全面解析YOLO V4网络结构
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
1.前言
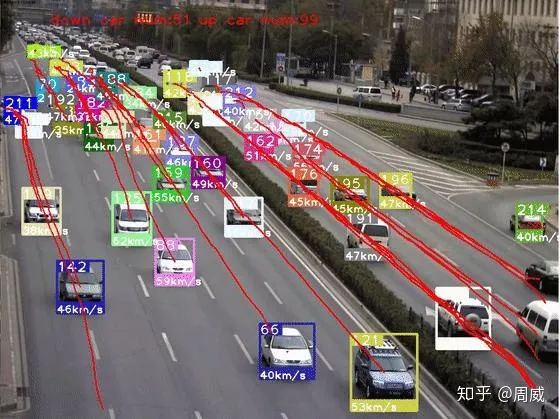
最近用YOLO V4做车辆检测,配合某一目标追踪算法实现车辆追踪+轨迹提取等功能,正好就此结合论文和代码来对YOLO V4做个解析。先放上个效果图(半成品),如下:
话不多说,现在就开始对YOLO V4进行总结。
YOLO V4的论文:《YOLOv4: Optimal Speed and Accuracy of Object Detection》,相信大家也是经常看到这几个词眼:大神接棒、YOLO V4来了、Tricks 万花筒等等。
没错,通过阅读YOLO V4的原文,我觉得它更像一篇目标检测模型Tricks文献综述,可见作者在目标检测领域的知识(炼丹技术)积累之多。
从本质上,YOLO V4就是筛选了一些从YOLO V3发布至今,被用在各式各样检测器上,能够提高检测精度的tricks,并以YOLO V3为基础进行改进的目标检测模型。YOLO V4在保证速度的同时,大幅提高模型的检测精度(当然,这是相较于YOLO V3的)。
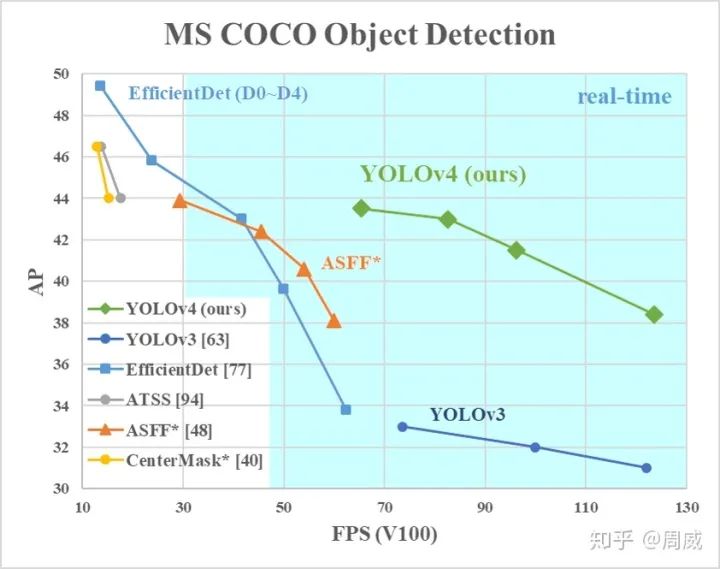
上图可以看出来,虽然检测精度不如EfficientDet这种变态,但是速度上是遥遥领先的,说明YOLO V4并没有忘记初心(速度和精度的trade off,我YOLO才是佼佼者)!
