近日,支付宝天筭安全实验室在 CVPR FGVC(细粒度视觉分类)workshop 举办的植物病理学挑战赛(Plant Pathology Challenge)中夺冠。本文介绍了冠军队伍及其解决方案。
CVPR(国际计算机视觉与模式识别会议)是由 IEEE 主办的一年一度的世界顶级计算机视觉学术性会议。大会包含多个 workshop,以及对应的许多计算机视觉算法竞赛。
![]()
其中 FGVC(细粒度视觉分类)workshop 也举办了多项竞赛,如 Plant Pathology Challenge。
该竞赛的任务是:
根据苹果树叶子图片区分不同种类的疾病,提高疾病分类的准确率,从而减少化学药品的滥用,及其导致的耐药病原体菌株出现的问题。
其带来的效果是显性地减少种植成本投入、错误疾病诊断带来的经济损失,以及不必要的环境污染。
![]()
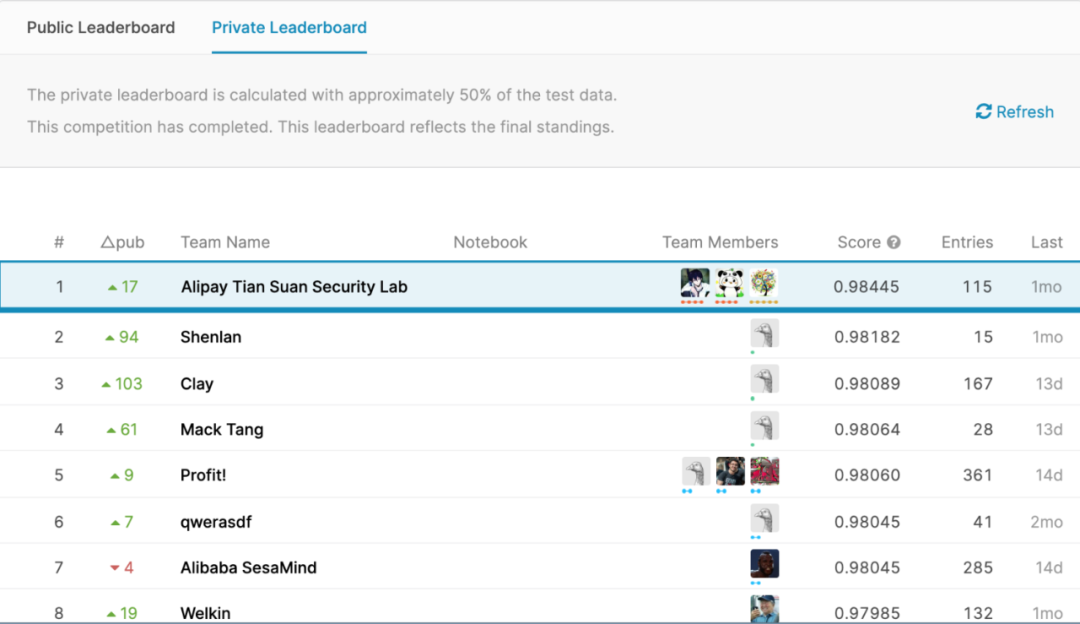
本次竞赛共有 1317 支队伍参加,支付宝天筭安全实验室获得冠军,并与其他队伍拉开较大差距。
![]()
本次竞赛数据集包含 1821 张训练图像和 1821 张测试图像,每张图像有四种可能的标签(健康、锈病、痂病、同时拥有两种疾病),这四种类型的比例为 6:6:6:1,存在数据不平衡问题,且数据集中有一部分不准确标签。
因此如何解决数据量少和标签不准确问题,对所有参赛团队都是个挑战。
赛题采用 mean column-wise ROC AUC 作为评价指标来衡量模型的性能,该指标的具体计算方式为各类标签 ROC AUC 值的平均。
如前所述,该竞赛数据集存在数据量少以及标签不准确的问题。为此,支付宝天筭安全团队采用了数据增强和知识蒸馏技术。
由于竞赛数据集相对较小,直接使用原始数据进行训练会导致模型存在过拟合的风险。为了更好地增加模型鲁棒性,天筭安全团队对数据集进行了如下一系列数据增强操作。
![]()
![]()
![]()
![]()
![]()
此外,该团队还使用了一些高斯模糊等肉眼不容易区分的增强操作,这些操作极大地丰富了训练数据集,让模型尽可能地学习更多的特征,以增强其泛化程度。
