深度学习引擎的终极形态是什么?
编者按:1月17日,院友袁进辉博士回到微软亚洲研究院做了题为《打造最强深度学习引擎》的报告,分享了深度学习框架方面的技术进展。报告中主要讲解了何为最强的计算引擎?专用硬件为什么快?大规模专用硬件面临着什么问题?软件构架又应该解决哪些问题?以下是报告的核心内容整理,希望能对你有所帮助。本文转自公众号“OneFlow”。
首先,我们一起来开一个脑洞:想象一个最理想的深度学习引擎应该是什么样子的,或者说深度学习引擎的终极形态是什么?看看这会给深度学习框架和AI专用芯片研发带来什么启发。
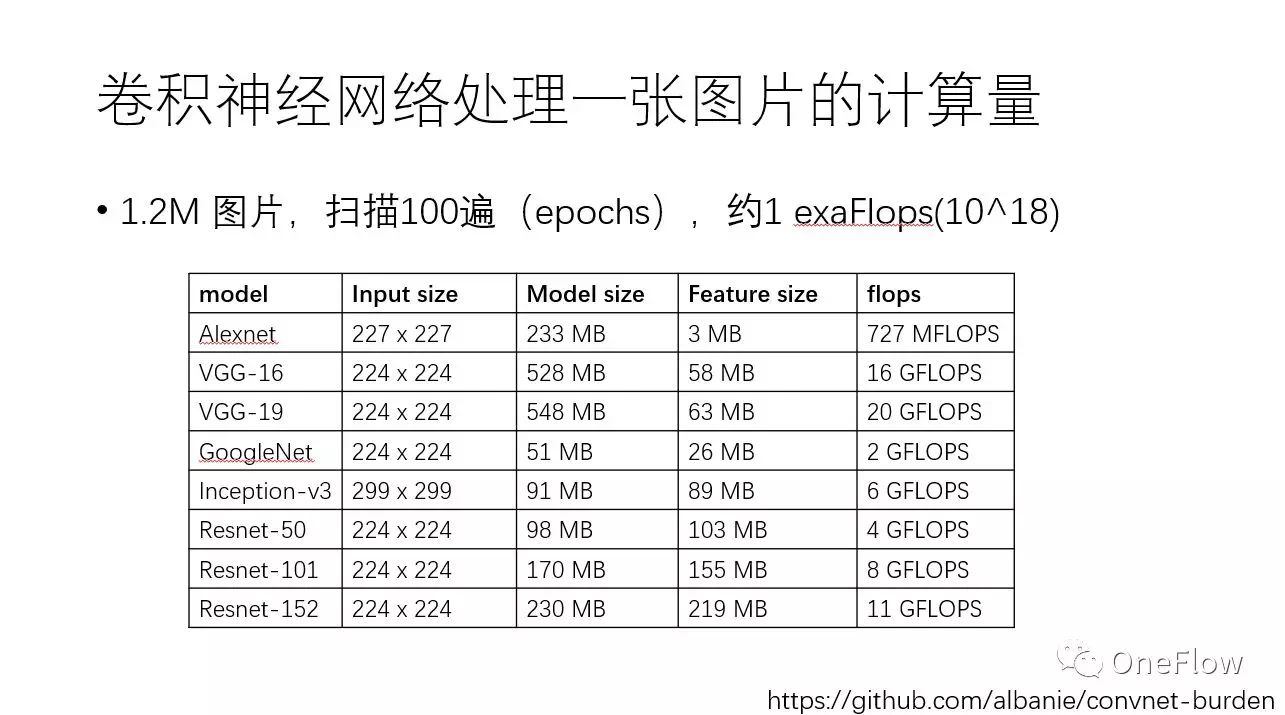
以大家耳熟能详的卷积神经网络CNN 为例,可以感觉一下目前训练深度学习模型需要多少计算力。下方这张表列出了常见CNN模型处理一张图片需要的内存容量和浮点计算次数,譬如VGG-16网络处理一张图片就需要16Gflops。值得注意的是,基于ImageNet数据集训练CNN,数据集一共大约120万张图片,训练算法需要对这个数据集扫描100遍(epoch),这意味着10^18次浮点计算,即1exaFlops。简单演算一下可发现,基于一个主频为2.0GHz的CPU core来训练这样的模型需要好几年的时间。
下图列了几种最常使用的计算设备——CPU、 GPU、 TPU等。众所周知,现在GPU是深度学习领域应用最广的计算设备,TPU 据说比GPU 更加强大,不过目前只有Google 可以用。我们可以讨论下为什么CPU < GPU < TPU,以及存不存在比TPU更加强大的硬件设备。 