DeepMind 和阿尔伯塔大学联合成立的人工智能实验室未来几年要研究什么?
2017 年,DeepMind 在加拿大的 Edmonton 成立了其首个英国之外的人工智能研究实验室,并和阿尔伯塔大学大学紧密合作,成立了「DeepMind Alberta」,由强化学习先驱 Richard S. Sutton、阿尔伯塔大学教授 Michael H. Bowling、助理教授 Patrick M. Pilarski 领导。
![]()
从左到右:Richard Sutton、Michael Bowling 和 Patrick Pilarski
现在,三位领导者联合发表论文阐述 DeepMind Alberta 在未来一段时间内关于人工智能的计划,即 Alberta Plan。Alberta Plan 是一项面向计算智能的 5-10 年长期规划,旨在填补我们目前对计算智能的理解空白。随着计算智能的发展,它必将深刻影响我们的经济、社会和个人生活。
![]()
DeepMind Alberta 致力于理解和创建与复杂世界交互并预测和控制其感官输入信号的长寿命计算智能体。智能体的初始设计要尽可能简单、通用和可扩展,并能与复杂的世界长期交互。
这就要求智能体具备多种功能:为了控制输入信号,智能体必须采取行动;为了适应变化世界的复杂性,智能体必须不断学习;为了快速适应,智能体需要用一个学习模型来规划世界。
一是描述了 DeepMind Alberta 对人工智能研究的愿景及其关于智能的计划和优先工作;
二是描述这一愿景可能的展开路径以及 DeepMind Alberta 将探索的研究问题和项目。
![]()
论文地址:https://arxiv.org/abs/2208.11173
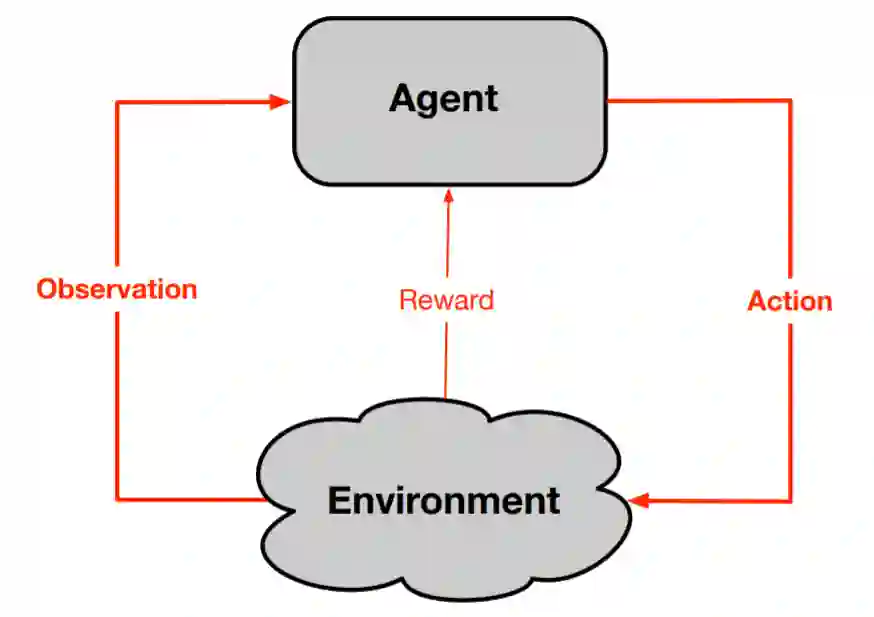
在 Alberta Plan 的研究愿景中,智能体从其环境中接收观察和奖励信号,并试图通过其动作控制这些信号。这是高级强化学习的标准视角。
![]()
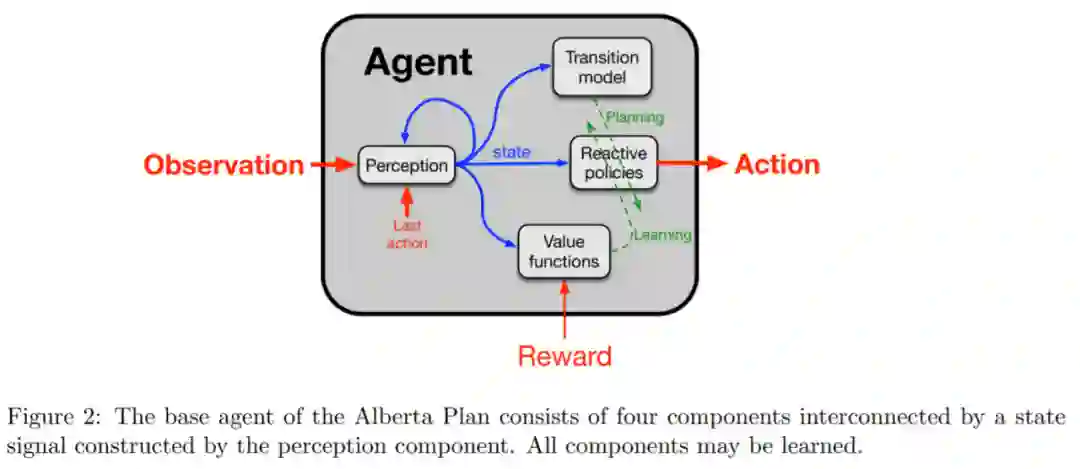
本文智能体的设计遵循标准或者说是基础智能体的设计,如图 2 所示,其被认为是具有 AI、心理学、控制理论、神经科学和经济学的「智能智能体通用模型」。该基础智能体包含四个组件:
感知组件
能够更新智能体对过去经验或状态的总结,之后这个更新会被其他组件使用;
反应策略组件
包括智能体所做的策略,依据此,智能体做出动作反应,并根据奖励更新动作。感知和主要策略协同工作,将观察映射到动作。每个策略都有一个对应的价值函数,所有值函数的集合构成
值函数组件
。
![]()
基础智能体的第四个组件是
转换模型组件
,该组件从观察到的行为、奖励和状态中学习,而不涉及观察。智能体学习完,转换模型就可以采取一种状态和一种动作,并预测下一种状态和下一种奖励。
一般来说,该模型可能在时间上是抽象的,这意味着智能体不采取动作,而是利用选项,如利用策略和终止条件等,并预测选项终止时的状态以及累积的奖励。
转换模型用于设想智能体采取动作 / 选项后可能出现的结果,然后由价值函数评估以改变策略和价值函数本身,这个过程称为规划。规划是连续的且在时间上是统一的,智能体中的每一个 step 都会有一定数量的规划,也许是一系列小的规划,通常来讲规划不会在一个时间步内完成,因此与智能体 - 环境交互相比速度会很慢。
规划是一个连续的过程,在后台异步运行,运行过程不会干扰前三个组件。在每一个 step 中,新的观察都必须经过感知处理以产生状态,然后由主要策略处理以产生该时间步的动作。价值函数必须在前台运行,以评估每个时间步的新状态以及采取前一个动作的决定。
