| 极市线上分享 第61期 |
一直以来,为让大家更好地了解学界业界优秀的论文和工作,极市已邀请了超过60位技术大咖嘉宾,并完成了60期极市线上直播分享,往期分享请前往bbs.cvmart.net/topics/149 或直接阅读原文,也欢迎各位小伙伴自荐或推荐更多多优秀的技术嘉宾到极市进行技术分享,与大家一起交流学习~~
7月17日(星期五)—7月19日(星期日),极市将独家直播由山东大学主办的“可视计算”学术专题报告。关注“极市平台”公众号,回复“61”可获取免费直播链接。
山东大学邀请了国内外的知名学术专家,就各自领域的基础理论、应用前景与前沿技术等方面进行专题报告,该直播内容也将在极市平台进行直播回放。
时间:2020年7月17日 (周五)—2020年7月19日(周日)
主题
山东大学“可视计算”学术专题报告
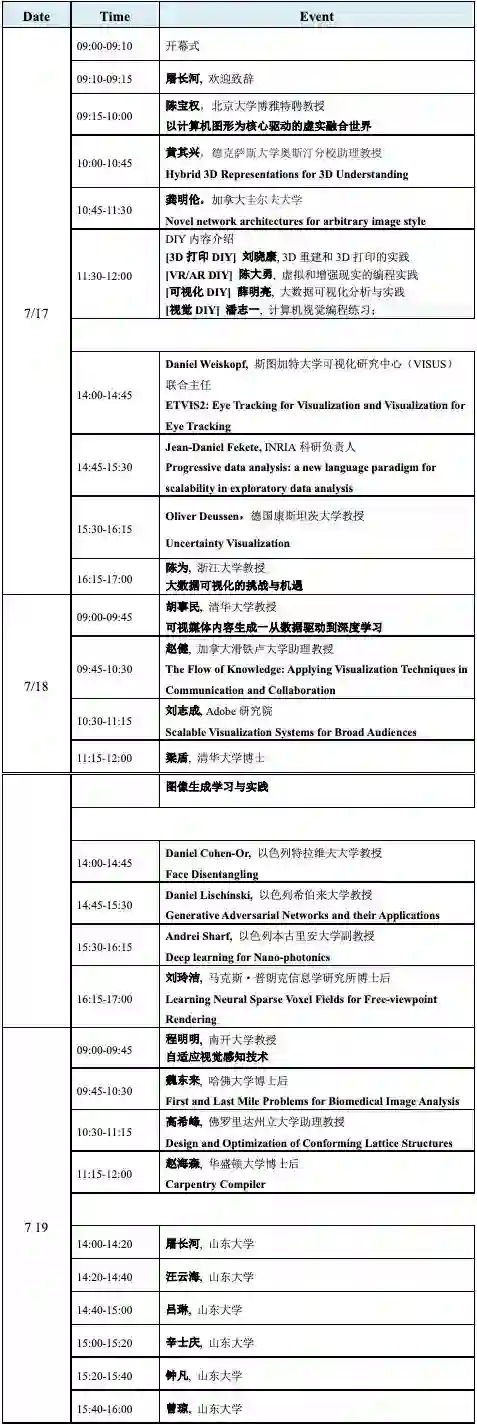
![]()
摘要:
新冠疫情期间的社交距离加速了虚拟人和机器人服务,相关技术发展已经形成脉络体系,催生一个虚实融合的未来世界,人类、虚拟人、机器人都将共生其中。这听似科幻未来的背后,是以计算机图形学为核心,联合其他相关学科所形成的交叉学科体系,实现对现实世界的表象和规律的高逼真度模拟计算与真实感呈现,构成新一代人工智能发展的基础,推动新的社会变革。
➤讲座2:Hybrid 3D Representations for 3D Understanding
摘要:Choosing suitable data representations is one of the most critical topics when installing machine learning on 3D data. Instead of exploring a single representation, there is great potential in integrating multiple representations. Such hybrid representations exhibit advantages in uncertainty reduction, adaptative feature selection, and self-supervision, among others. This talk introduces several recent results in pose estimation, object detection, and 3D scene synthesis. In particular, we provide an analysis on the benefits of hybrid representations for over-parameterized neural networks.
