分享嘉宾:马里兰大学 博士生 朱晨
编辑整理:李淑娜
内容来源:将门线上直播181期
出品平台:将门、DataFun
注:欢迎转载,转载请留言。
导读:
大家好,今天介绍的是暑期我在微软实习期间主要做的工作,关于自然语言模型对抗训练的问题,也就是使用更好的对抗训练的方式增强transformer-based的模型在自然语言理解领域的效果。这项工作由我和我的几位mentor,导师以及manager一起完成的。
https://github.com/zhuchen03/FreeLB
https://arxiv.org/pdf/1909.11764.pdf
-
-
关于transformer-based模型的对抗训练
-
对输入的样本做微小的改动很容易让机器学习模型出现误判,这种操作称为对抗性攻击,这对实际应用模型带来了极大的风险。一般情况下我们通过在输入中加入对抗样本,使得样本能够正视这种微小的改动,从而增加模型的鲁棒性。
对抗训练最初用于图像识别领域,然后演变到自然语言处理的对抗训练,我们也是基于前人的理论上对自然语言中的对抗训练进行了改进。
最初的对抗样本概念是基于图像领域,就是我们对一张自然的图片加一个人眼不可见 ( 微小 ) 的扰动,这种扰动不改变图像本身的类别,但是神经网络模型却把他识别为一个完全不同的类别。比如图片中本来是一个"pig",通过加入一个微小的扰动,模型却识别为"airliner"。这种对抗样本对于普通的神经网络来说几乎是普遍存在的,或者说对任意的图片我们都能找到对抗样本使得神经网络模型预测出现错误,利用这种操作我们几乎能使模型在训练集上的准确率降为0;在自然语言中也存在对抗样本,但是构造对抗样本比图像领域要复杂一些,根据Ribeiro在文章中提出的,根据一些词变换的规则 ( Semantically Equivalent Adversarial Rules ) 来生成对抗样本,比如把"What is"改成缩写形式"What's", 或者在语句结束时多加一个问号"?",就能使得基于神经网络的自然语言模型在某些情况下给出一个错误的分类。
为了提升使图像分类器对抗攻击的鲁棒性,可以使用对抗样本训练模型。具体的做法是在训练的过程中,动态生成对抗样本,同时优化模型使得在对抗样本上的损失函数尽可能小。这个优化问题是一个min-max问题,max部分要找到一个图像上的扰动δ使其尽可能增大损失函数,尽可能让模型错分类,同时要求它的模 ( ||δ||
F
) 尽可能的小,就是尽可能的肉眼不可见,不改变原图像实际的类别。优化问题可以通过映射梯度下降 ( Projected Gradient Descent ) 的方式来求解。首先对δ进行梯度上升,并保证||δ||
F
