AI赌神称霸德扑的秘密,刚刚被《科学》“曝光”了
夏乙 问耕 发自 凹非寺
量子位 出品 | 公众号 QbitAI
称霸德州扑克赛场的赌神Libratus,是今年最瞩目的AI明星之一。
刚刚,《科学》最新发布的预印版论文,详细解读了AI赌神背后系统的全貌。此前的NIPS 2017大会上,最佳论文就颁给了Libratus团队,不过那篇会议论文只是重点讲述这个德扑AI中的子博弈求解算法。

在最新论文Superhuman AI for heads-up no-limit poker: Libratus beats top professionals中,卡内基梅隆大学(CMU)的博士生Noam Brown和教授Tuomas Sandholm,详细介绍了德扑AI如何通过将游戏分解为可计算、可管理的部分,来实现超越人类的表现,而且AI还能根据对手情况,修正潜在的战略弱点。
Libratus所用到的技术既不需要领域专家知识,也没有使用人类数据,甚至不是专门为扑克设计的。换句话说,这些技术适用于多种不完美信息博弈。
不完美博弈正是德扑的一个主要特征。围棋、国际象棋、跳棋等棋类游戏,属于完美信息博弈,对战的双方,清楚每一时刻局面上的全部情况。相比之下,德州扑克存在大量的隐藏信息,包括:对手持有什么牌,对手是否在诈唬?
详解Libratus
据最新论文介绍,Libratus主要包括三个模块。
第一个模块负责对牌面进行简化计算,将包含10161种情况的一对一无限注德扑抽象成一个比较简单的博弈。然后,这个模块为前两轮制定详细的策略,并为后两轮制定一个粗略的策略。这个抽象简化版博弈的解决方法称为蓝图策略(blueprint strategy)。
这种抽象体现在两个方面,一是下注金额上,二是牌面上。
在下注金额上,100美元和101美元其实几乎没有差别,因此,算法可以对不到100美元的差异进行四舍五入。同时,将类似的牌面视为同一类,也能降低计算的复杂度。
需要说明的是,Libratus在后两轮游戏中并不会按照抽象版的解决方法来玩,蓝图策略在这两轮中的作用,只是用来估算玩家在子游戏中每一首牌应该得到的奖励,然后参考这个估算值,在真正的牌局中做出更精确的策略。
这个“更精确的策略”,也就是第二个模块:嵌套安全子博弈求解(Nested safe subgame solving)。在博弈后期,这个模块会基于当前的牌面,构建一个全新的、更精细的抽象,而且对这个子博弈的策略进行实时计算。
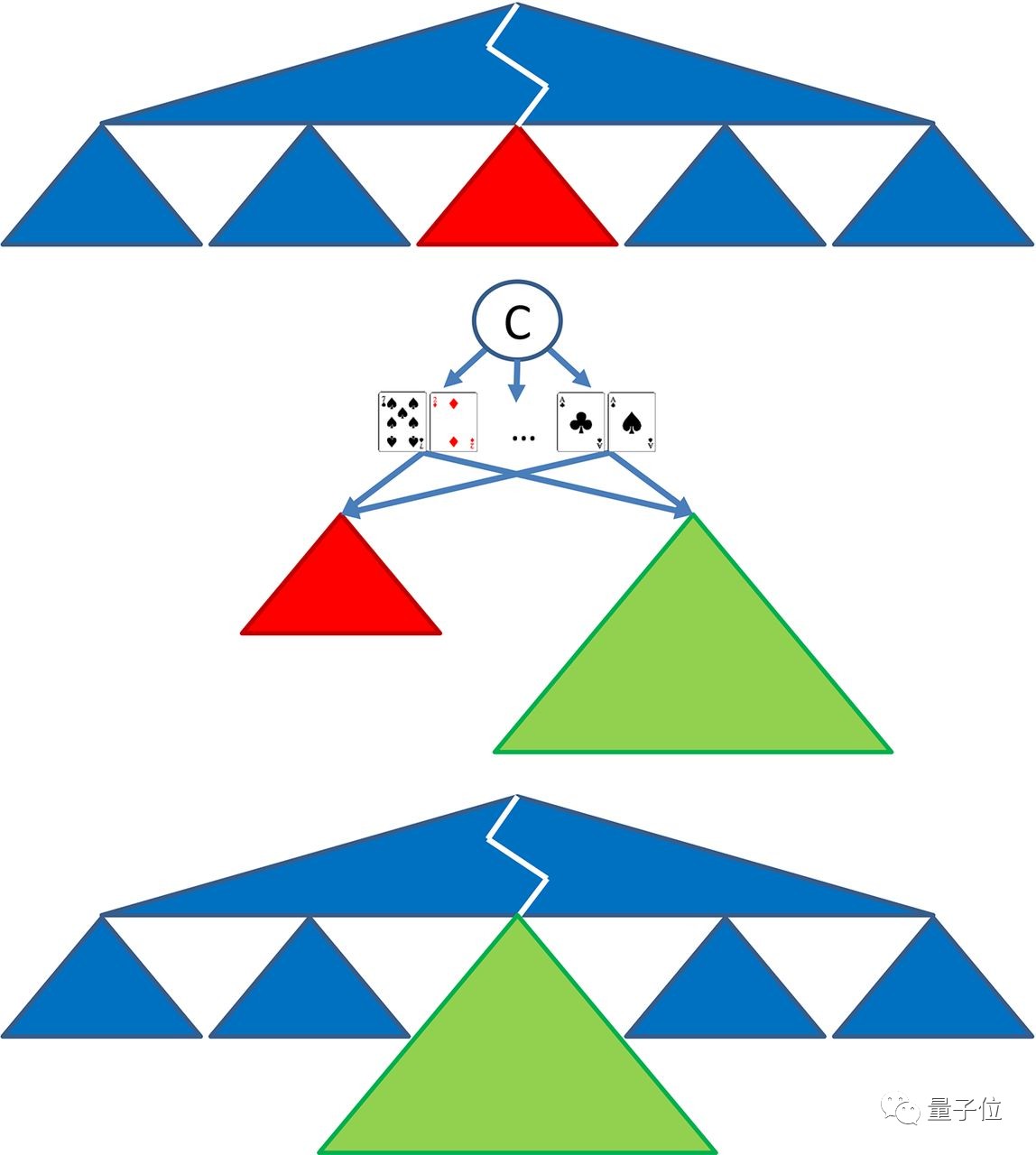
△ Subgame solving
上图是Libratus的子博弈求解过程。顶部表示在对局过程中出现了一个子博弈,中间部分表示算法为这个子博弈制定了更详细的策略,每次迭代中,对手随机发放一手牌,可选的期望值可能来自旧的抽象(红色),也可以来自新的、更精细的抽象(绿色)。如果期望值来自新的抽象,两个玩家的策略都会改变。这就迫使Libratus制定更精细的策略。上图底部表示用新的策略替代旧策略。

△ nested subgame solving图解
