深度学习,怎么知道你的训练数据真的够了?
点击上方“计算机视觉life”,选择“星标”
快速获得第一手干货
最近有很多关于数据是否是新模型驱动 [1] [2] 的讨论,无论结论如何,都无法改变我们在实际工作中获取数据成本很高这一事实(人工费用、许可证费用、设备运行时间等方面)。
因此,在机器学习项目中,一个关键的问题是,为了达到比如分类器准确度等特定性能指标,我们需要多少训练数据才够。训练数据多少的问题在相关文献中也称为样本复杂度。
在这篇文章中,我们将从回归分析开始到深度学习等领域,快速而广泛地回顾目前关于训练数据多少的经验和相关的研究结果。具体来说,我们将:
说明回归任务和计算机视觉任务训练数据的经验范围;
给定统计检验的检验效能,讨论如何确定样本数量。这是一个统计学的话题,然而,由于它与确定机器学习训练数据量密切相关,因此也将包含在本讨论中;
展示统计理论学习的结果,说明是什么决定了训练数据的多少;
给出下面问题的答案:随着训练数据的增加,模型性能是否会继续改善?在深度学习的情况下又会如何?
提出一种在分类任务中确定训练数据量的方法;
最后,我们将回答这个问题:增加训练数据是处理数据不平衡的最佳方式吗?
01
训练数据量的经验范围
首先让我们看一些广泛使用的,用来确定训练数据量的经验方法,根据我们使用的模型类型:
回归分析:根据 1/10 的经验规则,每个预测因子 [3] 需要 10 个样例。在 [4] 中讨论了这种方法的其他版本,比如用 1/20 来处理回归系数减小的问题,在 [5] 中提出了一个令人兴奋的二元逻辑回归变量。
具体地说,作者通过考虑预测变量的数量、总体样本量以及正样本量/总体样本量的比例来估计训练数据的多少。
计算机视觉:对于使用深度学习的图像分类,经验法则是每一个分类需要 1000 幅图像,如果使用预训练的模型 [6],这个需求可以显著下降。
02
假设检验中样本大小的确定
假设检验是数据科学家用来检验群体差异、确定新药物疗效等的工具之一。考虑到进行测试的能力,这里通常需要确定样本大小。
让我们来看看这个例子:一家科技巨头搬到了 A 市,那里的房价大幅上涨。一位记者想知道,现在公寓的平均价格是多少。
如果给定公寓价格标准差为 60K,可接受的误差范围为 10K,他应该统计多少套公寓的价格然后进行平均,才能使结果有 95% 的置信度?
计算的公式如下:N 是他需要的样本量,1.96 是 95% 置信度所对应的标准正态分布的个数:
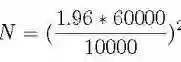
样本容量估计
根据上面的等式,记者需要考虑约 138 套公寓的价格即可。
上面的公式会根据具体的测试任务而变化,但它总是包括置信区间、可接受的误差范围和标准差度量。在[7]中可以找到关于这个主题的更好的讨论。
03
训练数据规模的统计学习理论
让我们首先介绍一下著名的 Vapnik-Chevronenkis 维度 ( VC 维) [8]。VC 维是模型复杂度的度量,模型越复杂,VC 维越大。在下一段中,我们将介绍一个用 VC 表示训练数据大小的公式。
首先,让我们看一个经常用于展示 VC 维如何计算的例子:假设我们的分类器是二维平面上的一条直线,有 3 个点需要分类。
无论这 3 个点的正/负组合是什么(都是正的、2个正的、1个正的,等等),一条直线都可以正确地分类/区分这些正样本和负样本。
我们说线性分类器可以区分所有的点,因此,它的 VC 维至少是 3,又因为我们可以找到4个不能被直线准确区分的点的例子,所以我们说线性分类器的 VC 维正好是3。结果表明,训练数据大小 N 是 VC 的函数 [8]:
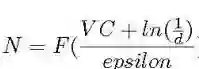
从 VC 维估计训练数据的大小
其中 d 为失效概率,epsilon 为学习误差。因此,正如 [9] 所指出的,学习所需的数据量取决于模型的复杂度。一个明显的例子是众所周知的神经网络对训练数据的贪婪,因为它们非常复杂。
04
随着训练数据的增加,模型性能会继续提高吗?在深度学习的情况下又会怎样?
