram有微小的差别,输入中心词的网络后连接的是一个共享网络,输入上下文词的网络后面是全连接层,然后两个的输出的内积就是log(X_ij)的预测。
Experiment Result
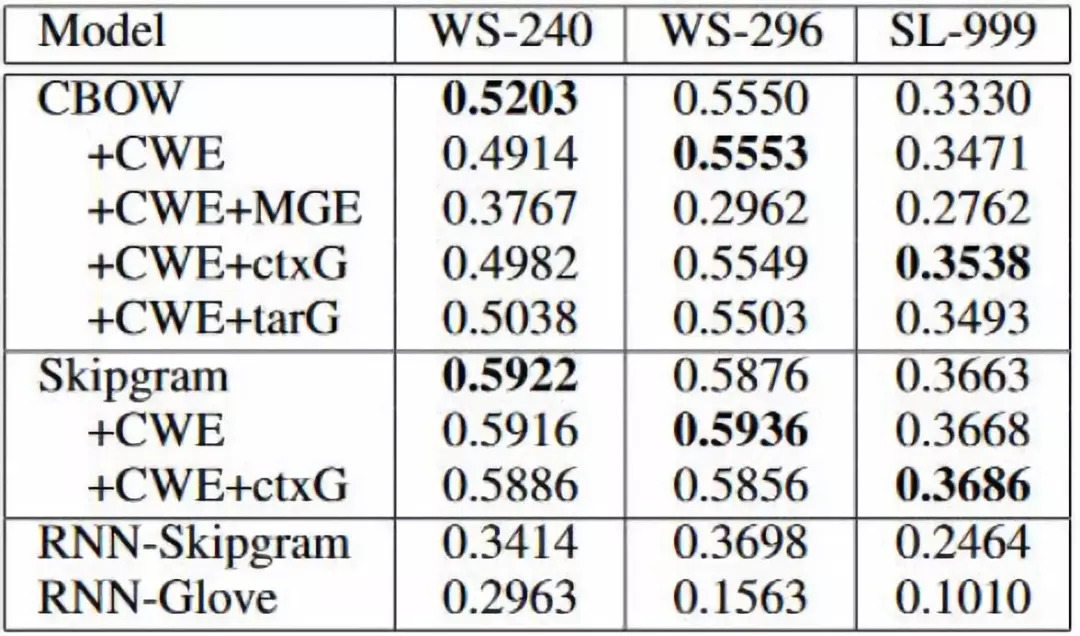
在 Word Similarity 和 Word Analogy 上验证了其实验效果,由于以前的评测文件都是基于简体中文的,他们对其手工翻译成繁体中文的数据集进行评测。
Word Similarity采用的评测文件是wordsim-240,wordsim-296,由于中文简体和繁体在翻译过程中产生的歧义性,他们手工构建了SimLex-999评测文件,并把SimLex-999作为第三个评测文件,具体的实验结果如下图。
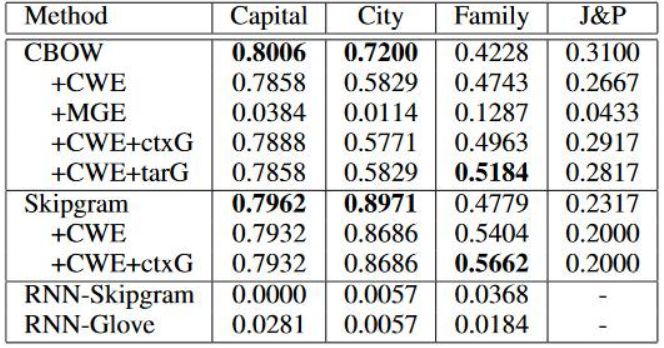
Word Analogy采用的是Chen 2015年构造的评测文件,但是增加了一个Job&Place,具体的实验结果如下图。
论文来源
这是一篇2017年发表在EMNLP(Empirical Methods in Natural Language Processing)会议上的论文,作者来自于香港科技大学 --- Jinxing Yu。
Abstract
与西方语言不同,中文汉字包含了丰富的语义信息,这篇论文提出了一个联合学习word,character和更加细粒度的subcharacter的方法来学习word embedding。在Word Similarity 和 Word Analogy任务上验证其优越性。
Model
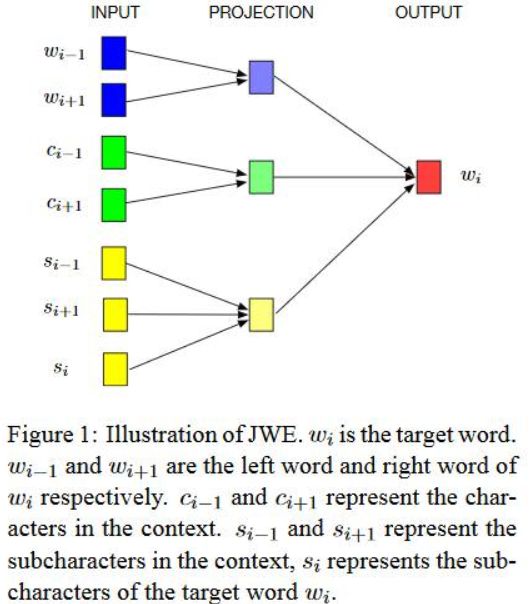