小于一定的值,通过K步操作后,然后再进行一次梯度下降。这种加入对抗样本的训练方式可以提高分类器的鲁棒性,但同时分类器在原数据集的干净测试集上分类的准确率也会下降,这个是副作用。提升鲁棒性的原因在于分类器在使用包含对抗样本训练后泛化性能明显提升。这种泛化性排除了数据集的bias,所以在测试集上的准确率有所下降,但模型捕捉的特征也更接近于人的认知。如果把训练过程中梯度下降过程的可视化图片中,可以看出,对普通模型的预测影响最大的图像特征基本上是随机的,和输入的图片中物体的实际轮廓关系不大,但是经过对抗训练的模型会捕捉到图片中鸟或者飞机的边缘,使得分类器和人的感知非常接近,这也就说明了对抗训练的模型是鲁棒的。
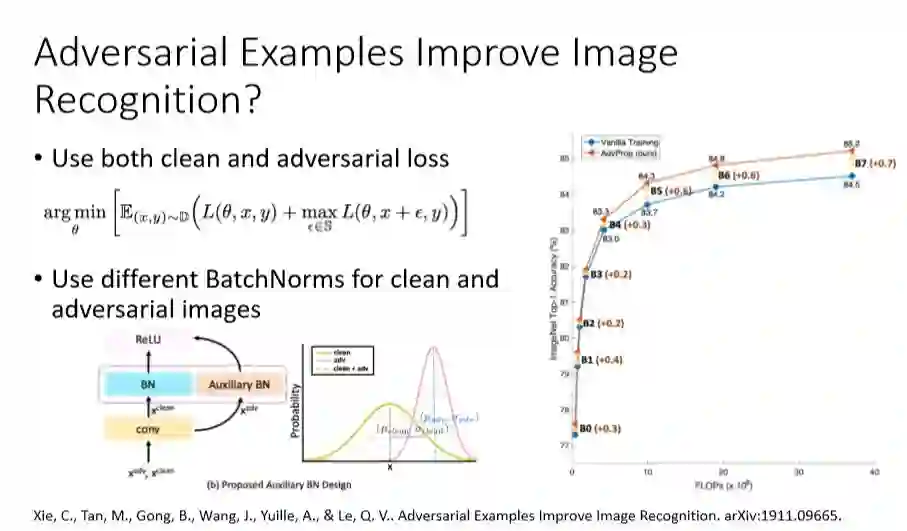
但是,近期来自JHU和Google的一篇文章中提出一种对抗训练方法,能够提升模型在干净样本测试集上的准确率。和前文所述Madry等人的训练方法不同,其损失函数同时包含了干净样本和对抗样本,并且对干净样本和对抗样本分别使用两组不同的Batch Normalization。作者们通过对比干净样本和对抗样本的Batch Normalization的参数,发现二者概率分布不同,所以在训练过程中对干净样本和对抗样本分别采用了不同的Batch Normalization。预测时,只使用干净样本对应的BatchNormalization参数,最终在ImageNet数据集上将Efficient Net的TOP1的准确率最高提升了0.7个百分点,并且在数据越大的情况下提升越明显。这给我们提供了一个使用对抗训练来提升模型准确率的一种方式。
自然语言中生成对抗的句子是有一定难度的,一般最常用的方法,是把句子中的一些词替换成他的近义词。对扰动也采用一种梯度上升的方式,具体做法是通过替换后的embedding向量和原句子的embedding向量求得差向量后,再求与梯度向量求夹角,夹角越小说明对损失函数的增加越多。一般情况下都是通过这种方式结合近义词替换的约束来构造一些对抗样本,但是这种近义词替换与上下文关系密切,所以有时候也存在一些不合理的情况。比如图片中"He has a natural gift for writing scripts."中的"gift",在此句中是"天赋"的意思,第二句中的"talent"也有天赋的意思,但是第三句中的"present"虽然和"gift"也是近义词,都有"礼物"的意思,但是在上下文中确实不合理的。采用这种词替换的方式时还需要结合其他约束方式来过滤掉那些不合理的对抗样本,比如使用back-translation scores,但是这种方式需要使用额外的机器翻译模型,在每次生成对抗样本时检测一次,这种方式的效率非常低;另一种方式就是找一些通用的语言规则,比如缩写 ( what is 替换成 what's ),名词换成指示代词 ( noun>this/that/it ) 等语义等价对抗规则 ( semantically equivalent adversarial rules,简称SEARs ) 方式来生成对抗样本。