其实我是比较推荐大家看看YOLO V4原文的,就当炼丹手册来看也是挺好的,如果你懒得看,那这里我贴出来一张图,就是最终YOLO V4的炼丹配方,如下:

YOLO V4炼丹配方
这么一看,这炼丹配方多清晰呀,和YOLO V3对比,主要做了以下改变:
-
相较于YOLO V3的DarkNet53,YOLO V4用了CSPDarkNet53 -
相较于YOLO V3的FPN,YOLO V4用了SPP+PAN -
CutMix数据增强和马赛克(Mosaic)数据增强 -
DropBlock正则化 -
等等
这技巧太多了,着实让人数不过来。按照惯例,我喜欢结合代码对模型进行解析,论文的话看个思路,实现的细节还是在代码中体现的较具体。原作者YOLO V4的代码是基于C++的,如下:
YOLO V4 C++(原版)
https://github.com/AlexeyAB/darknet
这个解析起来太麻烦了,我找了个看起来不麻烦的,基于Keras+Tensorflow的,如下:
YOLO V4 Keras版本
https://github.com/Ma-Dan/keras-yolo4
本次YOLO V4论文和代码解析也将基于这个版本的进行的啦!
后面的内容将按照以下步骤进行介绍。
-
(1)YOLO V4的网络结构 -
(2)YOLO V4的损失函数 -
(3)一些Tricks的具体代码实现
2. YOLO V4的网络结构
这里我先给出YOLO V4的总结构图,如下
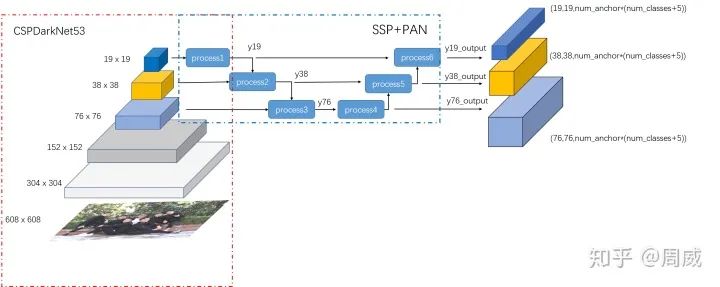
主要有以下两部分组成
-
BackBone:CSPDarknet53 -
Neck:SPP+PAN
接下面将逐个分析!
2.1 BackBone:CSPDarknet53
目前做检测器MAP指标的提升,都会考虑选择一个图像特征提取能力较强的backbone,且不能太大,那样影响检测的速度。YOLO V4中,则是选择了具有CSP(Cross-stage partial connections)的darknet53,而是没有选择在imagenet上跑分更高的CSPResNext50,

原因很简单,如上表,作者说:
For instance, our numerous studies demonstrate that the CSPResNext50 is
considerably better compared to CSPDarknet53 in terms of object classification on the ILSVRC2012 (ImageNet) dataset [. However, conversely, the CSPDarknet53 is
better compared to CSPResNext50 in terms of detecting objects on the MS COCO dataset
意思就是结合了在目标检测领域的精度来说,CSPDarknet53是要强于CSPResNext50,这也告诉了我们,在图像分类上任务表现好的模型,不一定很适用于目标检测(这不是绝对的!)。
那么这个带有CSP结构的Darknet53,到底长什么样呢?如果对CSP结构感兴趣的,欢迎点击原文链接。
这里我们直接从代码上看看这个CSPDarknet53什么样子,定义如下