Libratus的子博弈策略计算和那些完美信息博弈不太一样,它需要确保这些子博弈的精细解决方法与整个博弈的大蓝图策略不冲突,而不能孤立地解决它。
第三个模块的意义,是随着比赛的进行,改进自身的蓝图策略。Sandholm教授表示,通常AI使用机器学习来发现对手的战略错误并加以利用。但这也会让AI暴露自身的弱点,并被对手加以利用。
不同之处在于,Libratus的自我改进模块分析对手赌注大小,以检测自身蓝图战略中潜在的漏洞,然后弥补自身的不足之处。
在与人类高手对战之前,Sandholm和Brown为了测试Libratus中所用的各项技术,先用简化版的扑克对整体流程进行了测试,然后把AI用到了完整版的一对一无限注德州扑克上,和他们自己之前开发的Baby Tartanian8进行比赛。
2016年,Baby Tartanian8曾经赢得电脑德扑大赛冠军,不过Libratus以63±28大盲注/千手(mbb/hand)的战绩击败了它。
“我们研发的技术在很大程度上是独立于领域的,因此可以应用于其他不完美信息策略应用,不仅限于游戏领域”,Sandholm和Brown总结说:现实世界的战略交锋中,隐藏信息无处不在,Libratus引入的范式对AI未来的发展和引用至关重要。
目前,这项技术已经授权给Sandholm创办的公司。
论文地址
http://science.sciencemag.org/content/early/2017/12/15/science.aao1733
独家对话
今年3月,量子位前往CMU专程拜访过Sandholm和Brown。当时,他们就曾谈及Libratus的理念,包括三个模块的设计思路。
这里也把量子位之前报道的内容摘录如下。
无师自通
在德扑这件事上,Libratus没有师父。
Sandholm和Brown只告诉AI基本的德州扑克规则,然后Libratus就开始通过“左右手互搏”的方式学习这个扑克游戏。和AlphaGo不同,在人机大战之前Libratus没有研究过人类如何打德州扑克,也没有和人类职业玩家有过交手。
在投入实战之前,Libratus自己对战了几百万手牌,其中有不少是带有特定目的的残局,真正机器和机器之间的交手,大约是几十万手。
所以,AI形成了一种与人类迥然不同的牌风。
“在德扑比赛中,顶级高手会尝试寻找对手的弱点,并展开攻击”,创新工场AI工程院技术VP李天放说。李天放既有技术背景,也是一名德扑高手。
Dong Kim是今年1月德扑人机大战中的一位人类选手,这位28岁的韩裔美国人回忆说,每一天Libratus都会进步,人类选手很难找到它的弱点或漏洞。即便找到一个,第二天就会消失不见。这让他感到绝望。
但也许他根本就感觉错了。“有人类玩家说找到了漏洞,其实不一定”,Brown对量子位说:“这可能是Libratus的一种战术,去搅乱对手的策略”。

△ Brown身后是他的电脑
不能用人类的思维去衡量AI。让Sandholm记忆犹新的是,1月的德扑人机大战进行到尾声,当时AI早已遥遥领先,所有人都认为Libratus会趋近于保守。