提出了一个联合( Chinese words, characters, and subcharacter components)学习word embedding的模型,称之为JWE模型,JWE模型也是基于CBOW来进行的完善,模型结构如下图。根据下图,只是在输入端多了一些改变,w_i代表目标词;w_i+1,w_i-1代表上下文词;c_i-1,c_i+1代表上下文词的character;s_i+1,s_i-1代表上下文词的subcharacter(radical),s_i代表目标词的subcharacter(radical)。
损失函数有所不同,为三者的相加,具体公式如下,其中h_i1,h_i2,h_i3分别代表context word,context character,context subcharacter,h_i1,h_i2,h_i3分别取三者的平均值作为表示,例如h_i1如下图2所示,v_wi代表的是context word。
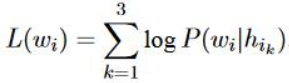
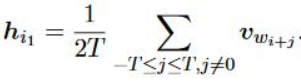
Experiment Result
在 Word Similarity 和 Word Analogy 上验证了其优越性。
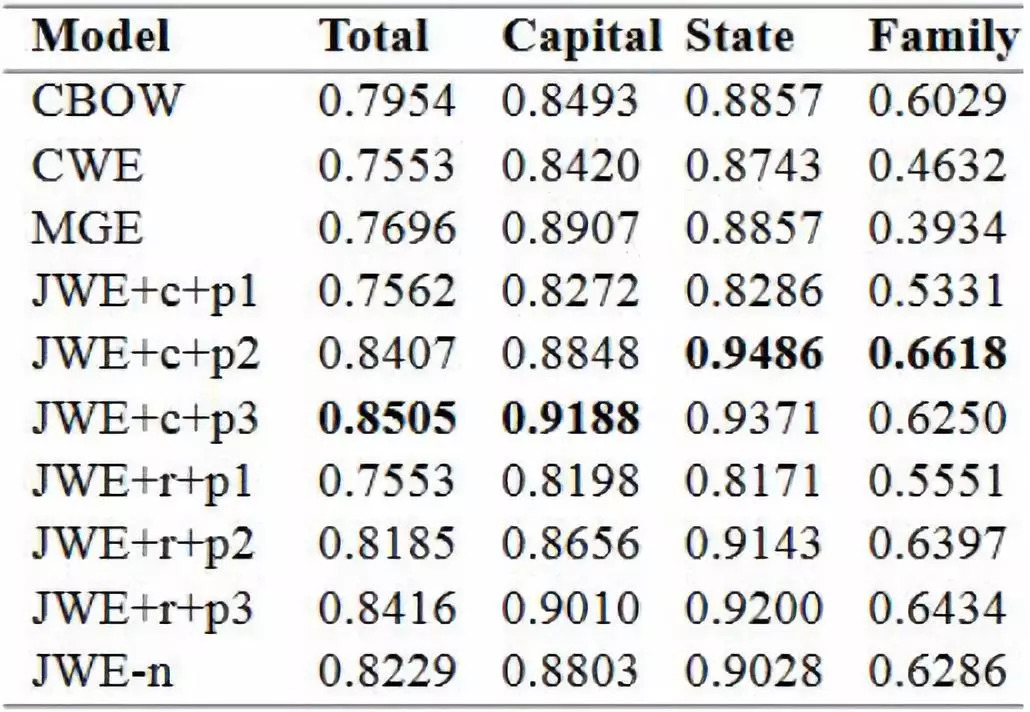
论文在模型上尝试了不同的组合来进行实验,具体如下:
+c :代表的是component特征
+r :代表的是radical特征
+p :代表的是subcharacter components 特征