这种语义等价对抗规则产生的对抗样本基本上保留了原义,但不是一种非常有效的攻击方式,从实验中我们可以看到SEARs在数据集Visual QA和Sentiment Analysis上产生对抗样本的准确率最低只降到10.9%,这点跟之前提到的图像对抗攻击不同,在图像上对没有经过对抗训练的模型准确率能够降底到0。实验证明SEARs对抗训练在数据集上的准确率表现也一般,而且也只能有限降低抵抗对抗样本的敏感性。
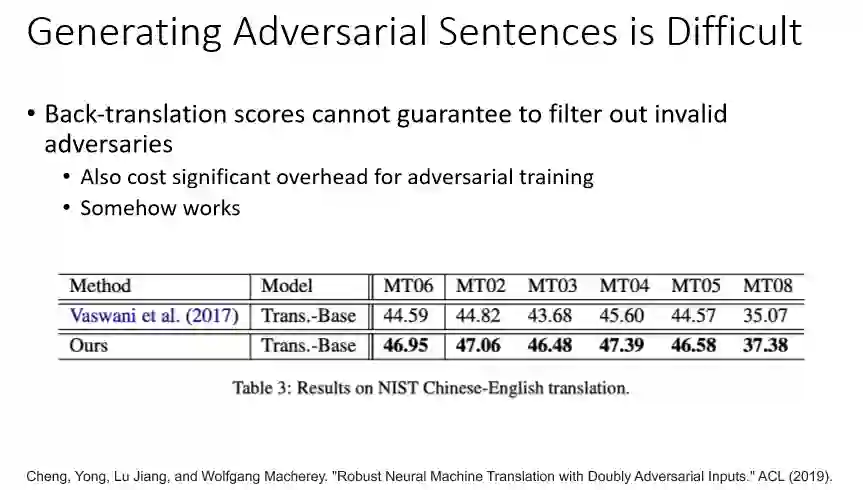
Back-translation scores 不能保证一定能生成有效的对抗样本,但确实提升模型的识别性能。在ACL paper
[5]
中在机器翻译的过程中生成了一些对抗样本,模型通过Back-translation Score过滤掉了一些不合理的对抗样本,提升了模型的准确率。
由于在每一步梯度上升的过程中,需要对每种可能的词替换计算Back-translation Score,这种模型的消耗巨大,运行时间长,所以也不是最优的方式。
另一种比较简单粗暴的方式就是直接在词的embedding上加入对抗扰动,虽然有时加入扰动不一定能够真正对应到词的embedding,但是以提升对抗训练模型的性能为目的,而不关心生成的对抗样本的质量,那这种方式也是可以采取的。图中r是生成的对抗扰动,v是原来输入词的embedding向量,模型采用LSTM,把r加入到这个图模型中,加入的扰动不影响整个模型的训练,仍然可以用梯度下降求出embedding中更新参数的梯度,这种方式早在2017年被Goodfellow
[6]
用来增强语言模型的性能,当时通过对抗训练把错误率从7.33%降低到6.21%。后来又提出了一种半监督的训练方式,在原来数据集中增加了一些没有标签的数据,通过最小化无标签数据的KL散度,最小化邻域内最大的KL散度。通过增加无标签的数据之后,错误率由6.21%降低到5.91%。在embedding中加入对抗扰动是目前一种比较有效的方式,我们的工作中也是采用了这种方式引入的对抗扰动。
▌关于transformer-based模型的对抗训练
前面介绍的都是现有的一些对抗训练的方法,接下来介绍一下我们的方法,以及一些相关的方法。
① 我们只是在fine-tuning的阶段做了对抗训练任务,没有在Bert等类似的预训练阶段加入对抗训练,主要是预训练本身就需要较大的计算量,而对抗训练会额外增加一些计算量,所以在大量的数据集上我们没有在预训练的阶段做对抗训练;
② 我们也是在词的 embedding上加入了一些扰动;
③ 我们保持了Bert和RoBERTA预训练模型的超参数,只改变我们加入了对抗训练部分的超参数。
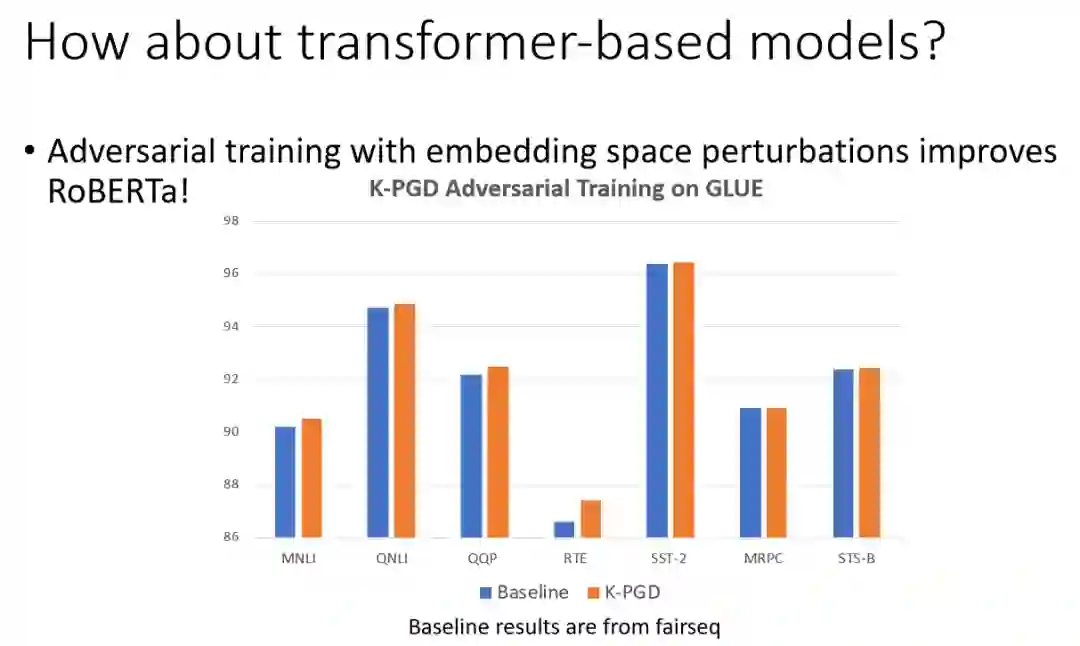
普通训练模型RoBERTA为baseline,对抗训练的baseline实验是在加入了扰动后的embedding数据后采用K-PGD进行对抗训练,与RoBERTA模型相比,K-PGD不会降低RoBERTA的性能,并且在大部分数据集中有所提升。
1.