➤讲座3:Novel network architectures for arbitrary image style transfer
摘要:Style transfer has been an important topic in both Computer Vision and Graphics. Since the pioneer work of Gatys et al. demonstrated the power of stylization through optimization in deep feature space, a number of approaches have been developed for real-time arbitrary style transfer. However, even the state-of-the-art approaches may generate insufficiently stylized results under challenging cases. Two novel network architectures are discussed in this talk for addressing the issues and delivering better performances.
We first observe that only considering features in the input style image for the global deep feature statistic matching or local patch swap may not always ensure a satisfactory style transfer. Hence, we propose a novel transfer framework that aims to jointly analyze and better align exchangeable features extracted from the content and style image pair. This allows the style features used for transfer to be more compatible with content information in the content image, leading to more structured stylization results.
Another observation is that existing methods try to generate stylized result in a single shot, making it difficulty to satisfy constraints on semantic structures in the content images and style patterns in the style images. Inspired by the works on error-correction, we propose a self-correcting model to predict what is wrong with the current stylization and refine it accordingly in an iterative manner. For each refinement, we transit the error features across both the spatial and scale domains and invert the processed features into a residual image.
➤讲座4:ETVIS2: Eye Tracking for Visualization and Visualization for Eye Tracking
报告人:Daniel Weiskopf(斯图加特大学可视化研究中心(VISUS)联合主任
)
摘要:There is a growing interest in eye tracking as a research method and technology in many communities, including the visualization research community, but also in computer graphics, human-computer interaction, applied perception, psychology, or cognitive science. Progress in hardware and the reduction of costs for eye tracking devices have made this analysis technique accessible to a large population of researchers. Recording the observer’s gaze can reveal how dynamic graphical displays are visually accessed and which information are being processed. Such gaze information is available in real time so that eye tracking plays a role as a means of providing quick responses to user interaction and viewing behavior, supporting gaze-contingent displays and visualization. However, the analysis and visualization of spatiotemporal gaze data become challenging factors in this emerging discipline. I discuss the relationship between eye tracking and visualization from two angles: (1) How can eye tracking help understand how users work with visual interfaces, thus serving as a basis to improve computer-based visualization? (2) How can visualization facilitate the analysis of gaze recordings? I argue that it is useful to combine both perspectives, targeting VIS4VIS (visualization for visualization).
➤讲座5:Progressive data analysis: a new language paradigm for scalability in exploratory data analysis
报告人:Jean-Daniel Fekete(INRIA科研负责人)
摘要:Exploring data requires a short feedback loop, with a latency of at most
10 seconds because of human cognitive capabilities and limitations. When
data becomes large or analyses become complex, sequential computations
can no longer be completed in a few seconds and interactive exploration
is severely hampered. This talk will describe a novel computation
paradigm called Progressive Data Analysis that brings at the programming
language level the low-latency guarantee by performing computations in a
progressive fashion. Moving this progressive computation at the language
level relieves the programmer of exploratory data analysis systems from
i
mplementing the whole analytics pipeline in a progressive way from
scratch, streamlining the implementation of scalable exploratory
analytics systems. I will d scrib
e the new paradigm, report on novel
experiments showing that human can cope effectively with progressive
systems, show demos using a prototype implementation called
ProgressiVis, explain the requirements it implies through exemplar
applications, and present opportunities and challenges ahead, in the
domains of visualization, visual analytics, machine-learning, and databases.
➤讲座6:Uncertainty Visualization
报告人:Oliver Deussen(德国康斯坦茨大学教授)
摘要:The visualization of uncertainty is a challenging aspects of data visualization. A data point drawn in a specific location is most of the time interpret as a precise representation of the true data value; it is perceptually hard to indicate that it could also lie somewhere else. But almost all data sets incorporate uncertainty and variance and thus it is important to develop specific methods for uncertainty visualization. In my talk I will give some examples from flow visualization, traffic data, Biology and the stock market.