“但它反而越来越激进”,Sandholm说特别是最后几局,非常出人意料。
比方,为了一个很小的底池推了All in,或者下注额只有底池的十分之一。“有时候Libratus的策略会被认为是臭手”,但事后复盘Sandholm说这个德扑AI尝试了很多令人叫绝的方法,其中包括各种策略的诈唬。
诈唬也不是人教的,而是机器自己学会的。
怎么学?“诈唬是特别重要的技能,系统在学习中发现,如果有一手烂牌,直接诈唬能赢更多,所以它就学会了”,Brown告诉量子位。
“这就是AI特别奇妙的地方”,Brown坐在自己CMU标配的上一代Aeron座椅上说,“很多人看到Libratus能诈唬,觉得很了不起”,但在这位博士的眼中,诈唬这种看似与心理有关的人类技能,机器是可以通过算法学会的。
三个模块
为什么Libratus能比前代更厉害,进步在何处?Brown举了两个例子。
比如,对于K-High Flush(最大牌为K的同花)和Q-High Flush(最大牌为Q的同花),这两手牌对于Claudico来说是等值的,而Libratus则会做一个精确的区分。实际上,Libratus会对每一手牌进行单独的处理,根据不同的牌面制订出不同的战略。
再比如,对于250元的下注,是当成200元还是300元来计算?那么249或者251呢?实际上,Libratus不会尝试聚类,而是马上实时计算,得出胜算最大的策略。

△ Sandholm讲解冷扑大师
Sandholm则从全局的角度,打开Libratus的大脑,向量子位逐一讲解了构成这个扑克AI的三个主要模块。其中一个用于赛前,两个用于赛中。
模块一:Nash equilibrium approximation before competition(赛前纳什均衡近似)
这个模块把最重要的博弈信息进行抽取,比如针对某一手牌对应的战略,然后再应用强化学习等方法,继续寻求提高和改进。这里使用了一个新的算法:蒙特卡洛反事实遗憾最小化。在这个模型的帮助下,Libratus自己学会了德扑,而且比以前速度更快。
模块二:Endgame solving(残局解算)
这是Libratus最重要的部分,Sandholm说。实际上Claudico也有这个模块,但那个版本几乎不起作用。而新的版本不会再给对手留下漏洞,这个过程不断进行,对手新出一招后,会继续展开新的残局解算,这被称为Nested Endgame Solving。
德扑这类不完美信息博弈,不能拆解为可以独立解决的子博弈。所以Libratus采用的残局解算的方法应对,想进一步深究,可以查看Brown和Sandholm的论文。
模块三:Continual self-improvement(持续自我强化)
比赛中人类高手会寻找Libratus的漏洞,并展开有针对性的攻击。这个模块的作用就是发现问题所在,找到更多细节进行自我强化,然后得到一个更好的纳什均衡。
“三个模块都用了新的算法”,Sandholm说第一个模块的新算法能够抽取更多的细节,而且比原来的算法更快;第二个模块的算法是全新的;而第三个模块则有一个全新的理念,有点类似于:防守是最好的进攻。