def darknet_body(x):'''Darknent body having 52 Convolution2D layers'''x = DarknetConv2D_BN_Mish(32, (3,3))(x)x = resblock_body(x, 64, 1, False)x = resblock_body(x, 128, 2)x = resblock_body(x, 256, 8)x = resblock_body(x, 512, 8)x = resblock_body(x, 1024, 4)return x
如果把堆叠的残差单元(resblock_body)看成整体的话,那么这个结构和Darknet53以及ResNet等的确差别不大,特别是resblock_body的num_blocks为【1,2,8,8,4】和darknet53一模一样。
那么我们解析一下resblock_body的定义,如下:
def resblock_body(x, num_filters, num_blocks, all_narrow=True):'''A series of resblocks starting with a downsampling Convolution2D'''# Darknet uses left and top padding instead of 'same' modepreconv1 = ZeroPadding2D(((1,0),(1,0)))(x)preconv1 = DarknetConv2D_BN_Mish(num_filters, (3,3), strides=(2,2))(preconv1)shortconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)mainconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(preconv1)for i in range(num_blocks):y = compose(DarknetConv2D_BN_Mish(num_filters//2, (1,1)),DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (3,3)))(mainconv)mainconv = Add()([mainconv,y])postconv = DarknetConv2D_BN_Mish(num_filters//2 if all_narrow else num_filters, (1,1))(mainconv)route = Concatenate()([postconv, shortconv])return DarknetConv2D_BN_Mish(num_filters, (1,1))(route)
这么一看,和传统的ResBlock差别就出来了,为了大家更清晰地了解结构,我把这个残差单元的结构绘制出来,如下:
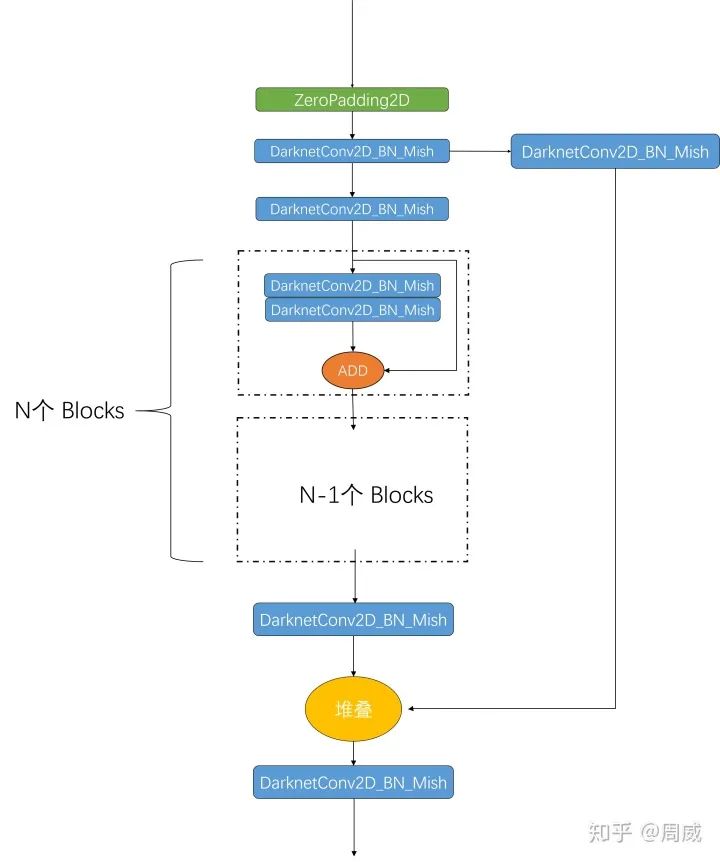
对照代码和上面的图片,可以比较清晰地看出来这个CSP残差单元和DarkNet/ResNet的残差单元的区别了。当然了,图上的DarknetConv2D_BN_Mish模块定义如下
-
(1) DarknetConv2D_BN_Mish