主频为2GHz的单核CPU 只能串行执行指令,1秒可以执行数千万到数亿次操作。随着摩尔定律终结,人们通过在一个CPU上集成更多的核心来提高计算力,譬如一个CPU上集成20个计算核心(所谓多核,muti-core)可以把CPU计算能力提高几十倍。GPU 比多核更进一步,采用众核(many-core),在一个芯片上集成数千计算核心(core),尽管每个核心的主频要比CPU核心主频低(通常不到1GHz),并行度还是提升了百倍,而且访存带宽要比CPU高10倍以上,因此做稠密计算的吞吐率可以达到CPU的10倍乃至100倍。GPU 被诟病的一点是功耗太高,为解决这个问题,TPU 这样的专用AI芯片横空出世,专用芯片可以在相同的面积里集成更多深度学习需要的运算单元,甚至用专用电路实现某些特定运算使得完成同样计算需要的时间更短 。有比TPU更快的专用芯片吗? 肯定有,极端情况下,任给一个神经网络,都不计成本去专门实现一款芯片,一定比TPU这种用来支持最广泛神经网络类型的芯片要效率高得多。

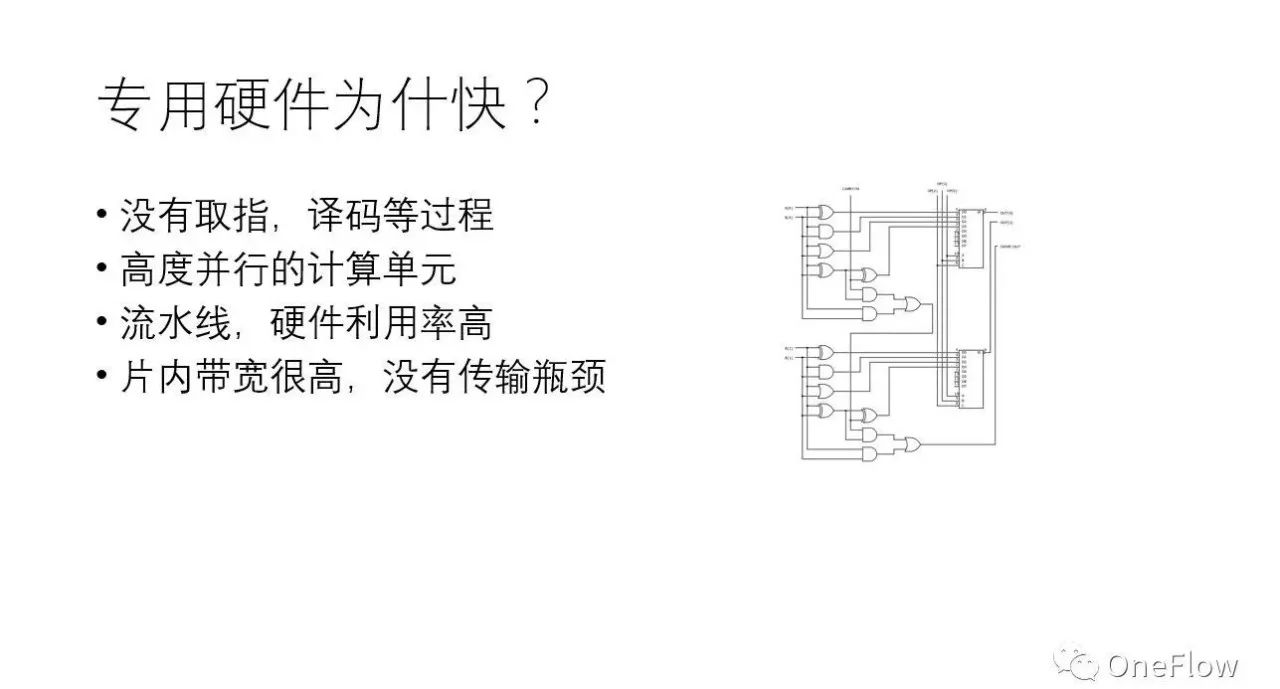
专用硬件比通用硬件(如CPU、GPU)快,有多种原因,主要包括:(1)通用芯片一般经历“取指-译码-执行”(甚至包括“取数据”)的步骤才能完成一次运算,专用硬件大大减小了“取指-译码”等开销,数据到达即执行;(2)专用硬件控制电路复杂度低,可以在相同的面积下集成更多对运算有用的器件,可以在一个时钟周期内完成通用硬件需要数千上万个时钟周期才能完成的操作;(3)专用硬件和通用硬件内都支持流水线并行,硬件利用率高;(4)专用硬件片内带宽高,大部分数据在片内传输。显然,如果不考虑物理现实,不管什么神经网络,不管问题的规模有多大,都实现一套专用硬件是效率最高的做法。问题是,这行得通吗?