AI 中一个永恒的难题是「部分和整体」的关系。一个完整的 AI 系统必须建立在有效的算法之上,但问题是,在组装出一个完整的系统之前,我们无法确切地知道需要哪些核心算法。因此必须同时处理系统和组件算法,也就是部分和整体的工作。但这样做产生的结果是浪费精力,但又必须执行。
步骤 1. 表示 I:具有给定特征的连续监督学习。在泛化到更复杂的设置之前,智能体先在最简单的设置下运行并解决问题。步骤 1 解决的问题是对表示的连续学习和元学习,例如如何在长时间连续学习的同时还能快速、稳健和高效地学习。
步骤 2. 表示 II:发现监督特征。步骤 2 的重点是创建和引入新特征。主要关注的问题包括如何从现有特征构建新特征,以最大化新特征的潜在效用和实现该效用的速度,同时不牺牲临时性能。
步骤 3. 预测 I:连续 GVF 预测学习。重复上述两个步骤以进行顺序实时设置。在这一步骤中首先使用给定的线性特征,然后使用特征查找。新特征不仅包括非线性组合,还包括旧信号和迹线的结合。
步骤 4. 控制 I:连续 actor-critic 控制。重复以上三个步骤进行控制。
步骤 5. 预测 II:平均奖励 GVF 学习。这里的主要思想是将对 GVF 的一般预测学习算法扩展到平均奖励。
步骤 6. 控制 II:连续控制问题。这里需要一些连续问题来测试用于学习和规划的平均奖励算法。目前有 River Swim、Access-control Queuing 等算法。
步骤 7. 规划 I:为平均奖励标准开发基于异步动态规划的增量规划方法。
步骤 8. Prototype-AI I:具有连续函数逼近的基于模型的单步强化学习(RL)。Prototype-AI I 将基于平均奖励 RL、模型、规划和连续非线性函数逼近。通过结合一般连续函数逼近,Prototype-AI I 将超越过去基于 Dyna 的工作,但仍将限于单步模型。换句话说,Prototype-AI I 将是一个集成架构。
步骤 9. 规划 II:搜索控制和探索。在规划 II 步骤中,我们将开发了规划控制。规划被视为具有函数逼近的异步值迭代。控制规划过程的早期工作
将包括优先扫描(sweeping)和小型备份,并且研究团队已经进行了一些尝试。
步骤 10. Prototype-AI II:STOMP 进程。研究团队以一种特殊的方式引入时间抽象,即子任务(SubTask)、选项(Option)、模型(Model)和规划(Planning )——STOMP 进程。其中,规划的选项成为反馈循环的一部分,以评估所有早期步骤。
步骤 11. 原型 - AI III:Oak。Oak 架构是 Prototype AI 2 的一个小修改,引入了一个可选键盘。键盘的每个键都引用了基于子任务的选项来实现相应的功能。
步骤 12. 原型 - IA:智能放大。一个智能应用 (IA,intelligence applification) 的演示,其中原型 - IA 2 智能体可以同时兼顾速度与决策能力。
2021 图灵奖得主、中外院士领衔 40+ 重磅嘉宾,开发者论坛、技术 Workshop、云帆奖、黑客马拉松 4 大精彩版块…… 9 月 3 日,「WAIC 2022 · AI 开发者日」将重磅登场, 以「 AI 开发者所真正关注的」为主题,集中展示本年度人工智能领域最前沿技术成果和最新实践应用进展,为开发者呈现一场集学习、实战、社交为一体的技术嘉年华。
AI 开发者论坛观众报名已经开启,扫描下图二维码即刻报名。👇
![]()
投稿或寻求报道:content@jiqizhixin.com