Libratus不再寻求发现并利用人类对手的漏洞,相反,这个AI开始观察人类发现了它什么弱点,然后有针对性的弥补和提升。于是Libratus的弱点越来越少,直到人类玩家沮丧的发现,想要赢下比赛变成一件几乎不可能完成的任务。
不主动进攻就很少露出破绽,李天放说跟Libratus对战就像打一堵墙,最好的结果可能就是打个平手,基本不可能获胜。纳什均衡本身,追求的就是一种平衡。
Libratus是一个防守大师。
深度学习不是唯一
与围棋大师AlphaGo相比,Libratus有很多不同之处。其中就包括:Libratus并没有使用目前相当火热的深度学习技术。
“深度学习是个非常好的技术,但我们没有在这个项目应用,是因为深度学习不能给出绝对的保证。比方识别猫的图像,对于给定的图片能得出95%是猫,但也不是绝对的保证,而我们的算法,能够保证最优异的结果”,Sandholm说。
当然也有团队在用深度学习来搞德扑AI。
来自加拿大阿尔伯塔大学、捷克布拉格查理大学和捷克理工大学的研究人员,基于深度学习技术开发出德州扑克人工智能DeepStack。
对于两个德扑AI来说,还没有更好的比较方法,目前只能说Libratus击败的对手,要比DeepStack的对手水平更高。其他这里不展开讨论了,这个团队也发表了相关的论文。
“对这一类型的任务,我们的方案比深度学习更好”,Sandholm对量子位表示,目前深度学习的方案实际上没有解决问题,而Libratus这个系统“时间越长,越能接近完美”。
对于这个问题,我们询问了CMU机器学习系的邢波教授,他指出还不应过早的下结论说:深度学习就是机器学习的未来。
“Sandholm教授其实不是做深度学习的,他用的方法实际上被认为是是传统的AI,但是可以达到这么强大的功能”,邢波对量子位表示这是一个有力的证明:人工智能并不等于深度学习,很多新的方法需要探索和了解。
Libratus战绩回顾

今年1月,在匹兹堡河流赌场举办了一场为期20天的Brains vs. AI比赛,Libratus在一对一、无限注的德扑人机大战中,击败四位顶级人类玩家,累计赢得176.6万美元筹码。按照德扑的术语,Libratus与人类高手的差距是147大盲注/千手(mbb/hand),也就是场均14.7个大盲注。
今年4月,创新工场董事长兼CEO、创新工场人工智能工程院院长李开复,邀请Libratus和团队来到中国,以“冷扑大师”之名与“龙之队”展开对决。
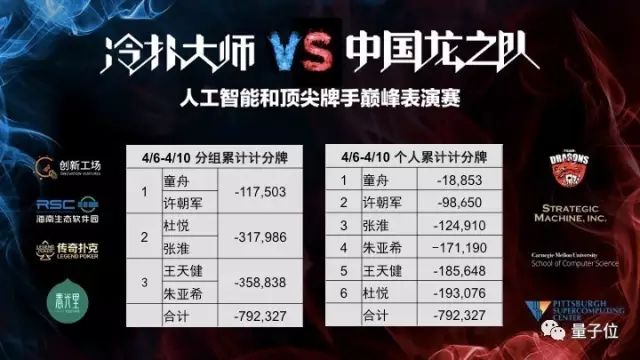
这场为期五天的对决中,冷扑大师以领先792327记分牌、每百手领先15.8大盲注的成绩击败人类对手。赢得200万奖金。
当时李开复表示,AI在征服了以不完美信息博弈为内核的德州扑克后,AI在游戏领域比人类更强已经没有任何悬念了。人机大战的结果证明AI比我们想象中来的更快,接下来要关注的应该就是AI在商业、医疗等领域的应用。
论文地址
— 完 —
活动报名
加入社群
量子位AI社群12群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态