如果对任何一个神经网络都实现一套专用硬件,运行效率最高,可是开发效率不高,需求一变更(神经网络拓扑结构,层数,神经元个数),就需要重新设计电路,而硬件研发周期臭名昭著的长。这让人联想起冯诺依曼发明“存储程序”计算机之前的电子计算机(下图即第一台电子计算机ENIAC 的照片),计算机的功能通过硬连线(hard-wired)电路实现,要改变计算机的功能就需要重新组织器件间的连线,这种“编程”方式又慢又难以调试。

刚才设想的无限大的专用硬件显然面临几个现实问题:(1)芯片不可能无限大,必须考虑硬件制造工艺的限制(散热,时钟信号传播范围等);(2)硬连线的电路灵活性太差,改变功能需要重新连线;(3)改变连线后,流水线调度机制可能要做相应调整,才能最大化硬件利用率。因此,我们设想的“不计成本的”,“无限大的”专用硬件面临了严峻挑战,如何克服呢?
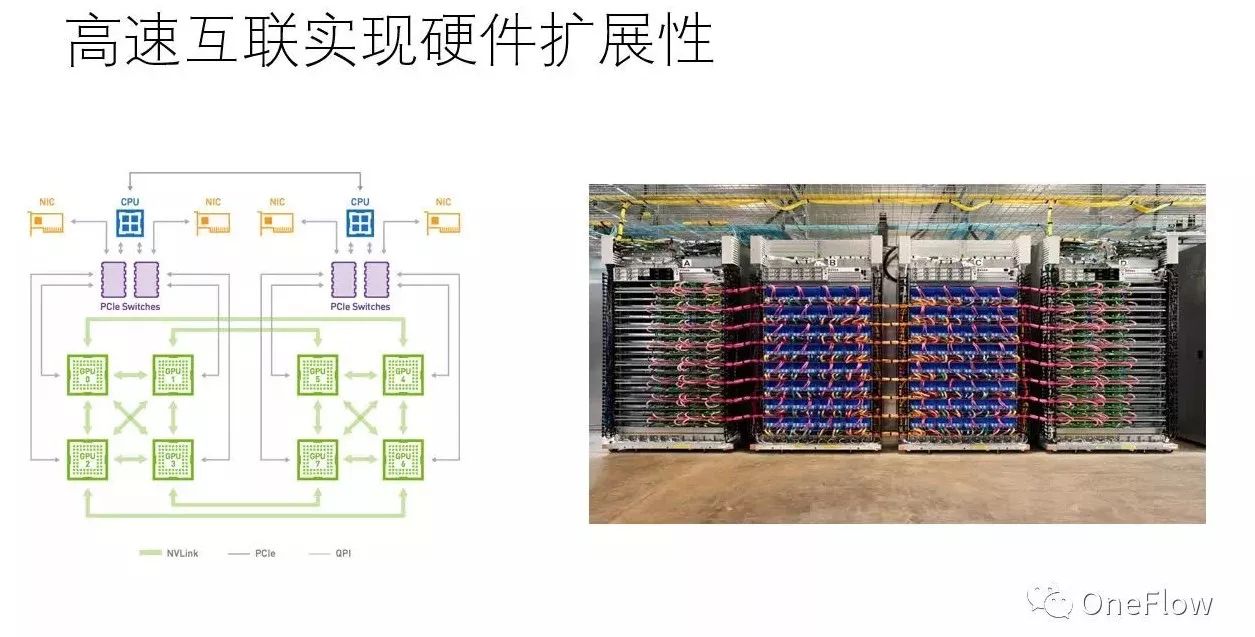
现实中,不管是通用硬件(如GPU)还是专用硬件(如TPU) 都可以通过高速互联技术连接在一起,通过软件协调多个设备来完成大规模计算。使用最先进的互联技术,设备和设备之间传输带宽可以达到100Gbps或者更多,这比设备内部带宽低上一两个数量级,不过幸好,如果软件“调配得当”,在这个带宽条件下也可能使得硬件计算饱和。当然,“调配得当”技术挑战极大,事实上,单个设备速度越快,越难把多个设备“调配得当”。
