从算法到芯片,再到ADAS芯片 | 厚势

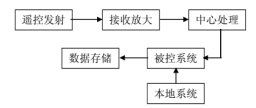
数字集成电路的设计可以分为系统级、行为级、结构级、RTL 级、门级、电路级和版图级。系统级是把各个部件联系为一个有机的整体。比如一个射频系统如下图:
行为级就是实现何种功能,如 FCW 的行为级,根据摄像头的数据测算前方障碍物与自车之间的距离,并结合自车速度数据,计算出 TTC 时间。如果 TTC 时间低于阈值(通常是 2.7 秒)就报警,反之就不报警。RTL 级就是寄存器级,如图:
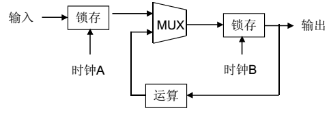
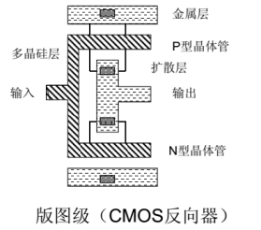
寄存器由逻辑门构成,逻辑门由电路构成,最后电路由半导体晶体管 P 和 N 结构成。
下图为数字类芯片设计的简单流程图:
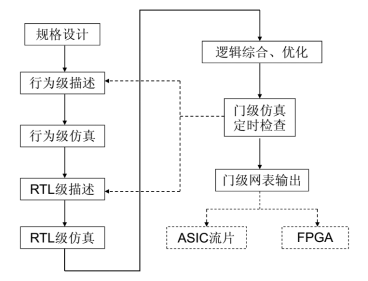
目前集成电路设计基本上都是用 IP 核搭积木的形式。
IP 核分为行为(Behavior)、结构(Structure)和物理(Physical)三级不同程度的设计,对应描述功能行为的不同分为三类,即软核(Soft IP Core)、完成结构描述的固核(Firm IP Core)和基于物理描述并经过工艺验证的硬核(Hard IP Core)。软核就是我们熟悉的 RTL 代码;固核就是指网表;而硬核就是指指经过验证的设计版图。ARM 还是以软核为主的。
IP 软核(Soft IP Core):通常是用硬件描述语言(hardware Description Language,HDL)文本形式提交给用户,它经过 RTL 级设计优化和功能验证,但其中不含有任何具体的物理信息。据此,用户可以综合出正确的门电路级设计网表,并可以进行后续的结构设计,具有很大的灵活性,借助于 EDA 综合工具可以很容易地与其他外部逻辑电路合成一体,根据各种不同半导体工艺,设计成具有不同性能的器件。其主要缺点是缺乏对时序、面积和功耗的预见性。而且 IP 软核以源代码的形式提供的,IP 知识产权不易保护。
IP 硬核(Hard IP Core)是基于半导体工艺的物理设计,已有固定的拓扑布局和具体工艺,并已经过工艺验证,具有可保证的性能。其提供给用户的形式是电路物理结构掩模版图和全套工艺文件。由于无需提供寄存器转移级(Register transfer level,RTL)文件,因而更易于实现 IP 保护。其缺点是灵活性和可移植性差。IP 固核(Firm IP Core)的设计程度则是介于软核和硬核之间,除了完成软核所需的设计外,还完成了门级电路综合和时序仿真等设计环节。一般以门级电路网表的形式提供给用户。
如果以 FPGA 来承载算法,那相对 ASIC 要简单的多。首先要了解 FPGA 的基本核心,就是 LUT。每一块 FPGA 芯片都是由有限多个带有可编程连接的预定义源组成,可实现可重配置数字电路和 I/O 模块并允许电路接触外部环境。
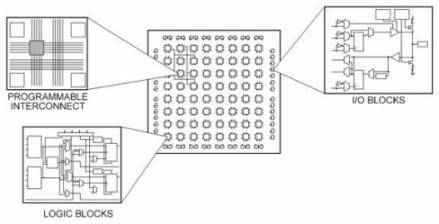
FPGA 说明书中通常介绍了可编程逻辑模块的数量、固定功能逻辑模块(如乘法器)的数目及存储器资源(如嵌入式块RAM)的大小。FPGA 芯片中还有很多其它的部分,但是以上指标通常是在为特定应用选择和比较 FPGA 时的最重要参考指标。可重配置逻辑模块(configurable logic block, CLB)是 FPGA 的基础逻辑单元。
CLB 有时又称为片(slice)或逻辑单元,由两个基本元器件构成:触发器和查找表(LUT)。不同 FPGA 产品系列的区别在于触发器和 LUT 的组合方式,因此理解触发器和 LUT 是至关重要的。可重配置逻辑模块(CLB)中的大部分逻辑是以 LUT 的形式通过使用少量的随机存取存储器(RAM)来执行。我们可以简单地假定 FPGA 中系统门的数量是指特定芯片中与非门(NAND)以及或非门(NOR)的数量。但实际上,所有的组合逻辑(与门、或门、与非门、异或门等)都是通过查找表存储器中的真值表来执行。真值表是每个输入值组合对应的输出预定义表。