标准的对抗训练:映射式梯度下降(Projected Gradient Descent)
K-PGD的一般流程如下,如果输入词向量大小是n×d,那么我们加入的扰动delta也是n×d,并且||δ||
F
小于epsilon,在K步的梯度计算过程中首先要初始化δ
0
,然后计算K步增加的梯度,通过g
adv
/||g
adv
||
F
模,乘以单步的学习率,加上前一步的δ值,最后得到的δ都会映射到约束范围内 ( 如果超过ε则取ε值 ),这种normalization的操作是加快模型收敛的速度,因为模型训练趋近最优值附近时梯度比较小,通过这种标准化操作可以增加有效的步长,收敛更快。
K-PGD优点和缺点:
梯度更新时对输入的embedding求的梯度,在这个过程中也可以得到所有神经网络参数的梯度,并不需要额外的计算量。在FreeAT和YOPO两篇也是利用用梯度上升过程获取参数的梯度,来减少总的前向-后向传播的次数。
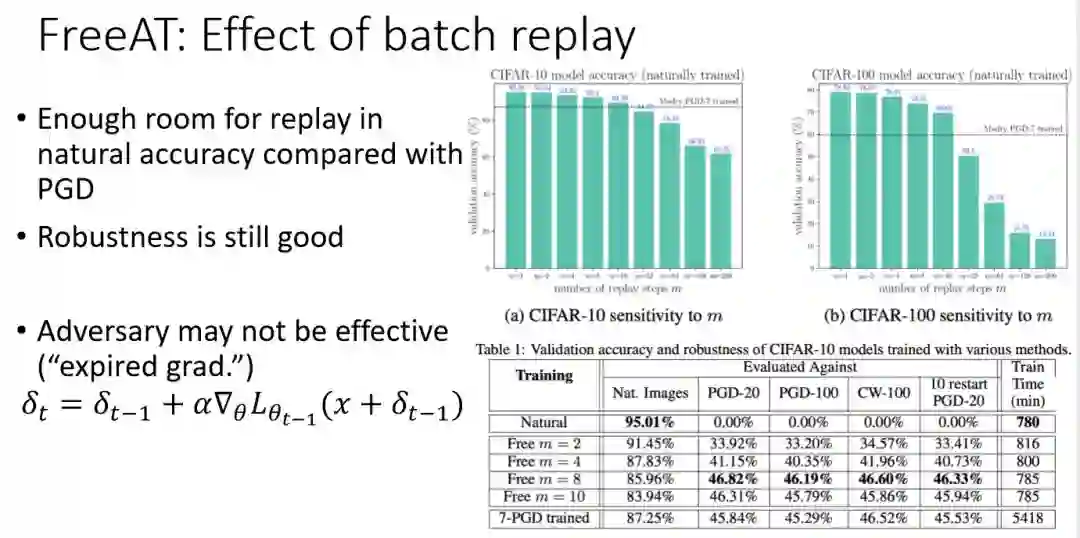
利用之前对输入求梯度进行梯度上升的过程中可以获得参数θ的梯度,所以FreeAT中对输入每做一次梯度上升时,同时对参数θ做一次梯度下降操作。在K-PGD中比如K=2,那么需要经过3步 ( 梯度上升之后 ) 才更新一次参数,但FreeAT每一步迭代生成对抗样本时,参数θ也同时更新,总的对抗训练步骤和普通模型训练时一致,消耗时间也近似,但是比K-PGD缩短了很多。
但FreeAT也有副作用,就是会在同一个样本附近更新多次参数,PGD的随机性有助于模型的泛化能力。参数在一个batch的样本上梯度下降m次得到结果称为batch replay,参数更新次数越多,模型准确率随之下降的越多。柱状图是模型普通训练方式 ( natural trained ) 的准确率和训练次数的关系,根据这个关系在FreeAT中设置replay=8,训练时间比普通模型多5min,准确率保持与PGD差不多,但是鲁棒性有所提升。
但是FreeAT中也存在一些问题,我们看到δ
t
更新的公式中,δ
t
是θ
t-1
的函数,就是每次更新时仍然使用了上一步骤中的参数,参数存在滞后性,所以产生的对抗效果不够强。
YOPO模型中每进行一次前向-后向传播后,固定损失函数关于第一层输出的梯度,然后用梯度乘以第一层对抗样本参数的雅克比矩阵来更新梯度,这一操作被称为innter steps,这个过程重复n步,这种方式也能增加对抗样本的额强度,减少了整个前向-后向传播次数。比如之前使用K-PGD得到了一些对抗样本,而使用YOPO仅用K/2步就可以得到相同强度的对抗样本。
YOPO外层循环更新参数的梯度时会叠加上inner step中生成对抗样本时每一步的梯度 ( g