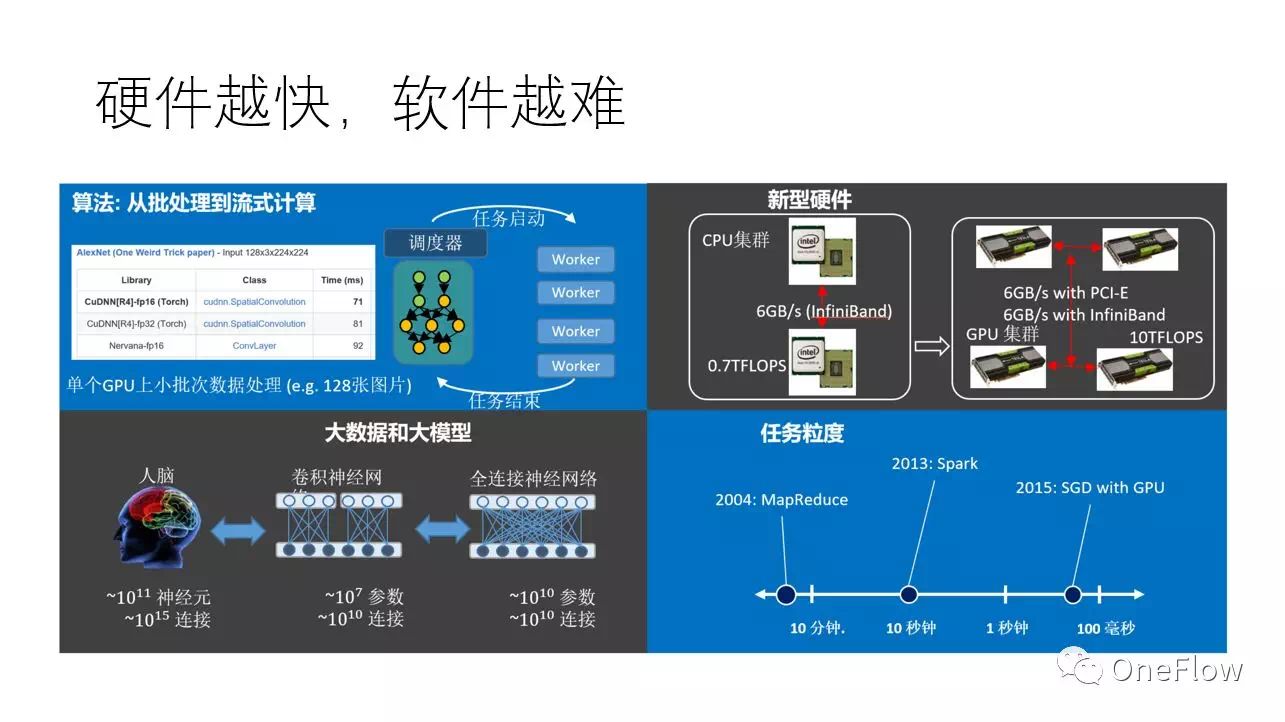
当前深度学习普遍采用随机梯度下降算法(SGD),一般一个GPU处理一小块儿数据只需要100毫秒的时间,那么问题的关键就成了,“调配”算法能否在100毫秒的时间内为GPU处理下一块数据做好准备,如果可以的话,那么GPU就会一直保持在运算状态,如果不可以,那么GPU就要间歇性的停顿,意味着设备利用率降低。理论上是可以的,有个叫运算强度(Arithmetic intensity)的概念,即flops per byte,表示一个字节的数据上发生的运算量,只要这个运算量足够大,意味着传输一个字节可以消耗足够多的计算量,那么即使设备间传输带宽低于设备内部带宽,也有可能使得设备处于满负荷状态。进一步,如果采用比GPU更快的设备,那么处理一块儿数据的时间就比100毫秒更低,譬如10毫秒,在给定的带宽条件下,“调配”算法能用10毫秒的时间为下一次计算做好准备吗?事实上,即使是使用不那么快(相对于TPU 等专用芯片)的GPU,当前主流的深度学习框架在某些场景(譬如模型并行)已经力不从心了。
一个通用的深度学习软件框架要能对任何给定的神经网络和可用资源都能最高效的“调配”硬件,这需要解决三个核心问题:(1)资源分配,包括计算核心,内存,传输带宽三种资源的分配,需要综合考虑局部性和负载均衡的问题;(2)生成正确的数据路由(相当于前文想象的专用硬件之间的连线问题);(3)高效的运行机制,完美协调数据搬运和计算,硬件利用率最高。
事实上,这三个问题都很挑战,本文暂不讨论其解法,假设我们能够解决这些问题的话,会有什么好处呢?