def DarknetConv2D_BN_Mish(*args, **kwargs):"""Darknet Convolution2D followed by BatchNormalization and LeakyReLU."""no_bias_kwargs = {'use_bias': False}no_bias_kwargs.update(kwargs)return compose(DarknetConv2D(*args, **no_bias_kwargs),BatchNormalization(),Mish())(2) DarknetConv2Ddef DarknetConv2D(*args, **kwargs):"""Wrapper to set Darknet parameters for Convolution2D."""darknet_conv_kwargs = {}darknet_conv_kwargs['kernel_initializer'] = keras.initializers.RandomNormal(mean=0.0, stddev=0.01)darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'darknet_conv_kwargs.update(kwargs)return Conv2D(*args, **darknet_conv_kwargs)
至此,YOLO V4的backbone部分就讲解完毕了。
2.2 Neck:SPP+PAN
目标检测模型的Neck部分主要用来融合不同尺寸特征图的特征信息。常见的有MaskRCNN中使用的FPN等,这里我们用EfficientDet论文中的一张图来进行说明。
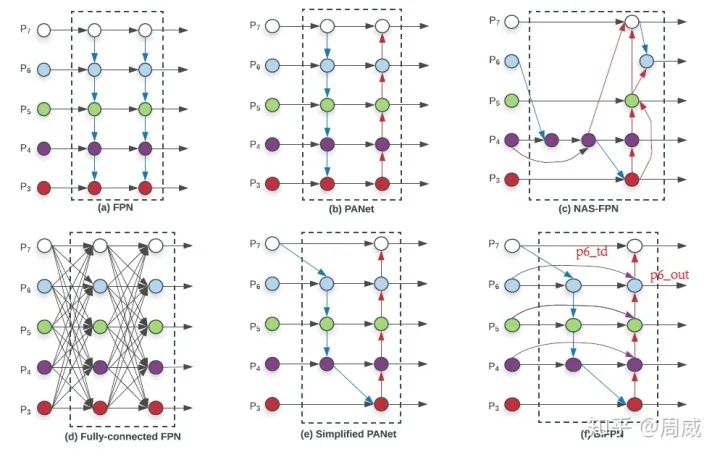
可见,随着人们追求检测器在COCO数据集上的MAP指标,Neck部分也是出了很多花里胡哨的结构呀。
本文中的YOLO V4就是用到了SPP(Spatial pyramid pooling)+PAN(Path Aggregation Network,上图的结构b)。
这里我们根据总图上的process1-6,对SSP+PAN部分进行解析。
(1) 其中process1的代码实现为:
y19 = DarknetConv2D_BN_Leaky(512, (1,1))(darknet.output) y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19) y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19) maxpool1 = MaxPooling2D(pool_size=(13,13), strides=(1,1), padding='same')(y19) #(19,19) maxpool2 = MaxPooling2D(pool_size=(9,9), strides=(1,1), padding='same')(y19) #(19,19) maxpool3 = MaxPooling2D(pool_size=(5,5), strides=(1,1), padding='same')(y19) #(19,19) y19 = Concatenate()([maxpool1, maxpool2, maxpool3, y19]) y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19) y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19) y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)