from albumentations import ( Compose, Resize, OneOf, RandomBrightness, RandomContrast, MotionBlur, MedianBlur, GaussianBlur, VerticalFlip, HorizontalFlip, ShiftScaleRotate, Normalize,) train_transform = Compose( [ Resize(height=image_size[0], width=image_size[1]), OneOf([RandomBrightness(limit=0.1, p=1), RandomContrast(limit=0.1, p=1)]), OneOf([MotionBlur(blur_limit=3),MedianBlur(blur_limit=3), GaussianBlur(blur_limit=3),], p=0.5,), VerticalFlip(p=0.5), HorizontalFlip(p=0.5), ShiftScaleRotate( shift_limit=0.2, scale_limit=0.2, rotate_limit=20, interpolation=cv2.INTER_LINEAR, border_mode=cv2.BORDER_REFLECT_101, p=1, ), Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0), ])
![]()
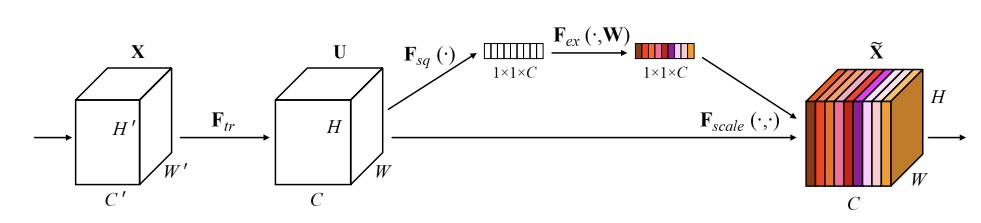
该团队采用 seresnext50 作为训练的模型框架,其中前缀 se 表示 squeeze and excitation 过程。该过程的原理是:通过控制 scale 的大小,把重要的特征增强、不重要的特征减弱,原理和注意力机制相同。其目的是让提取的特征指向性更强,从而更好地对 FGVC 任务中的精细特征做识别。
![]()
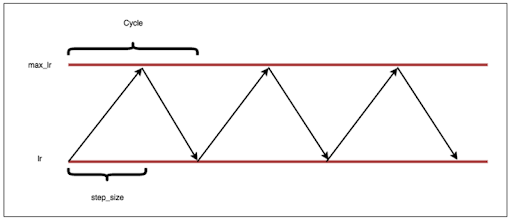
该团队采用 adam + cycle learning rate 的学习策略进行模型训练。
这种学习策略的优势是:通常不会产生太多过拟合,也不需要仔细调参。
误差分析是提升深度学习模型性能中十分重要的一环。当模型训练完成后,如何对模型性能进行改进才是提分的关键点。
该团队通过热力图的方式将模型对图片关键识别部位提取出来,这样就能很清晰地了解模型看到了哪些部位才将图片识别为对应的类别。把识别错误的图片进行分析后,就可以知道模型训练的整体环节中有哪些可以被改进。