假设我们能解决前述的三个软件上的难题,那就能“鱼与熊掌兼得”:软件发挥灵活性,硬件发挥高效率,任给一个深度学习任务,用户不需要重新连线,就能享受那种“无限大专用硬件”的性能,何其美好。更令人激动的是,当这种软件得以实现时,专用硬件可以比现在所有AI芯片都更简单更高效。读者可以先想象一下怎么实现这种美好的前景。

让我们重申一下几个观点:(1)软件真的非常关键;(2)我们对宏观层次(设备和设备之间)的优化更感兴趣;(3)深度学习框架存在一个理想的实现,正如柏拉图心中那个最圆的圆,当然现有的深度学习框架还相距甚远;(4)各行各业的公司,只要有数据驱动的业务,最终都需要一个自己的“大脑”,这种“大脑”不应该只被少数巨头公司独享。

你还有什么天马行空的想法吗?
欢迎在评论区留言哦!

袁进辉(老师木),2008年7月自清华大学计算机系获得工学博士学位,获得清华大学优秀博士学位论文奖,在计算机视觉以及多媒体领域顶级会议上发表多篇论文,连续多年获得美国国家技术标准局组织的视频检索评测比赛的第一名。2010年负责研发斯诺克”鹰眼“系统,该产品打败来自英国的竞品开始服务于各项国际大赛。2013年加入微软亚洲研究院从事大规模机器学习平台的研发工作,后发明了当时世界上最快的主题模型训练算法和系统LightDA,该技术成功应用于微软在线广告系统。2017年创立北京一流科技有限公司,致力于打造业界最好的深度学习平台。
你也许还想看:
● 对话Yoshua Bengio | 深度学习的昨天、今天和明天

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。