摘要:理解和利用数据是信息技术发展的迫切需求,数据可视化为人类洞察数据的内涵、理解数据蕴藏的规律提供了重要的手段和高效的人机界面,是和数据分析、数据挖掘等方法的有效补充,在一些重要场合将起到不可替代的作用。本次报告将介绍大数据可视化的基本概念以和内涵,阐述人工智能与可视化的融合趋势,并展示中国唐宋人文数据可视化、图模型的可视化、隐私保护的可视化等案例。
摘要:可视媒体内容生成是计算机图形学的重要研究分支,强调与视觉感知、人工智能的结合,自动或交互地合成逼真图像视频内容,为数字媒体、城市街景、虚拟现实等领域提供内容支撑。从历史发展来看,可视媒体内容生成经历了从数据驱动到深度学习的方法演变。本报告将回顾可视媒体内容生成的研究进展,介绍基于互联网海量可视媒体和基于生成对抗网络的图像视频生成工作,从模型和平台的角度探讨可视媒体内容生成的发展趋势,并展望其研究与应用前景。
➤讲座8:The Flow of Knowledge: Applying Visualization Techniques in Communication and Collaboration
摘要:In our current fast-paced environment, people must collaborate to solve complex problems and make decisions. This is because the ever-growing amount of information requires more team members to divide and conquer data analysis tasks, and the increasing complexity of real-world problems demands diverse backgrounds of analysts. However, effective communication of ideas and insights remains challenging in these scenarios due to the gaps between the users and the systems. This talk discusses advanced visualization techniques for improving the effectiveness of expressing, sharing, and transferring knowledge in multi-user collaboration, using statistical models, visual representations, user interactions. In particular, this talk focuses on analyzing and visualizing user-generated content during investigative activities, such as diagrams, charts, and annotations, by promoting the interplay among data, models, and users.
➤讲座9:Scalable Visualization Systems for Broad Audiences
摘要:Two recent trends have brought opportunities and challenges in data visualization research. First, data are increasing in size and complexity across problem domains, demanding interpretable and performant visualization systems. In addition, more diverse users, such as scientists, analysts, journalists, and designers, need to work with data as an integral part of their jobs. They require visualization tools that offer low barriers of entry without sacrificing analytic or expressive power.
I will present research projects that address these two challenges from a human-centered perspective. To support exploratory analysis of large multivariate and event sequence datasets, I use perceptual and interactive scalability as the driving principle to propose new interaction techniques. To make visualization tools accessible to a broader range of users, novel visualization process models can power the design and construction of natural language interfaces and visualization authoring systems. These techniques and models lay the foundation for future research on enabling a fluid exchange of tools, designs and critiques in a visualization ecosystem.
摘要:本次报告将会阐述对抗生成网络的原理和结构,以及使用对抗生成网络生成图像的过程,并且过添加显式的条件或标签,来控制生成的图像。同时还会介绍开源动态编译深度学习框架计图(Jittor)的最新进展与基础使用,如算子与变量的使用。我们将以对抗生成网络为应用,展示模型定义,数据加载,训练以及测试的全流程。
报告人:Daniel Cohen-Or(以色列特拉维夫大学教授)
摘要:Learning disentangled representations of data is a fundamental problem in artificial intelligence. Specifically, disentangled latent representations allow generative models to control and compose the disentangled factors in the synthesis process. In my talk, I will discuss the general disentangling problem and present two methods that disentangle face properties with different types of supervision. One that uses weak supervision to map between domains A and B, allowing for example, adding glasses to a face without glasses. The second method, learns how to represent data in a disentangled way, with minimal supervision, allowing to successfully disentangle identity from other facial attributes.
➤讲座12:Generative Adversarial Networks and their Applications
报告人:Daniel Lischinski(以色列希伯来大学教授)
摘要:In this tutorial talk we will describe Generative Adversarial Networks (GANs). We will start by explaining the motivation and the theory behind these networks, which are considered by some as one of the most important developments in Artificial Intelligence. Next we will survey some recent developments in GANs, including the recent exciting StyleGAN architecture.