θ(1)
,g
θ(2)
),一般是这些梯度的平均值。这种做法有点类似于通过增大batch size的方式来加快模型的收敛。YOPO训练速度比其他对抗训练方式要快很多,准确率相比FreeAT也有提升,同时也提升了模型的鲁棒性 ( 防御攻击能力 )。最后文章并未指出通用的规则来表示具体减少的循环次数,只是发现用了更少的循环次数,得到了更好的结果。
我们也同时存在疑问:文章中的inner step是必须存在的吗?
文中所说的第一层是卷积操作,而卷积的操作是一个线性操作,所以第一层的梯度是一个常数,这样inner step中传递的梯度与对抗样本无关,虽然考虑了projection的梯度上升过程,比如循环了2次,那么只是相当于是用了两倍的步长更新参数,inner step没有起到明显的作用。但是文章提出的对抗训练思想还是很有借鉴意义的。
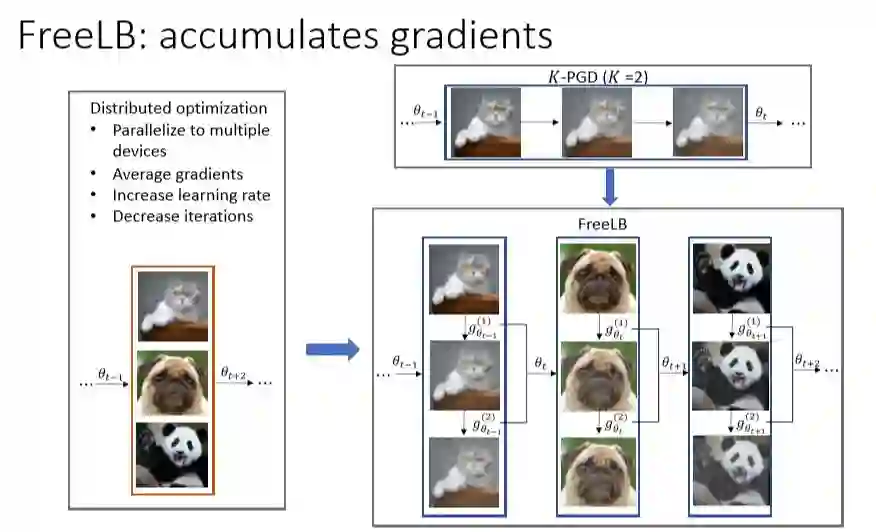
在我们的实验中,就借鉴了YOPO的对抗训练方式,但我们摒弃了YOPO提倡的inner step步骤。这样,我们的模型只在K步梯度上升的过程中积累梯度,并在之后用积累的梯度进行参数更新。这与并行优化非常类似,如左图所示,并行优化会将3个图片分别放在了3个GPU上进行训练,同时各自计算梯度,然后计算三个图片的平均梯度,这样batch size相当于原来的的3倍,模型训练时的learning_rate也可以增加到原来的3倍,但总迭代次数可以减少到原来的1/3,并且往往能达到同样的效果。自然语言理解任务,尤其是GLUE上所需要的迭代次数一般较少,所以与之不同的是,我们没有将总迭代次数 ( 模型参数更新次数 ) 减少到原来的1/K,但这种方式相比于K-PGD仍然提高了梯度的利用率,并能够进一步提升模型性能。
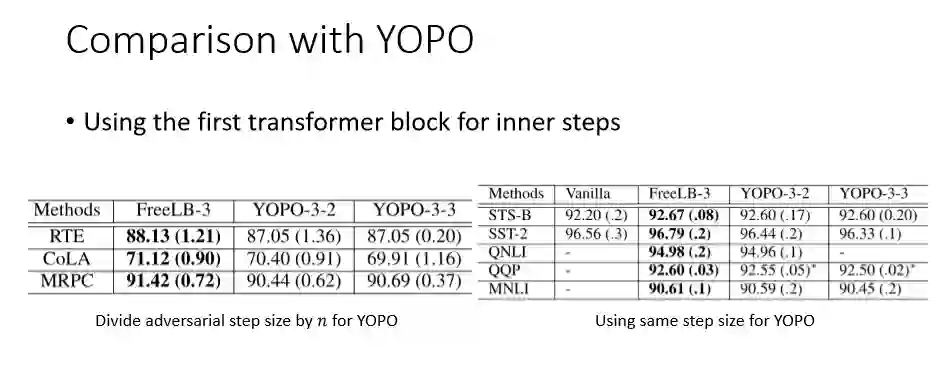
我们将我们的方法与YOPO进行对比。在实现YOPO时,我们把第一层换成了非线性的,这样在inner step中传递的梯度就不是一个常数。
我们尝试了不同inner step的数量,YOPO-3-2 就是包含了2个inner step,YOPO-3-3 就是包含了3个inner step。同时,为保证等效步长一致,在左图中,我们还将每个inner step的长度换成FreeLB-3的梯度上升步长除以inner step数。而在右图中每个inner step的步长和FreeLB一致,这样YOPO等效步长更长。根据实验结果,我们发现inner step过程没有表现出期望的结果,有时增加inner step还会使结果变差。步长大一些的时候 ( 右图 ) YOPO与FreeLB的差距会缩小,但仍然没有变得更好。