+p1 :代表的是使用上下文词的subcharacter components 特征
+p2 :代表的是使用目标词的subcharacter components 特征
+p3 :代表的是使用上下文词和目标词的subcharacter components 的特征
-n :代表的是仅仅使用character
具体来说上面提到的component,radical(偏旁),subcharacter,比如照这个汉字,它的radical是 灬,component是日、刀、口,subcharacter是subcharacter components,应该是所有的components(包含radical)。
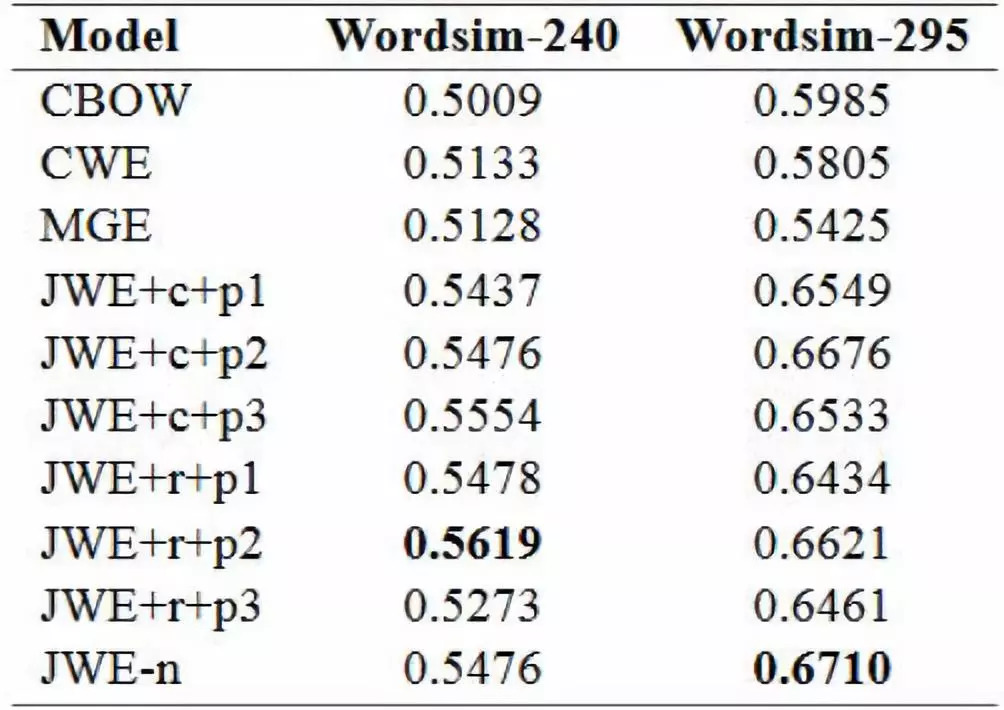
Word Similarity采用的评测文件是wordsim-240,wordsim-295,wordsim-296移除了评测文件中没有出现在训练语料中的一个词,变为评测文件wordsim-295,具体的实验结果如下图。
Word Analogy采用的是Chen 2015年构造的评测文件,具体的实验结果如下图。
[1] Learning Chinese Word Representations From Glyphs Of Characters
[2] Joint Embeddings of Chinese Words, Characters, and Fine-grained Subcharacter Components


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流