➤讲座13:Deep learning for Nano-photonics
报告人:Andrei Sharf(以色列本古里安大学副教授)
摘要:Nanophotonics is devoted to the study of light-matter interaction at the subwavelength scale. During the last few decades, important fundamental advances combined with the spectacular progress of nanoscale fabrication methods have led to a broad range of innovations in nanophotonics, largely based on tailoring periodically structured materials to create 2D and 3D metasurfaces or metamaterials that exhibit extraordinary properties that cannot be found in nature. This includes advances in the fields of plasmonics, holography, artificial chirality and topological photonics. However, despite the many advances in this field, its impact and penetration in our daily life has been hindered by a convoluted and iterative process, cycling through modeling, nanofabrication and nano-characterization. The fundamental reason is the fact that not only the prediction of the optical response is very time consuming and requires solving Maxwell's equations with dedicated numerical packages.
Deep learning forward modelling i.e. how artificial intelligence learns how to solve Maxwell’s equations, is a rapidly evolving research area which will be discussed in this talk.
A DL model is trained through non-linear activation functions and back propagation to intelligently learn the nonlinear relationships between the input and output values over a large dataset. In this way, a model is able to effectively “learn” Maxwell’s equations and how to solve them, without explicitly knowing them. This, in turn, allows for the possibility to discover solutions outside of the boundaries of the training data, and also the ability to transfer knowledge between problems. DL has been extremely successful in this area, with various models that can successfully predict the optical properties of nanophotonic
design. DL-based forward modelling also represents a key concept to understand subsequent advances on inverse design.
➤讲座14:Learning Neural Sparse Voxel Fields for Free-viewpoint Rendering
报告人:刘玲洁(马克斯·普朗克信息学研究所博士后)
摘要:Photo-realistic free-viewpoint rendering of real-world scenes using classical computer graphics techniques is challenging. Recent studies have demonstrated promising results by learning 3D scene representations that implicitly encode both geometry and appearance without 3D supervision. However, existing approaches in practice often show blurry renderings or require time-consuming optical ray marching. I will talk about our recent work where a new neural implicit representation has been proposed for fast and high-quality free-viewpoint rendering. With this representation, our method can achieve 10 times faster at inference time than the state-of-the-art (namely, NeRF) while achieving higher quality results. I will also demonstrate our results on various kinds of challenging tasks, including multi-object learning, free-viewpoint rendering of a moving human, large-scale scene rendering, scene editing and scene composition. Finally, I will talk about some challenges and opportunities in neural rendering that could be fun to solve in the near future.
摘要:从图像中快速鲁棒的获取目标信息是计算机视觉的核心任务。提取强大的图像特征并对输入特征进行高效的整合,对所有常见计算机视觉应用都具有重要意义。本报告从特征提取和模型学习两个方面入手。首先,从多尺度特征获取的角度,介绍近年来几个重要的神经网络基础模型的演化过程。通过介绍这些经典模型的优势与不足,引出一种轻量级计算量的新型神经网络基础模型。进而通过大量实验,验证该模型的有效性。其次,本报告将模型集成方法与深度学习相结合,介绍一种新的基于负相关学习的深度集成学习策略,新方法通过学习多组负相关子模型的基础上,提升集成模型的预测能力,同时不增加总体模型的计算复杂度。然后,本报告还将介绍一种用于提升语义分割性能的自适应池化策略。最后,本报告将介绍这些核心能力提升在一系列计算机视觉任务中的应用,包括:图像分类、物体检测、激活图预测、显著性检测、语义分割、实例分割、关键点估计、人群计数、年龄估计、性格分析、以及图像超分辨率。
➤讲座16:First and Last Mile Problems for Biomedical Image Analysis
摘要:Deep learning has greatly advanced the field of biomedical image analysis and enabled real-world healthcare deployment. Despite its success, behind the scene is the significant effort to curate the dataset and correct the remaining model prediction errors, which can be challenging for an average-sized biology lab or clinic. Unlike natural images, biomedical images are often diverse in appearance due to the tissue preparation and microscope parameters, hard to annotate, and demanding for prediction accuracy.