之前提到我们把生成的对抗样本加入到了模型的输入中,相当于增加了数据的batch size,目标函数可以看成最大化对抗样本的损失函数在某个邻域内的值,当有K个对抗样本时,相当于优化了在原来输入样本附近的K个不同区域的最大loss值。最后对目标函数求最小值来优化求解模型的参数,进行预测。我们的方法确实有一定的提升,但是背后的原因目前还没有去进一步证明,有文章指出
[8]
,如果一个模型对T中不同的变换,比如对输入进行了T种变换但预测结果都是正确,那么这模型的泛化错误率还比原来没有变换的模型降到根号T倍 ( 上限 )。
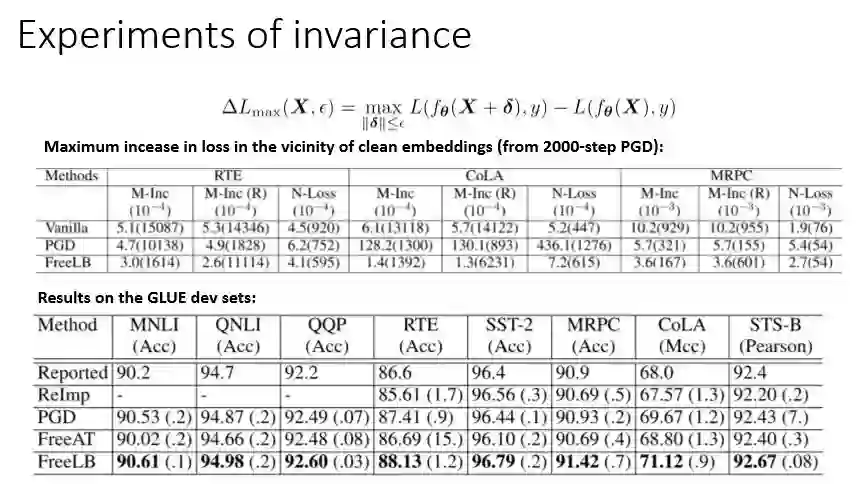
实验中的算法会积累中间对抗样本的梯度,在K步之后更新参数,积累得到的对抗样本的梯度都是使用当前步骤下的参数,避免了FreeAT中参数过期的问题, 所以实验结果性能优于其他对抗训练的模型。并在GLUE很多数据集上都得到了好的结果。
Dropout的影响在图片的抗训练领域里没有得到广泛关注,因为目前在图像领域在大多情况下已经不再使用Dropout了,但是在基于Transformer的语言模型里还是需要使用Dropout,即使是在fine tuning过程,我们仍使用了Dropout。为了增加对抗的强度,我们需要在每步梯度上升时固定Dropout Mask, 这与FreeAT过期问题相似,因为网络每一层的结构都不相同,得到的输入梯度有很多的噪声。从目标函数的角度来看,我们想优化对于不同dropout mask下损失函数的期望,损失函数在K-step里是所有样本损失之和,所以需要在每一步里的dropout保持相同。
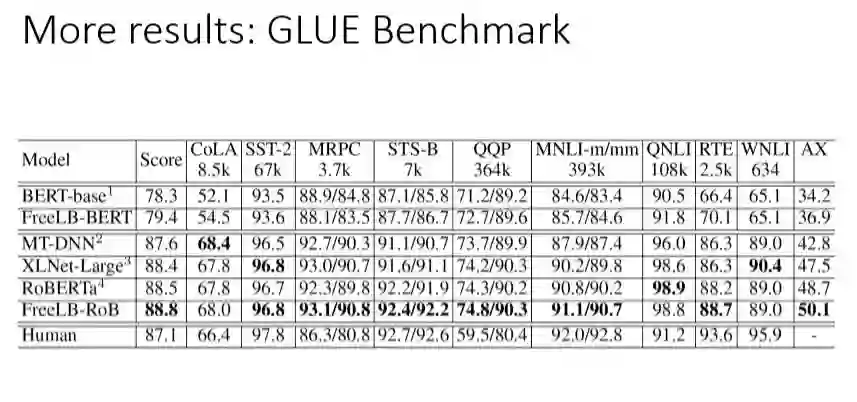
将我们的模型用于GLUE的其他数据集上也有一些得到了不同程度的提升,另外将FreeLB用在BERT-base模型上,整体的score提升了1.1%,用在RoBERTa模型上能提升0.3%,另外有时候FreeLB单个模型,性能远远超过了一些集成的模型。
对抗训练可以提升自然语言模型预测的性能,虽然我们只是把对抗训练过程用在fine-tuning阶段内,也同样提升了模型的准确率。从大量实验中可以看出对抗训练在提升模型的泛化能力上潜力巨大。
未来希望能够找到一种使得对抗训练,能够运用在语言模型预训练阶段的高效对抗训练方法,预训练阶段需要相当大的计算量,目前认为最简单的解决方式也是使用large-batch的训练方式。最后感谢我的导师和mentor们,也感谢一起实习工作的同事,与他们的日常交流也使我受益匪浅。