![]()
![]()
![]()
由于有些疾病较难区分,导致标签存在一些不准确的情况,这给训练增加了一定的难度,模型很可能被不准确的标签误导。
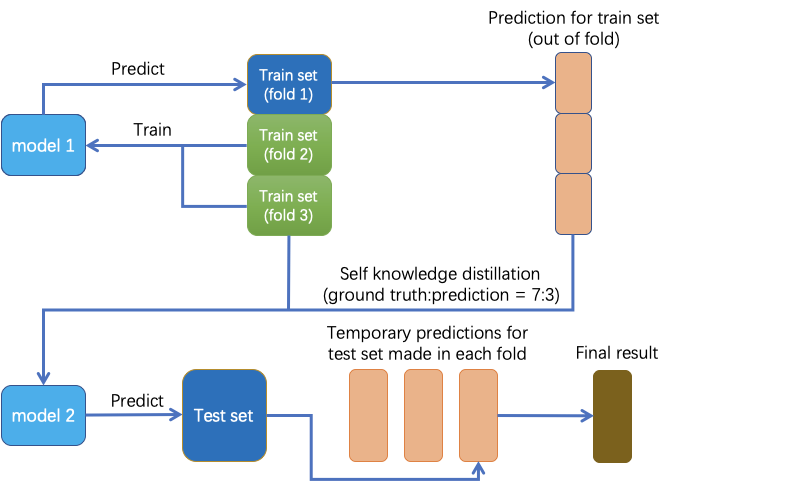
为了应对这种情况,支付宝团队采用了自蒸馏的方式来解决该问题:训练五折模型,然后将五折的验证集组成 out-of-fold 文件,最后将 out-of-fold 的结果和 ground truth label 按 3:7 混合作为训练新模型的标签。简单来说,就是给每个软化前的标签赋予一定的概率,从而降低模型训练的难度 。
![]()
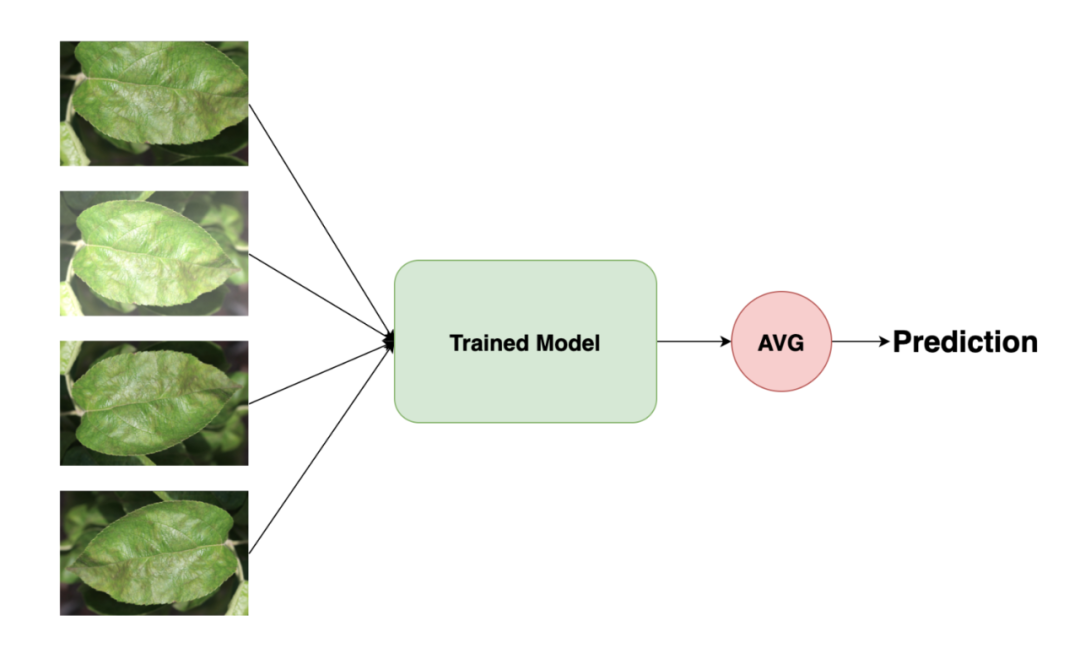
在最后提交成绩的阶段,该团队采用了 TTA(Test Time Augmentation)策略,对预测样本都执行了一定的数据增强,然后对这些增强的预测值做平均加权,这也为模型结果起到了一定的提升作用。
![]()
细粒度图像分类是计算机视觉领域中极具挑战的方向,但这一方向在实际应用中对于提升交易风险辨识度有很大的帮助。支付宝天筭安全团队在此次竞赛中所使用的原创模型,为用户交易纠纷举证、网站内容风险识别等场景的技术优化带来了新思路。
该技术研究团队来自支付宝天筭安全实验室,隶属于支付宝安全实验室。研究方向重点围绕智能风控和反欺诈技术,探索安全领域的机器学习等前沿问题。此次该团队不仅在 Kaggle 挑战赛登顶,在全球仅 180 位 Kaggle Grandmaster 中,天筭安全实验室占了 4 位。该团队还在 2019 年 AI 数据挖掘领域的「世界杯」KDD 比赛中夺冠,在 1600 余支参赛队伍中,碾压了包括谷歌、微软、Facebook 在内的全球强队。
安全科技是支付宝的重要科技实力之一,该实验室是支付宝「你敢付我敢赔」承诺的重要技术力量。支付宝自研智能风控引擎 AlphaRisk 拥有近 500 条量化策略、100 个风险模型,对用户交易支付进行 7*24 小时的实时风险检测扫描及保护,能在数亿交易中精准识别用户的账户异常行为,是全球最先进的风控系统之一。在其保护下,支付宝交易资损率不到 0.00001%,远低于行业平均水平,交易风险率低至千万分之 0.64,领先国际同行 PayPal 2.3 万倍。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com