显而易见,该进程接受CSPDarknet53最终的输出,返回变量y19(如总图上process1所示),这里我们也给出图示,如下:
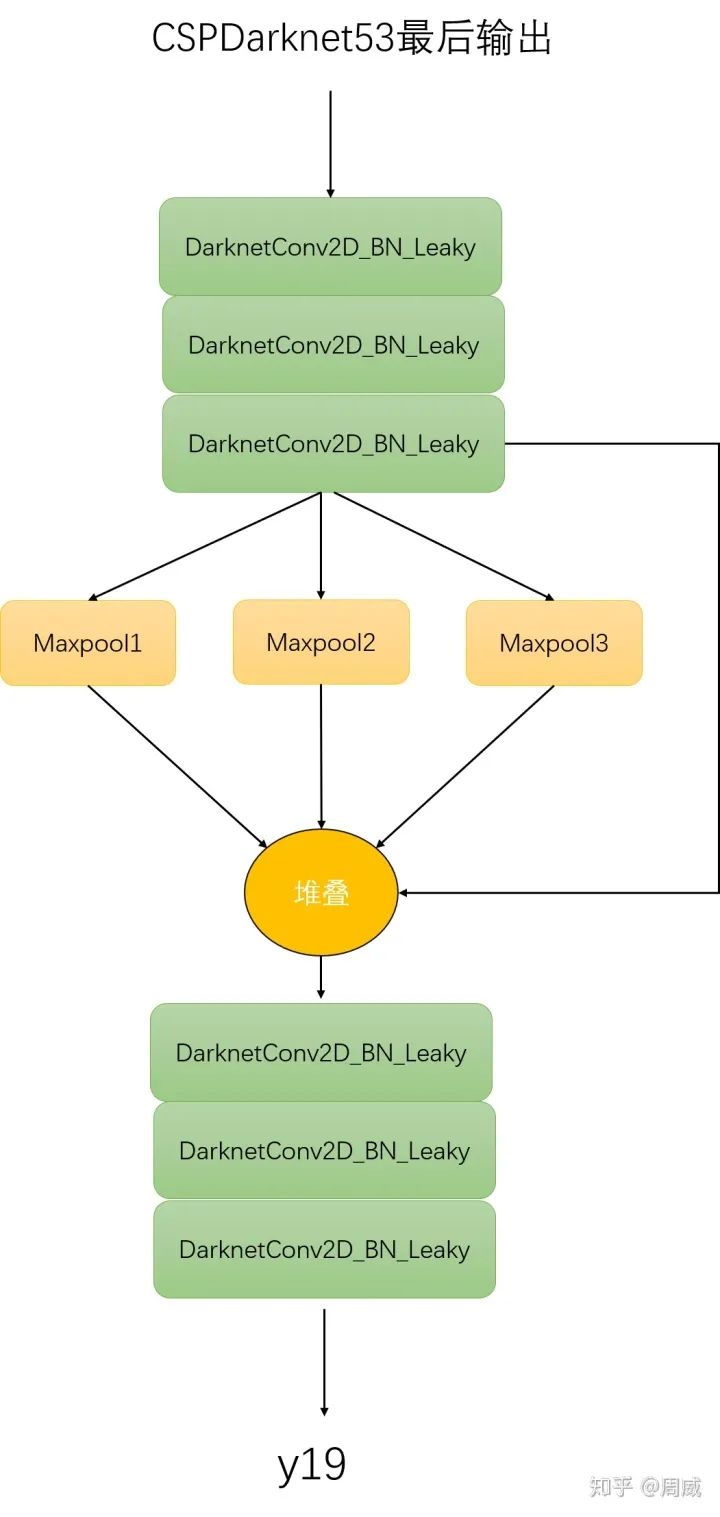
Process1
(2) process2 代码如下
y19_upsample = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(y19)
#38x38 head y38 = DarknetConv2D_BN_Leaky(256, (1,1))(darknet.layers[204].output) y38 = Concatenate()([y38, y19_upsample]) y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38) y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38) y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38) y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38) y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)
即先将上述的y19进行上采样至大小38x38,然后再和CSPDarknet53的204层输出进行堆叠,最后通过一系列DarknetConv2D_BN_Leaky模块,获得变量y38。
(3) process3的代码如下,类似于process2
y38_upsample = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(y38)
#76x76 head y76 = DarknetConv2D_BN_Leaky(128, (1,1))(darknet.layers[131].output) y76 = Concatenate()([y76, y38_upsample]) y76 = DarknetConv2D_BN_Leaky(128, (1,1))(y76) y76 = DarknetConv2D_BN_Leaky(256, (3,3))(y76) y76 = DarknetConv2D_BN_Leaky(128, (1,1))(y76) y76 = DarknetConv2D_BN_Leaky(256, (3,3))(y76) y76 = DarknetConv2D_BN_Leaky(128, (1,1))(y76)
(4) process4的代码如下
#76x76 outputy76_output = DarknetConv2D_BN_Leaky(256, (3,3))(y76)y76_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(y76_output)