PS:欢迎加入 DataFunTalk NLP交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:DataFunTalker ),回复:NLP,逃课儿会自动拉你进群。
1. J. Goodfellow, J. Shlens, and C. Szegedy. Explaining and harnessing adversarial examples. arXiv:1412.6572.
2. Ribeiro, M. T., Singh, S., & Guestrin, C.. Semantically equivalent adversarial rules for debugging nlp models. ACL (2018).
3. Tsipras, D., Santurkar, S., Engstrom, L., Turner, A., & Madry, A. (2018). Robustness may be at odds with accuracy.ICLR (2019).
4. Xie, C., Tan, M., Gong, B., Wang, J., Yuille, A., & Le, Q. V.. Adversarial Examples Improve Image Recognition. arXiv:1911.09665.
5. Cheng, Yong, Lu Jiang, and Wolfgang Macherey. "Robust Neural Machine Translation with Doubly Adversarial Inputs."ACL(2019).
6. Miyato, T., Dai, A. M., & Goodfellow. Adversarial training methods for semi-supervised text classification.ICLR (2017).
7. Shafahi, A., Najibi, M., Ghiasi, A., Xu, Z., Dickerson, J., Studer, C., ... & Goldstein, T.. Adversarial Training for Free!. NeurIPS(2019).
8. Sokolic, J., Giryes, R., Sapiro, G., & Rodrigues, M. Generalization Error of Invariant Classifiers. AISTATS (2017).
![]()
文章推荐:
识别下方二维码,关注"DataFunTalk"并设置成☆星标,第一时间关注,最新干货文章。
![]()
DataFunTalk:专注于大数据、人工智能技术应用的分享与交流。