简单的说,每一个 LUT 可以看成一个有 4 位地址线的 16x1 的 RAM。当用户通过原理图或 HDL 语言描述了一个逻辑电路以后,PLD/FPGA 开发软件会自动计算逻辑电路的所有可能的结果,并把结果事先写入 RAM。这样,每输入一个信号进行逻辑运算就等于输入一个地址进行查表,找出地址对应的内容,然后输出即可。
这就是 FPGA 为什么运行频率不高,却速度飞快的原因,它不像 CPU 或 GPU 那样用运算单元运算,它是像 RAM 那样读取的,自然速度远比 CPU 或 GPU 快。不过缺点也来了,如果运算量比较大,那么就需要比较多的 LUT,对 FPGA 来说只能加大硅片面积,这会导致成本飞速增加。同时,FPGA 只适合整数运算,传感器领域多小数运算,这时候通常需要加一个 DSP 硬核或软核,这当然会增加成本。现在的 FPGA 都不是纯粹的 FPGA,都要加入一些 DSP、CPU、时钟等构成一个 SoC FPGA。
目前大部分 FPGA 都是基于 SRAM 工艺的,而 SRAM 工艺的芯片在掉电后信息就会丢失,一定需要外加一片专用配置芯片,在上电的时候,由这个专用配置芯片把数据加载到 FPGA 中,然后 FPGA 就可以正常工作,由于配置时间很短,不会影响系统正常工作。 也有少数 FPGA 采用反熔丝或 Flash 工艺,对这种 FPGA,就不需要外加专用的配置芯片。
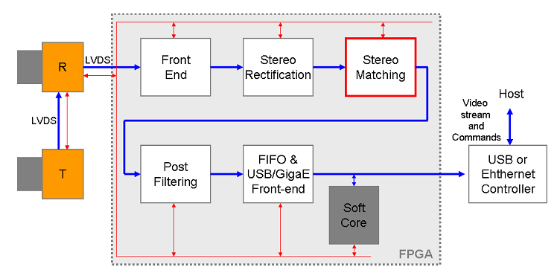
我们以双目算法为例,上图为一个典型的双目计算系统。双目最关键的就是匹配算法,通常有 SAD、SSD、CENS 等,其中最常见的是 SAD。SAD(Sum of absolute differences)是一种图像匹配算法。基本思想:差的绝对值之和。此算法常用于图像块匹配,将每个像素对应数值之差的绝对值求和,据此评估两个图像块的相似度。该算法快速、但并不精确,通常用于多级处理的初步筛选。这种算法简单,但工作量大,非常适合 FPGA。
基本流程,输入:两幅图像,一幅 Left-Image,一幅 Right-Image。对左图,依次扫描,选定一个锚点:
(1)构造一个小窗口,类似于卷积核;
(2)用窗口覆盖左边的图像,选择出窗口覆盖区域内的所有像素点;
(3)同样用窗口覆盖右边的图像并选择出覆盖区域的像素点;
(4)左边覆盖区域减去右边覆盖区域,并求出所有像素点灰度差的绝对值之和;
(5)移动右边图像的窗口,重复(3)-(4)的处理(这里有个搜索范围,超过这个范围跳出);
(6)找到这个范围内 SAD 值最小的窗口,即找到了左图锚点的最佳匹配的像素块。
以 Altera 的 NIOS II 为例,Altera 提供 SOPC builder 这个工具,在里面嵌入 NIOS II 处理器和一些常用的 IP 核。NIOS II 处理器作为主机,其他外设作为从机,主机和从机之间通过 AVALON MM 总线进行通信与访问,每一个外设都有一个地址,NIOS II 处理器可以通过这条总线对外设进行操作,但是每次只能访问一个外设。
系统硬件搭建好了之后,通过 Quartus II 对其进行综合,布局布线,时序约束等硬件系统搭建工作,然后我们用 C 语言通过 NIOS II eclipse 这个工具来给硬件系统编程,并进行运行调试,最后将我们设计好的硬件与软件文件烧入 FPGA 的配置芯片或者 FLASH 中。
把 CPU 配置为双目匹配控制器,视差计算单元就是 LB。
如果需要用到的算法多种多样且比较复杂,并且是计划用于消费类电子或汽车电子领域,那么 FPGA 是不合适的,FPGA 在一定门数之上,性价比会很低,远低于 ASIC。ASIC 在价格、功耗、性能方面是全面超越 FPGA 的,FPGA 应该说就是针对懒人的,它帮你实现任意组合,但是不做任何优化,而 ASIC 就是尽量优化,特别是物理层面的优化。比如你如果需要一个乘法器,ASIC 可以保证乘法器离得非常近,连接线距离很短,延迟自然非常小,FPGA 就没这能力。