这个比较简单,直接通过一个DarknetConv2D_BN_Leaky,然后使用1x1卷积输出最大的一张特征图y76_output,维度为**(76,76,num_anchor*(num_classes+5))**。
(5) process5的代码如下:
#38x38 outputy76_downsample = ZeroPadding2D(((1,0),(1,0)))(y76)y76_downsample = DarknetConv2D_BN_Leaky(256, (3,3), strides=(2,2))(y76_downsample)y38 = Concatenate()([y76_downsample, y38])y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)y38 = DarknetConv2D_BN_Leaky(512, (3,3))(y38)y38 = DarknetConv2D_BN_Leaky(256, (1,1))(y38)y38_output = DarknetConv2D_BN_Leaky(512, (3,3))(y38)y38_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(y38_output)
这一步骤比较关键,PAN和FPN的差异在于,FPN是自顶向下的特征融合,PAN在FPN的基础上,多了个自底向上的特征融合。具体自底向上的特征融合,就是process5完成的,可以看到该步骤先将y76下采样至38x38大小,再和y38堆叠,然后进行一系列卷积运算获得维度大小为**(38,38,num_anchor*(num_classes+5))的输出y38_output**,如下图所示。
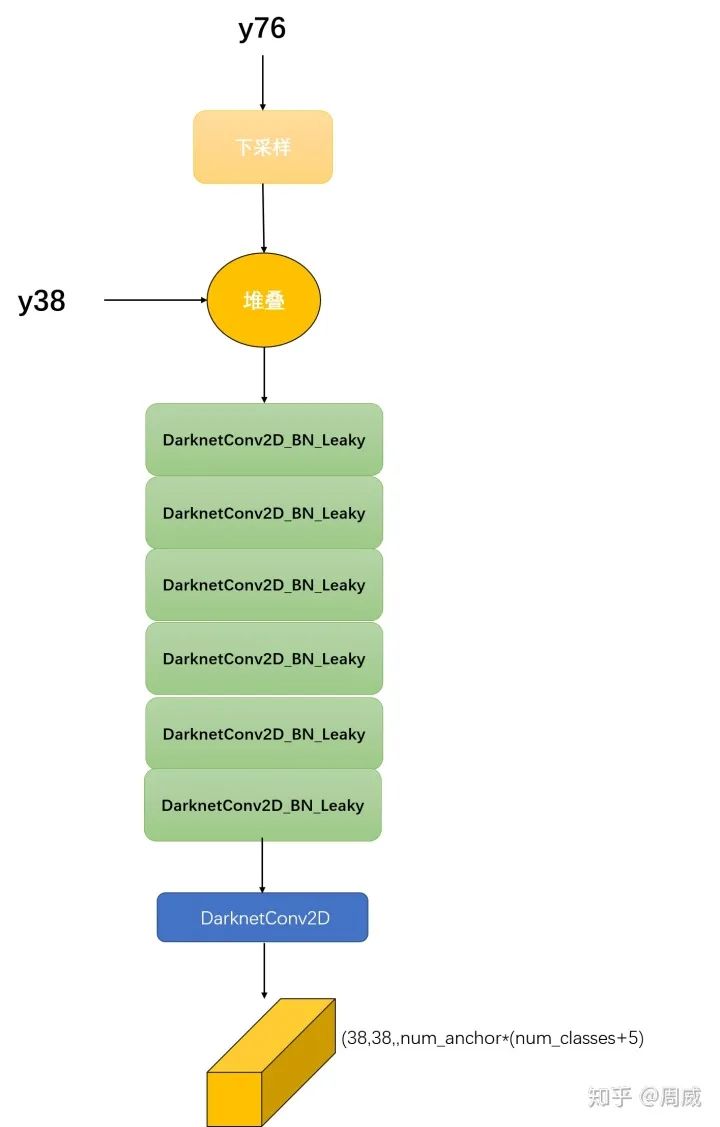
Process5
(6) Process6代码如下
#19x19 outputy38_downsample = ZeroPadding2D(((1,0),(1,0)))(y38)y38_downsample = DarknetConv2D_BN_Leaky(512, (3,3), strides=(2,2))(y38_downsample)y19 = Concatenate()([y38_downsample, y19])y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)y19 = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)y19 = DarknetConv2D_BN_Leaky(512, (1,1))(y19)y19_output = DarknetConv2D_BN_Leaky(1024, (3,3))(y19)y19_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(y19_output)
Process6和process5进程类似,不多赘述,输出为(19,19,num_anchor*(num_classes+5))的特征图y19_output。
3.结束语
上述有关YOLO V4的网络结构就讲到这里,我看了下,篇幅又有点长了,那关于损失函数和更多tricks实现的细节,我就放到后面再讲了,感谢大家支持!
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