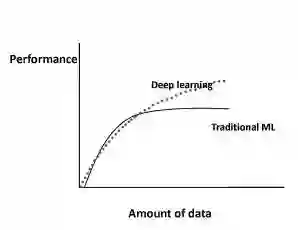
学习曲线
上图展示了在传统机器学习 [10] 算法(回归等)和深度学习 [11] 的情况下,机器学习算法的性能随着数据量的增加而如何变化。
具体来说,对于传统的机器学习算法,性能是按照幂律增长的,一段时间后趋于平稳。 文献 [12]-[16],[18] 的研究展示了对于深度学习,随着数据量的增加性能如何变化。
图1显示了当前大多数研究的共识:对于深度学习,根据幂次定律,性能会随着数据量的增加而增加。
例如,在文献 [13] 中,作者使用深度学习技术对3亿幅图像进行分类,他们发现随着训练数据的增加模型性能呈对数增长。
让我们看看另一些在深度学习领域值得注意的,与上述矛盾的结果。具体来说,在文献 [15] 中,作者使用卷积网络来处理 1 亿张 Flickr 图片和标题的数据集。
对于训练集的数据量,他们报告说,模型性能会随着数据量的增加而增加,然而,在 5000 万张图片之后,它就停滞不前了。
在文献[16]中,作者发现图像分类准确度随着训练集的增大而增加,然而,模型的鲁棒性在超过与模型特定相关的某一点后便开始下降。
05
在分类任务中确定训练数据量的方法
众所周知的学习曲线,通常是误差与训练数据量的关系图。[17] 和 [18] 是了解机器学习中学习曲线以及它们如何随着偏差或方差的增加而变化的参考资料。Python 在 scikit-learn [17] 也中提供了一个学习曲线的函数。
在分类任务中,我们通常使用一个稍微变化的学习曲线形式:分类准确度与训练数据量的关系图。
确定训练数据量的方法很简单:首先根据任务确定一个学习曲线形式,然后简单地在图上找到所需分类准确度对应的点。例如,在文献 [19]、[20] 中,作者在医学领域中使用了学习曲线法,并用幂律函数表示:
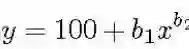
学习曲线方程
上式中 y 为分类准确度,x 为训练数据,b1、b2 分别对应学习率和衰减率。参数的设置随问题的不同而变化,可以用非线性回归或加权非线性回归对它们进行估计。
06
增加训练数据是处理数据不平衡的最好方法吗?
这个问题在文献 [9] 中得到了解决。作者提出了一个有趣的观点:在数据不平衡的情况下,准确性并不是衡量分类器性能的最佳指标。
原因很直观:让我们假设负样本是占绝大多数,然后如果我们在大部分时间里都预测为负样本,就可以达到很高的准确度。
相反,他们建议准确度和召回率(也称为灵敏度)是衡量数据不平衡性能的最合适指标。除了上述明显的准确度问题外,作者还认为,测量精度对不平衡区域的内在影响更大。
例如,在医院的警报系统 [9] 中,高精确度意味着当警报响起时,病人很可能确实有问题。
选择适当的性能测量方法,作者比较了在 imbalanced-learn [21] (Python scikit-learn 库)中的不平衡校正方法和简单的使用一个更大的训练数据集。
具体地说,他们在一个 50,000 个样本的药物相关的数据集上,使用 imbalance-correction 中的K近邻方法进行数据不平衡校正,这些不平衡校正技术包括欠采样、过采样和集成学习等,然后在与原数据集相近的 100 万数据集上训练了一个神经网络。
作者重复实验了 200 次,最终的结论简单而深刻:在测量准确度和召回率方面,没有任何一种不平衡校正技术可以与增加更多的训练数据相媲美。
至此,我们已经到达了本次旅行的终点。下面的参考资料可以帮助你对这个主题有更多的了解。感谢您的阅读!