如果你需要大量的 SRAM,多块不同位置的 SRAM,你要如何满足 timing 需求?ASIC 不同,ASIC 里面可以保障你想要多大的 SRAM 就有多大的 SRAM,而且可以做到物理布局得非常近,这样时钟就会很好。更不要说 ASIC 可以根据时钟需求更换 cell。 FPGA 的走线,你几乎是动不了的。ASIC 中你可以直接加宽金属线,比如两倍宽度走时钟线,复位线之类的。金属线宽度变大,线上的延迟变小,对速度也是有帮助的。
当然啦,ASIC 的前期成本太高,时间成本也很高,风险很高,有点像赌博,赌对了市场需求,就发财了,赌错了,直接破产。ASIC 从立项到拿到芯片,一般在 3-5 年左右,一般生命周期最少也得 3-5 年,也就是说,立项的时候要准确把握 5-6 年后的市场需求,汽车电子日新月异,要想准确把握 5-6 年后的市场需求是很难的。
对于自动驾驶领域来说,深度学习芯片则是与传统芯片不同。因为深度学习是一类特定应用,深度学习特别是 CNN 图像识别的通用型芯片或许是可能的。
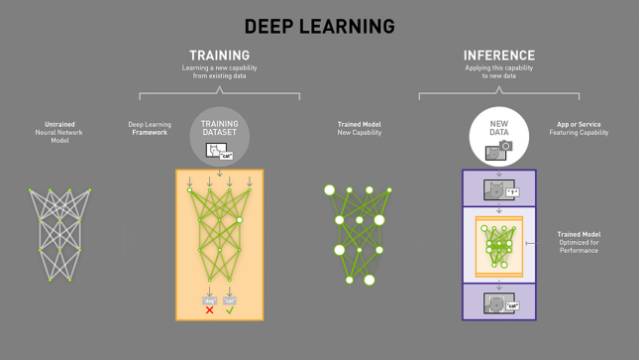
深度学习分训练和推理两部分,一般提到的深度学习芯片应该指推理部分的应用,训练端用 CPU+GPU 或 CPU+FPGA,ASIC 很难适应训练端的需求。谷歌的 TPU 也就是主打推理部分的应用,在自动驾驶领域,就是深度学习的嵌入式系统应用。
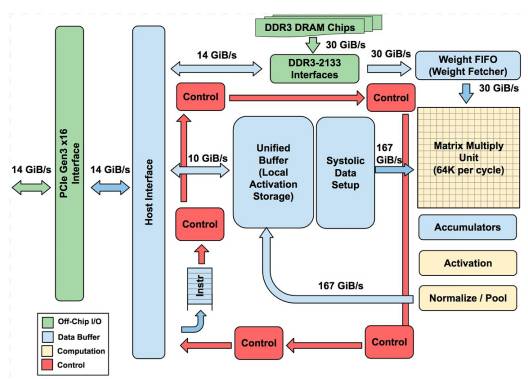
上图为谷歌的 TPU 架构图,TPU 的架构看上去很简单,主要模块包括片上内存,256 x 256 个矩阵乘法单元,非线性神经元计算单元(activation),以及用于归一化(Normalize)和池化的计算单元。
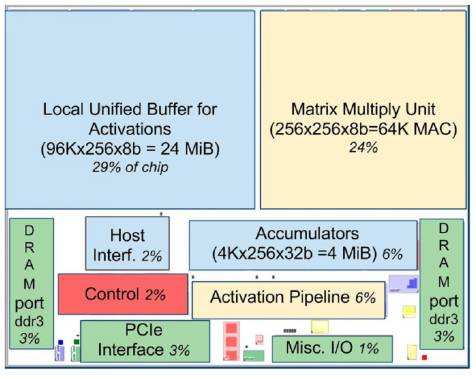
TPU 在芯片上使用了高达 24MB 的局部内存,6MB 的累加器内存以及用于与主控处理器进行对接的内存,总共占芯片面积的 37%(图中蓝色部分)。这表示 Google 充分意识到片外内存访问是 GPU 能效比低的罪魁祸首,因此不惜成本在芯片上放了巨大的内存。相比之下,Nvidia 同时期的 K80 只有 8MB 的片上内存,因此需要不断地去访问片外 DRAM。256x256 个矩阵乘法单元占芯片面积的 30%,红色控制部分仅占 2%,绿色输出输入部分占 10%。
一般来说,ASIC 的价格远低于 FPGA 或 GPU,但是谷歌的 TPU 恐怕不是,它出货量显然远不及英伟达的 GPU。GPU 的出货量是其万倍以上,适用面很广,价格自然可以压低。芯片面积的 37% 都是内存,成本自然不低。
英特尔收购的 Movidius 就试图打造一款通用性比较强的可以用做深度学习嵌入式系统的芯片。
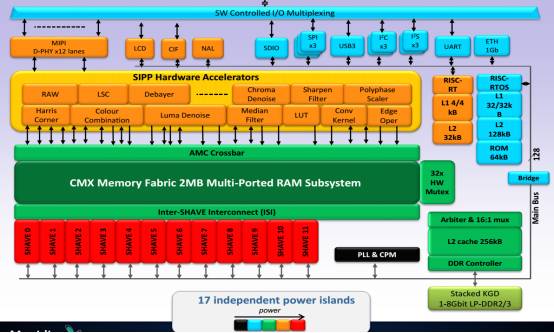
上图为 Movidius Myraid2 的内部框架图
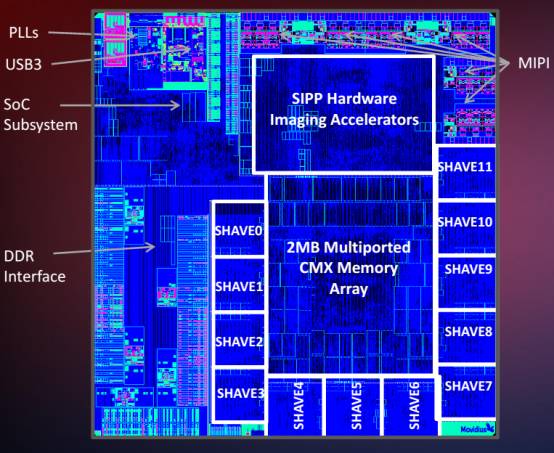
上图为 Movidius Myraid2 die 的电子显微镜图
Myraid2 采用台积电 28 纳米 HPC 工艺制造,提供两种封装形式,一种为 FC-BGA PoP 封装,内含 1Gbits LPDDR2 内存。封装面积比较大有 6.5*6.5 毫米,0.4 毫米间距。另一种封装形式,不含内存,采用 WLCSP 封装,封装面积 5.1*5.3 毫米,0.35 毫米间距。

Myraid2 的核心是 5 个 SHAVE,SHAVE 包含宽而深的寄存器文件,加上一个提高代码大小效率的长指令集(VLIW),SIMD单指令流多数据流(Single Instruction Multiple Data,缩写为SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称「数据矢量」)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。其典型代表是向量处理器(Vector Processor)和阵列处理器(Array Processor)。比如有四个计算单元,给这个四个计算单元发一条加法指令,这样他们可以同时执行加法计算。向量计算 x,y,z,w 就是用到这个。
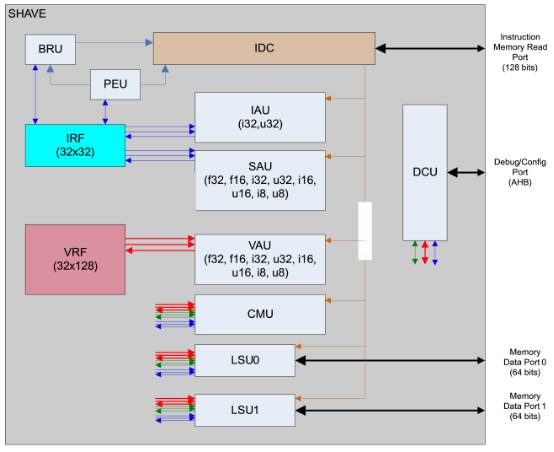