In this talk, I will present our three recent works from our group, aiming to facilitate the dataset annotation and automatic error correction process (CVPR'19, MICCAI'20, ECCV'20). I will first introduce the field of electron microscopy connectomics, aiming to reconstruct the brain at the nanometer resolution with a petabyte-level of data. To allocate the annotation budget, we developed a two-stream query suggestion model to use the unlabeled raw data to help find representative samples for annotation. To automatically detect and correct the 3D instance segmentation error, we used the skeleton representation to propose potential erroneous regions and incorporated the deep learning model with the multi-cut graph formulation to correct the error globally. Lastly, as an application, we build a 3D mitochondria instance segmentation dataset, 3,600x larger than previous benchmarks, revealing the new challenges for the field to develop more robust models.
➤讲座17:Design and Optimization of Conforming Lattice Structures
摘要:Inspired by natural cellular materials such as trabecular bone, lattice structures have been developed as a new type of lightweight material. Lattice structures possess exceptional mechanical, thermal and acoustic properties. The (mechanical) properties of lattices depend not only on the solid material of which struts are made but also on the topology and shape of struts. Especially since recent advances in additive manufacturing enable a cost-effective fabrication of lattices, there has been a growing interest in exploring the potential of lattices in engineering design.
In this talk, I will present a novel method to design lattice structures that conform with both the principal stress directions and the boundary of the optimized shape. Given design specifications including design domain and boundary conditions, the proposed method consists of two major steps: the first optimizes concurrently the shape (including its topology) and the distribution of orthotropic lattice materials inside the shape to maximize stiffness under application-specific external loads; the second takes the optimized configuration of lattice materials from the previous step, and extracts a globally consistent lattice structure by field-aligned parameterization. Our approach is robust and works for both 2D planar and 3D volumetric domains. Numerical results and physical verifications demonstrate remarkable structural properties of the generated conforming lattice structures.
摘要:Traditional manufacturing workflows strongly decouple design and fabrication phases. As a result, fabrication-related objectives such as manufacturing time and precision are difficult to optimize in the design space, and vice versa. We present HL-HELM, a high-level, domain-specific language for expressing abstract, parametric fabrication plans; it also intro-duces LL-HELM, a low-level language for expressing concrete fabrication plans that take into account the physical constraints of available manufacturing processes. We present a new compiler that supports the real-time, unoptimized translation of high-level, geometric fabrication operations into concrete, tool-specific fabrication instructions; this gives users immediate feedback on the physical feasibility of plans as they design them. HELM offers novel optimizations to improve accuracy and reduce fabrication time as well as material costs. Finally, optimized low-level plans can be interpreted as step-by-step instructions for users to actually fabricate a physical product.
关注“极市平台”公众号,回复“61”即
可
获取免费直播链接
。
极市平台专注分享计算机视觉前沿资讯和技术干货,特邀请行业内专业牛人嘉宾为大家分享视觉领域内的干货及经验,目前已成功举办60期线上分享。近期在线分享可点击以下标题查看:
(http://bbs.cvmart.net/topics/149/cvshare),也可以点击阅读原文获取。
在"极市平台"公众号后台回复期数或者分享嘉宾名字,即可获取极市平台对应期在线分享资料。
极市(Extreme Mart)
是深圳极视角科技有限公司旗下AI开发者生态,面向计算机视觉算法工程师,为开发者提供算法开发环境、真实数据项目实战、自动测试、加速工具、算法封装等全方位平台技术与工程支持,同时提供技术干货、大咖分享、社区交流、竞赛活动等丰富的内容与服务。
有任何问题请在本帖下留言,嘉宾会在直播中回答大家的问题~
觉得有用麻烦给个在看啦~ ![]()