谷歌和Uber的最佳实践方案:如何构建可持续的深度学习架构

更多干货内容请关注微信公众号“AI 前线”,ID:ai-front
要构建一个可持续的深度学习解决方案,仅仅依靠像 TensorFlow、PyTorch 这样的深度学习框架是不够的。这些框架用于研究绰绰有余,但却没有考虑生产部署可能出现的问题。我之前写过关于技术债务和对适应性更强的类生物架构的需要的文章。要使用深度学习支撑业务,必然需要一个在环境频繁发生意料之外的变化的情况下能持续改进的架构。当前的深度学习框架只能提供完整解决方案的其中一个部分。
幸运的是,我们能一睹谷歌和Uber的深度学习解决方案的内部架构。如果我们需要构建自己的可用于生产的深度学习解决方案,这两大巨头的架构是两个优秀的起点。
Uber开发名叫 Michelangelo 的系统的主要动机是“没有能用于构建可靠的、统一的且可重现的流水线的系统,以创建和管理大规模的训练数据和预测数据”。在论文中,它们指出了现有框架在部署方面和管理技术债务方面的局限。文章论据充分,能让任何不以为然的人相信,现有框架不足以用于生产。
我不会从头到尾完整介绍Uber的论文,而是只强调其架构的一些关键点。Uber的系统严格上不是一个深度学习系统,而是一个机器学习系统,能依据合适程度运用机器学习方法。它构建于下列开源组件之上:HDFS、Spark、Samza、Cassandra、MLLib、XGBoost 和 TensorFlow。所以,它是一个传统的大数据系统,融入了机器学习组件用于分析:
Michelangelo 构建于Uber的数据和计算基础设施之上,提供了一个存储Uber所有的交易数据和日志数据的数据湖泊、众多聚合Uber所有服务的日志消息的 Kafka 代理、一个 Samza 流计算引擎、多个托管的 Cassandra 集群和内部服务配置和部署工具。
该架构支持如下工作流:
管理数据
训练模型
评估模型
部署、预测和监控
Uber的 Michaelangelo 的架构如下:
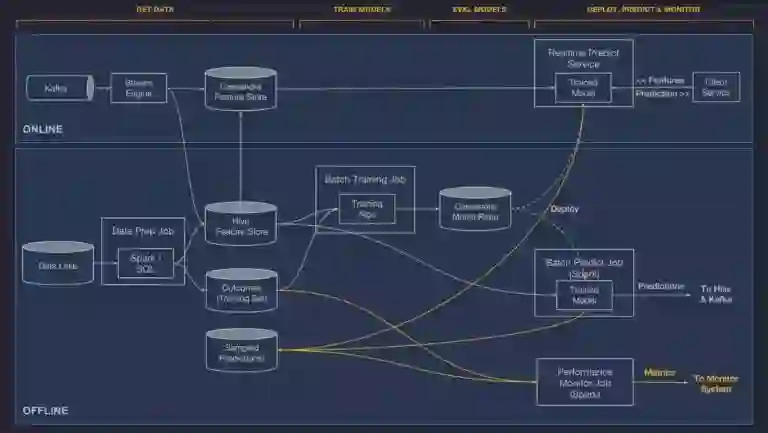
我将跳过通常的大数据架构关注点,而指出一些值得注意的、与机器学习更相关的想法。
Michaelangelo 使用在线和离线流水线分开管理数据。另外,为了在组织内共享和重用知识,使用了一个“特征存储”:
此刻,在特征存储中,我们有接近 10,000 个特征,用于加速机器学习工程,全公司的团队时时刻刻都在添加新的特征。特征存储中的特征每天都在自动计算和更新。
Uber为建模师创造了一种领域专用语言(DSL),在发送模型进行训练和预测之前,用于选择、转换和组合特征。当前支持的机器学习方法有:决策树、线性和逻辑模型、k-means、时间序列和深度神经网络。
模型配置指定类型、超参数、数据源引用、特征 DSL 表达式和计算资源要求(即 CPU、内存、GPU 的使用等)。训练在 YARN 或 Mesos 集群中进行。
模型训练后,评估报告计算并提供性能指标。所有信息,即模型配置、学习得到的模型和评估报告,都存储在一个版本化模型仓库中,以进行分析和部署。模型信息包含:
模型的训练者
训练作业的起止时间
完整的模型配置(使用的特征、超参数值等)
训练数据集和测试数据集的引用
每个特征的分布和相对重要性
模型精度指标
每个模型类型的标准图表(例如二分类器的 ROC 曲线、PR 曲线和混淆矩阵)
完整的学习得到的模型参数
模型可视化等概要统计数据
这样做意在使获取机器学习模型民主化,共享模型,提升组织知识。Uber使用的方法的独特之处在于抽出了一个“特征存储”,允许各方在不同的机器学习模型之间共享数据。
谷歌的人员最近发表了一篇文章“TFX:基于 TensorFlow 的生产级机器学习平台”,详细介绍了其内部系统。
文章链接:
http://www.kdd.org/kdd2017/papers/view/tfx-a-tensorflow-based-production-scale-machine-learning-platform
TFX
该论文结构上与Uber的论文相似,覆盖了同样的工作流:
管理数据——数据分析、转换和验证
训练模型——模型训练:热启动和模型规格
评估模型——模型评估和验证
部署、预测和监控——模型服务
谷歌的架构由以下高级指导原则驱动:
尽早捕获数据异常。
自动化数据验证。
像对待代码一样严苛对待数据错误。
支持持续训练。
统一配置,增强共享。
可靠且可扩展的生产部署和服务。
让我们深入了解 Google TFX 的独特能力。在此过程中,有很多趣事,以及几个独特的能力的介绍。
TFX 提供了一些数据管理的能力。数据分析对每个数据集进行统计,提供关于值的分布、分位数、平均值和标准差等信息,意在让用户快速了解数据集的形态。这种自动分析用于提升持续训练和服务环境。
TFX 处理数据整理并存储转换,以保持一致性。此外,系统提供了统一的一致的框架,用于管理特征到整数映射。
TFX 证明了一个模式,它是指定数据期望的版本。此模式用于标记发现的任何异常,并提供诸如阻止训练或弃用特征的操作建议。工具提供自动生成此模式的能力,使模式易于用于新项目。这是一个独特的能力,从编程语言中的静态类型检查获得的灵感。
TFX 使用 TensorFlow 描述模型。TFX 有“热启动”的概念,受到深度学习中的转移学习技术的启发。热启动意在通过利用现有训练来减少训练量。与采用现有预训网络的转移学习技术不同,热启动选择性地将一般特征网络识别为起点。使用一般特征训练的网络用作训练更专业的网络的基础。此特性在 TF-Slim 中实现。
TFX 使用通用的高级 TensorFlow 规范(参见:TensorFlow Estimator:管理高级机器学习框架中的简洁性与灵活性
https://arxiv.org/abs/1708.02637
),以提供不同实现的统一性和编码最佳实践。阅读这篇关于 Estimator 的文章了解更多详细信息:
https://medium.com/onfido-tech/higher-level-apis-in-tensorflow-67bfb602e6c0
TFX 使用 TensorFlow Serving 框架进行部署和服务。该框架能在保持相同架构和 API 的同时服务不同的模型。TensorFlow Serving 提供“软模型隔离”,从而支持多租户部署模型。该框架设计上还支持可扩展的推断。
TFX 论文提到需要优化模型的反序列化。显然,创建了自定义的协议缓冲区解析功能,性能提升高达 2-5 倍。
剖析Uber和谷歌的内部架构,可以为构建自己的内部平台的痛点和解决方案提供很好的思路。与可用的开源深度学习框架相比,它们更加强调管理和共享元信息。谷歌的方法还需要额外的努力来确保一致性和自动验证。这些是我们以前在常规软件工程项目中看到的做法。
诸如测试驱动开发(TDD)、持续集成、回滚和恢复、变更控制等软件工程实践正在引入到高级的机器学习实践中去。专家在 Jupyter notebook 上开发之后丢给团队,然后再上线运行,这是不够的。今天我们在最好的工程公司看到的端到端 devops 实践,机器学习也将需要它们。今天Uber和谷歌让我们认识到了这一点,因此我们预见,任何可持续的机器学习和深度学习实践也会如此。
查看英文原文:
https://medium.com/intuitionmachine/google-and-ubers-best-practices-for-deep-learning-58488a8899b6

关注人工智能的落地实践,与企业一起探寻 AI 的边界,AICon 全球人工智能技术大会火热售票中,6 折倒计时一周抢票,报名链接请参看【阅读原文】