上图为 Shave 内部,IRF(整形寄存器文件),IRF 包含 32 个寄存器,每个是 32bit 长。这些寄存器主要是实现对整形运算的支持,不仅如此,还用与加载和存取指令。执行和操作这些寄存器的是 IAU(Integer Arithmetic Unit,整形运算单元)和 SAU(Scalar Arithmetic Unit标量运算单)。另外 SIMD 运算在 SAU 和 IAU 还有一些 16bit 和 8bit 的整数类型。
VRF(向量寄存器文件),VRF 同样也包含 32 个寄存器,每个是 128bit 长度。 这些寄存器是为了给 SHAVE 提供 SIMD 操作。执行这些寄存器的称作 VAU(Vector Arithmetic Unit)。 它同时支持整型和浮点运算,支持 8,16, 32bit 整型或者浮点型。 SAU(Scalar Arithmetic Unit),这个单元为 IRF 提供浮点运算支持。除了最通用的浮点源运算,这个单元还实现一些复杂的 16bit 浮点运算,如:补运算,正弦, 平方根,平方根倒数,余弦,反正切,对数和指数。这个单元还为提供整型运算。假如有用,这个特点会更多的用来为 IRF 提供并行整型运算。CMU(Compare and Move Unit 比较移动单元),这个单元提供从一个寄存器拷贝数值到另外一个寄存器的功能。支持任意组合和多位长(bit)。这个单元也提供比较数据类型的功能。比较通过设定多种条件入口。 VRF 也可以发起这个比较,比较多种数据。
LSU(Load Store Unit 加载存储单元),有 2 个加载存储单元提供加载和存储数据给两个寄存器文件 LSU 和其他单元配合使用,混合操作多种数据类型,在 SHAVE ISA 文档上面有描述。BRU(Branching Unit分支单元),BRU 提供分支功能。SHAVE 有一个 5 个周期的延时槽用来填写进其他的指令。
PEU(Predicate Execution Unit 预测执行单元),PEU 有助于实现条件分支预测和保存条件在 LSU 和 VAU 单元里面。
大疆的无人机就采用这款芯片检测障碍物和避障。不过深度学习的本质是一个概率拟合的过程,同时又分为训练和推理两部分。训练需要海量的经过良好标注的数据,没有标注的数据,或者说没有人工准确标注的数据,训练的结果会大打折扣,标注需要高昂的成本,同时深度学习可能在某个测试集上表现很好,但是实际使用时又可能表现不好,要找出其中原因则非常困难。汽车工业可能难以接受这种典型的黑盒数学模型,同时它的成本也会因为数据标注的高昂成本而增加,尽管芯片本身不贵,可能外围的边际成本是芯片成本的十倍以上,这是阻碍深度学习嵌入式应用的另一个阻力。
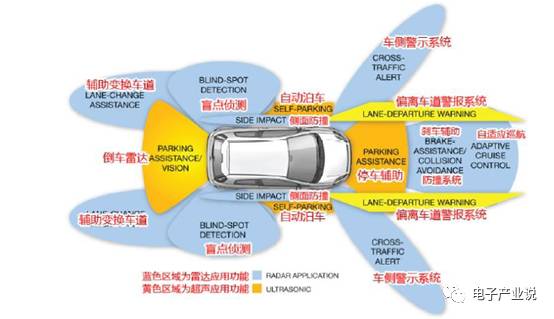
ADAS(高级辅助驾驶系统),是指利用安装于车上各式各样的传感器,在第一时间收集车内的环境数据,进行静、动态物体的辨识、侦测与追踪等技术上的处理,从而能够让驾驶者在最快的时间察觉可能发生的危险。通常包括导航与实时交通系统 TMC,电子警察系统 ISA 、自适应巡航 ACC 、车道偏移报警系统 LDWS、车道保持系统,碰撞避免或预碰撞系统、夜视系统、自适应灯光控制、行人保护系统、自动泊车系统、交通标志识别、盲点探测,驾驶员疲劳探测、下坡控制系统和电动汽车报警系统等。
目前来看汽车的创新绝大部分来自于汽车电子的创新,而从汽车电子系统来讲,正在由分散式架构(众多的 ECU 控制),逐渐向集中式乃至中央控制系统(超级处理器)演进,这一趋势落实到 ADAS 上也是同样规律。这一趋势的变化,包括减少 ECU,降低功耗,提高处理器和内存利用效率,降低软件的开发难度和提高安全,使汽车半导体厂商在整个汽车产业中扮演越来越重要的角色。同时,对 ADAS 处理器芯片来说,目前呈现出如智能家居类似的产品形态,单品爆款,以及多功能的组合,即类似于 Mobileye 的视觉处理 ADAS 芯片单品,以及多传感器的融合,使 ADAS 处理芯片成为平台的趋势。目前来看这两种形态都有市场,单功能会使 ADAS在中低端车甚至后装市场,更大范围的普及,当然性价比是前提。而多传感器的融合会提升自动驾驶的等级向 Level4 甚至 Level5 方向走,目前像 Google、百度等无人车都在做多传感器的融合,只是目前为止还没有专门的 Level4/5ADAS ASIC 芯片而已。