参考文献
[1] The World’s Most Valuable Resource Is No Longer Oil, But Data,https://www.economist.com/leaders/2017/05/06/the-worlds-most-valuable-resource-is-no-longer-oil-but-data May 2017.
[2] Martinez, A. G., No, Data Is Not the New Oil,https://www.wired.com/story/no-data-is-not-the-new-oil/ February 2019.
[3] Haldan, M., How Much Training Data Do You Need?, https://medium.com/@malay.haldar/how-much-training-data-do-you-need-da8ec091e956
[4] Wikipedia, One in Ten Rule, https://en.wikipedia.org/wiki/One_in_ten_rule
[5] Van Smeden, M. et al., Sample Size For Binary Logistic Prediction Models: Beyond Events Per Variable Criteria, Statistical Methods in Medical Research, 2018.
[6] Pete Warden’s Blog, How Many Images Do You Need to Train A Neural Network?, https://petewarden.com/2017/12/14/how-many-images-do-you-need-to-train-a-neural-network/
[7] Sullivan, L., Power and Sample Size Distribution,http://sphweb.bumc.bu.edu/otlt/MPH-Modules/BS/BS704_Power/BS704_Power_print.html
[8] Wikipedia, Vapnik-Chevronenkis Dimension, https://en.wikipedia.org/wiki/Vapnik%E2%80%93Chervonenkis_dimension
[9] Juba, B. and H. S. Le, Precision-Recall Versus Accuracy and the Role of Large Data Sets, Association for the Advancement of Artificial Intelligence, 2018.
[10] Zhu, X. et al., Do we Need More Training Data?https://arxiv.org/abs/1503.01508, March 2015.
[11] Shchutskaya, V., Latest Trends on Computer Vision Market,https://indatalabs.com/blog/data-science/trends-computer-vision-software-market?cli_action=1555888112.716
[12] De Berker, A., Predicting the Performance of Deep Learning Models,https://medium.com/@archydeberker/predicting-the-performance-of-deep-learning-models-9cb50cf0b62a
[13] Sun, C. et al., Revisiting Unreasonable Effectiveness of Data in Deep Learning Era, https://arxiv.org/abs/1707.02968, Aug. 2017.
[14] Hestness, J., Deep Learning Scaling is Predictable, Empirically,https://arxiv.org/pdf/1712.00409.pdf
[15] Joulin, A., Learning Visual Features from Large Weakly Supervised Data, https://arxiv.org/abs/1511.02251, November 2015.
[16] Lei, S. et al., How Training Data Affect the Accuracy and Robustness of Neural Networks for Image Classification, ICLR Conference, 2019.
[17] Tutorial: Learning Curves for Machine Learning in Python, https://www.dataquest.io/blog/learning-curves-machine-learning/
[18] Ng, R., Learning Curve, https://www.ritchieng.com/machinelearning-learning-curve/
[19] Figueroa, R. L., et al., Predicting Sample Size Required for Classification Performance, BMC medical informatics and decision making, 12(1):8, 2012.
[20] Cho, J. et al., How Much Data Is Needed to Train A Medical Image Deep Learning System to Achieve Necessary High Accuracy?, https://arxiv.org/abs/1511.06348, January 2016.
[21] Lemaitre, G., F. Nogueira, and C. K. Aridas, Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning, https://arxiv.org/abs/1609.06570
原文链接:
https://towardsdatascience.com/how-do-you-know-you-have-enough-training-data-ad9b1fd679ee
学术交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、算法竞赛、图像检测分割、人脸人体、医学影像、综合等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

推荐阅读

最新AI干货,我在看