从芯片设计来说,现在 ADAS 处理器芯片的主要挑战在如下几个方面:
1)车规级的标准,最好过 ISO26262,达到 ASIL-B 甚至 ASIL-D 级别
2)高计算量以及高带宽,特别是多传感器融合的芯片,需要更高的芯片频率,以及异构设计,以达到快速的数据处理速度,同时传输的吞吐率上也有较高要求。
3) 随着人工智能在 ADAS 上的应用,针对芯片的设计会考虑增加硬件的深度学习设计,如何在软硬件上做取舍,以及人工智能计算模型与原有软硬件架构以及整个系统设计上做匹配,目前来看还在早期探索阶段。
下面主要介绍各家主要 ADAS 处理器芯片厂商的产品,希望从他们的产品中一窥现在 ADAS 处理器芯片领域的现状,以及未来的发展趋势。
高通/NXP
由于高通已经收购 NXP,所以在这里一起介绍。高通自己主要通过自己的移动处理器芯片(改成车规级),开始逐步切入 ADAS,当然刚开始做环视等,最近有和纵目合作,在 CES 上推出首个基于骁龙 820A 平台并运用深度学习的最新 ADAS 产品原型,该产品运行了 820A 神经网络处理引擎(SNPE),能实现对车辆、行人、自行车等多类物体识别,以及对像素级别可行驶区域的实时语义分割,当然离商用应该还有一定距离。总的来说,高通骁龙产品策略应该还是以车载娱乐信息系统为主,逐步向更专业的 ADAS 拓展。
同时,NXP 以及之前 NXP 收购的飞思卡尔,在汽车电子和 ADAS 芯片领域都有完整的产品线布局。
NXP 已经发布 Blubox 平台,为 OEM 厂商提供设计、制造、销售 Level 4 级(SAE)无人驾驶汽车的解决方案计算平台。下图是 NXP 的 ADAS 系统框图,该系统对多路视频、77G 雷达的数据进行融合处理,然后传送给云端和车身系统。我们看到 NXP 是能够提供全套 Reference 方案的公司,在这一块的产品线很全,虽然现在没有做更多的芯片集成,而是提供相对分散的芯片及解决方案。我们这里重点介绍一下中央处理器 S32V234 和 MPC5775K,MPC5775K 是对雷达数据进行处理,而 S32V234 是对多传感器处理过的数据进行融合分析,通过 CAN 总线,把结果传给车身系统。
S32V234 是 NXP 的 S32V 系列产品中 2015 年推出的 ADAS 处理器,支持 CPU(4颗ARM V8架构A53和M4)、GPU(GC3000)和图像识别处理(CogniVue APEX2 processors)的异构计算,5W 的低功耗设计。通过 CogniVue APEX2 processors 能同时支持四路汽车摄像头(前、后、左、右),抽取图像并分类,同时 GPU 能实时 3D 建模,计算量达到 50GFLOPs。所以按照此硬件架构可完成 360 度环视,完成自动泊车等功能。同时,该芯片预留了支持毫米波雷达、激光雷达、超声波的接口,便于实现多传感器的融合,该芯片支持 ISO 26262 ASIL B 标准。
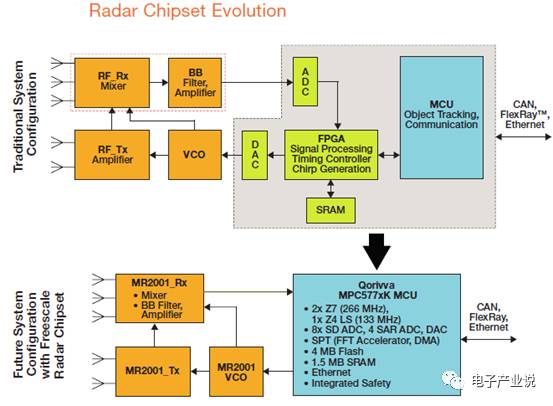
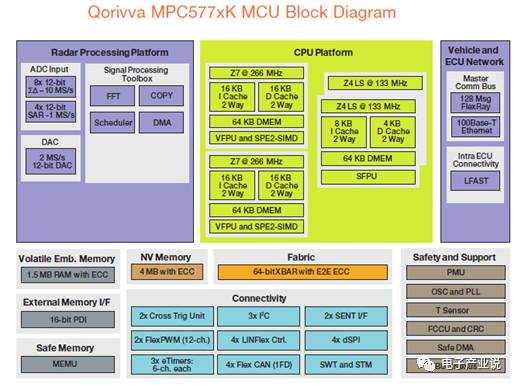
QorivvaMPC567xK 系列基于 Power Architecture® 的 32 位 MCU,MPC577XK 是专门的雷达信息处理芯片,该系列增加了芯片的存储器,提升了运行速度和性能,能够支持自适应巡航控制、智能大灯控制、车道偏离警告和盲点探测等应用。从整个雷达系统来看,结合 77G 雷达收发器芯片组、Qorivva MPC567xK MCU、FPGA, ADC, DAC, SRAM, 支持长、中、短距离应用。这里需要重点关注的是信号处理工具集(Signal Processing Toolbox)设计,包括了 FFT、DMA、COPY、Scheduler。目前 77GHz 的 FCMW 型雷达在数字信号处理中需要使用 FFT,即快速傅里叶变换,一般车载雷达的采样点在 512-2048 左右,从芯片架构图我们看到专门的FFT电路。
除了 S32V 系列,被收购的飞思卡尔有一款著名的 i.MX 系列芯片也可以作为中央处理器。i.MX 特别是 i.MX6 在汽车上,特别是车载信息系统上有大量的应用。众多的汽车厂商使用 i.MX。
英特尔/Mobileye/Altera
通过一系列的收购,英特尔在 ADAS 处理器上的布局已经完善,包括 Mobileye 的 ADAS 视觉处理,利用 Altera 的 FPGA 处理,以及英特尔自身的至强等型号的处理器,可以形成自动驾驶整个硬件超级中央控制的解决方案。
其中特别要指出的是 Mobileye 的 EyeQ 系列,已经被多家汽车制造商使用,包括奥迪、宝马、菲亚特、福特、通用、本田、日产、标致、雪铁龙、雷诺、沃尔沃和特斯拉等在内。最近的 EyeQ4 展示的性能已经达到 2.5 万亿次每秒的性能,其运行功率可低至 3W。从硬件架构来看,该芯片包括了一组工作在 1GHZ 的工业级四核 MIPS处理器,以支持创新性的多线程技术能更好的进行数据的控制和管理。多个专用的向量微码处理器(VMP),用来应对 ADAS 相关的图像处理任务(如:缩放和预处理、翘曲、跟踪、车道标记检测、道路几何检测、滤波和直方图等)。一颗军工级MIPS Warrior CPU位于次级传输管理中心,用于处理片内片外的通用数据。
由于目前融合多是雷达与摄像头融合,所需要的带宽,一般的 ASIC 都能够满足。但是要融合激光雷达,则最好用 FPGA,FPGA 做传感器 Hub 是最合适不过的。同时传感器融合目前应用较少,合适的 ASIC 并不好找,FPGA 成为主流选择。同时,对一些精度要求较高的雷达,如使用单精度浮点处理实现一个 4096 点 FFT,采样点越多,误差就越小,但运算量会大幅度增加。它在每个时钟周期输入输出四个复数采样。每个FFT内核运行速度超过 80 GFLOP,这一般需要 FPGA 才能比较好的实现。一般车载雷达的采样点在 512-2048 左右,但军用的可以达到 8192,必须配备 FPGA。如下图在 AudizFAS 的实物中,采用了 Altera的CycloneV SoCFPGA,作为 sensor fusion,同时负责毫米波雷达与激光雷达数据处理。
瑞萨(Renesas)
瑞萨针对 ADAS 处理器这一块业务,提供了较完整的产品线系列,也提供 ADAS Kit开发系统。就芯片系列来说,最出名的莫过于其R-Car产品线,该系列高配产品的硬件架构包括了 ARM Cortex A57/53、ARM Cortex R 系列、Video Codec,2D/3DGPU、ISP 等,能同时支持多路的视觉传感器输入,支持 OPENGL、OpenCV 等软件,符合 ASILB 车规级别。其实该产品最早是用于车载信息娱乐系统,而后该系统产品逐步适配汽车环视视觉系统、仪表板及 ADAS 系统等,该发展路径值得国内想进去汽车领域的半导体厂商借鉴。
除了 R-Car 系列产品外,就像 NXP 一样,瑞萨也有针对雷达传感器的专业处理器芯片如 RH850/V1R-M 系列,该产品采用 40nm 内嵌 eFlash 技术,优化的 DSP 能快速的进行 FFT 的处理。
最近有报道说瑞萨发布了 Renesas Autonomy,一个全新设计的 ADAS 和自动驾驶平台。具体细节还不清楚,但是据瑞萨电子美国区汽车业务副总裁Amrit Vivekanand指出,瑞萨此次推出的自动驾驶平台与竞争对手不同,「这是一个开放的平台,希望用户更方便地将他们的算法、函数库和实时操作系统(RTOS)移植到平台中来。」Renesas Autonomy 平台发布的第一个产品,是一块图像识别片上系统(SoC),叫作 R-Car V3M。瑞萨将该高性能视觉处理芯片描述为「优化处理单元,首选应用于智能相机传感器,也可以用于环绕视觉系统甚至激光雷达的数据处理。」来自半导体行业分析公司 Linley Group 的高级分析师 Mike Demler 认为,此次发布的开放平台和产品,可以看作一种瑞萨电子对标 Mobileye 的布局,「他们希望吸引到没有与Mobileye合作的汽车制造商,尤其是日本厂商,也希望吸引到一些制造ADAS产品的Tier 1厂商。」相比于Mobileye处理平台的「黑箱」系统,瑞萨在不断强调解决方案的「开放」二字,这也是每个誓要抗衡 Mobileye 的处理器厂商都倾向于谈论的问题。瑞萨方面表示,其最新发布的 R-Car V3M 处理模块的全部算法将对其用户开放。
英飞凌(Infineon)
作为汽车电子、功率半导体以及智能卡芯片的全球市场领袖,英飞凌一直以来为汽车等工业应用提供半导体和系统解决方案。英飞凌在 24/77/79G 雷达、激光雷达等传感器器件及处理芯片方面都具有领先的技术。除此之外,在车身控制、安全气囊、EPS、TPMS 等等各方面都有自己的解决方案。
德州仪器(TI)
TI 在 ADAS 处理器上实际上是走得两条产品线,Jacinto 和 TDA 系列。Jacinto 系列主要是基于之前的 OMAP 处理器开发而来,TI 在放弃移动处理器平台后,将数字处理器的重点放在了汽车等应用上,主要是车载信息娱乐系统。但是从 Jacinto6 中,我们看到车载信息娱乐与 ADAS 功能的结合,这款芯片包括了双 ARMCortex-A15 内核、两个 ARM M4 内核、两个 C66x 浮点 DSP、多个 3D/2D 图形处理器 GPU(Imagination),并且还内置了两个 EVE 加速器。这款 Jacintinto6 SoC 处理器的功能异常强大,无论是在处理娱乐影音方面,还是车载摄像头的辅助驾驶,可利用汽车内部和外部的摄像头来呈现如物体和行人检测、增强的现实导航和驾驶员身份识别等多种功能。
TDA 系列一直是侧重于 ADAS 功能,TDA3x 系列可支持车道线辅助、自适应巡航控制、交通标志识别、行人与物体检测、前方防碰撞预警和倒车防碰撞预警等多种 ADAS 算法。这些算法对于前置摄像头、全车环视、融合、雷达与智能后置摄像头等众多 ADAS 应用的有效使用至关重要。
英伟达(NVIDIA)
随着人工智能和无人驾驶技术的兴起,由于 NVIDIA 的 GPU 极强的并行计算能力,特别适合做深度学习。一般认为相对于 Mobileye 只专注于视觉处理,NVIDIA 的方案重点在于融合不同传感器,据传特斯拉已经放弃 Mobileye,而采用 NVIDIA。
NVIDIA 推出的 Drive PX2 被黄仁勋称「为汽车设计的超级电脑」,它将成为汽车的标准配备,可以用来感知汽车所处位置、辨识汽车周遭的物体,并且即时计算最安全的路径。Tegra X1 处理器和 10GB 内存,能够同时处理 12 个 200 万像素摄像头每秒 60 帧的拍摄图像,并通过环境视觉计算技术和强大的深层神经网络,主动识别道路上的各种车辆,甚至还能检测前方车辆是否在开门。Driver PX2 还搭载了其他合作伙伴的芯片,包括 Avago 的 PEX8724(24-lane,6-port,第三代 PCIe Gen交换机)用于两块 Parker 之间的互联。还有一片英特尔收购的 Altera 提供的 FPGA,用于执行实时操作系统。FPGA 的型号为 Cyclone V 5SCXC6,是 Altera 的顶级产品,逻辑运算为 110K,注册器达 166036。最后还有一款英飞凌的 AURIX TC 297 MCU 做安全控制,据说可以让 PX2 达到 ASIL C 级水平。 还有博通的 BCM89811 低功耗物理层收发器(PHY),使用 BroadR-Reach 车载以太网技术,在单对非屏蔽双绞线上的传输速率可达 100Mbps。所以 NVidia 实际上推出了板级的 ADAS 系统。
ADI
相对于以上介绍的几家芯片公司,ADI 在 ADAS 芯片上的策略主打性价比。ADAS 技术目前基本应用在高端车型中,主要是因为总体成本高,ADI 针对高、中、低档汽车,ADI 针对性的推出某一项或几项 ADAS 技术进行实现,并把成本降到 2 美元、十几美元,对整车厂商及消费者无疑是一大好消息。
在视觉 ADAS 上 ADI 的 Blackfin 系列处理器被广泛的采用,其中低端系统基于 BF592,实现 LDW 功能;中端系统基于 BF53x/BF54x/BF561,实现 LDW/HBLB/TSR 等功能;高端系统基于 BF60x,采用了「流水线视觉处理器(PVP)」,实现了 LDW/HBLB/TSR/FCW/PD 等功能。 集成的视觉预处理器能够显著减轻处理器的负担,从而降低对处理器的性能要求。
值得一提的是,ADI 最近推出 Drive360TM 28nm CMOS RADAR 技术(77/79GHz
),将绝佳的 RF 性能运用于目标识别和分类,革新了 ADAS 应用的传感器性能。ADI 的高性能 RADAR 解决方案能够提前探测快速移动的小型物体,而极低相位噪声能够在存在大物体的情况下对小物体进行最清楚的检测。ADI 与瑞萨合作,共同针对该芯片推出系统性方案,结合 ADI 的 RADAR ,以及瑞萨 Autonomy 平台的 RH850/V1R-M 微控制器(MCU)。
富士通(Fujitsu)
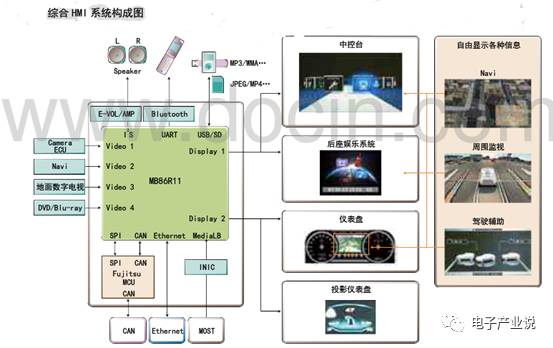
富士通的 ADAS 技术主要涉及透过摄像头和传感器的结合,实现图像识别辅助和接近目标检测,应用的领域主要有 360 度 3D 立体全景辅助、可视停车辅助、驾驶盲区监控、安全开车门以及车行驶方向周围的障碍物和行人的识别。包括基于 MB86R11「Emerald-L」2D/3D 图像 SoC 的全景视频系统支持前后左右四个摄像头进行汽车周边环境的实时全景视频监测。从公开资料显示,富士通似乎更热衷于虚拟仪表盘及车载信息娱乐系统的构建,但这一块是最容易被国内芯片公司模仿并超越的。
东芝(Toshiba)
最新的消息是,东芝将把业务拆分成四项,分别为社会基础设施业务、火力发电等能源业务、存储器以外的半导体和存储业务、信息通信技术(ICT)解决方案业务。所以未来东芝有很大的不确定性,但是从 ADAS 处理器来说,东芝有图像识别处理器 Visiconti 系列产品,目前第二代产品(Visconti2)已经量产,2015 年 11 月开始,通过日本电装公司的产品,搭载于丰田普锐斯量产车大批量投放市场,每月全球出货 3 万台以上。
Visiconti 采用多核异构的专用处理器,Visconti2 可实时处理,并行实现 4 项功能,如车道保持、前车检测、行人辨识、交通标志辨识。Visconti4 图像识别处理器可轻松对车辆和行人加以辨识,对交通信号、障碍物、行车线等信息加以识别,从而实现各种高级的驾驶员辅助应用,如入车道偏离警告、前方/后方防撞警告、前方/后方行人防撞警告、交通标识识别等,能同时处理并实现 8 项功能。

赛灵思(Xilinx)
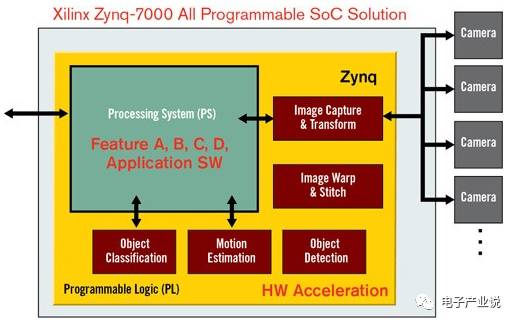
Xilinx 是著名的 FPGA 公司,其产品被广泛应用于各个领域。FPGA 的好处是可编程以及带来的灵活配置,同时还可以提高整体系统性能,比单独开发芯片整个开发周期大为缩短,但缺点是价格、尺寸等因素。在汽车 ADAS 上,Xilinx 最被广泛应用的产品是 Zynq®-7000 All Programmable SoC。该系统(SoC)平台可帮助系统厂商加快在环绕视觉、3D 环绕视觉、后视摄像头、动态校准、行人检测、后视车道偏离警告和盲区检测等 ADAS 应用的开发时间。Zynq 采用单一芯片即可完成 ADAS 解决方案的开发。Zynq-7000 All Programmable SoC 大幅提升了性能,便于各种捆绑式应用,能实现不同产品系列间的可扩展性。其次,它实现了 ADAS 优化的平台,可以让汽车制造商和汽车电子产品供应商在平台上添加自己的 IP 以及 Xilinx 汽车生态系统提供的现成的 IP 从而能够创建出独有的差异化系统。
文章来源:中汽创新创业中心
责任编辑:十里春风
-END-
文章精选
企业家
智能驾驶
测试时间从500年减少到半年,这才是美国联邦自动驾驶法案的本质意义
新能源汽车
项目和评论
这些大神从Google出走,创办了五家(命运各异的)无人车公司
60岁英国传奇创业老兵再战自动驾驶,FiveAI融资2680万英镑
厚
势
汽
车
为您对接资本和产业
新能源汽车 自动驾驶 车联网
联系邮箱
bp@ihoushi.com

点击阅读原文,查看[60岁英国传奇创业老兵再战自动驾驶,FiveAI融资2680万英镑]




