SageMaker Studio Lab 将是免费计算资源领域一个强有力的竞争对手。
一周前,亚马逊启动了 SageMaker Studio 的免费简化版 SageMaker Studio Lab,提供了一个时限为12小时的 CPU 实例和一个时限为 4 小时的 GPU 实例。SageMaker Studio Lab 成为继 Google Colab、Kaggle 和 Paperspace 之后的又一个免费深度学习计算空间。
Studio Lab 为用户提供了所有入门 AI 所需的基础能力,包括 JupyterLab IDE、CPU 和 GPU 模型训练算力以及 15 GB 的永久存储。
那么,SageMaker Studio Lab 如何与竞争对手抗衡?它是否值得使用?
现在一位名为 Benjamin Warner 的博主已经申请使用了 SageMaker Studio Lab,并为大家撰写了一篇博客「开箱测评」。以下是博客原文。
本文我使用图像和 NLP 分类任务,比较了在 SageMaker Studio Lab 和 Colab、Colab Pro 以及 Kaggle 上训练神经网络的效果。
与 Colab 和 Kaggle 一样,Studio Lab 提供 CPU 和 GPU 实例:运行时间为 12 小时的 T3.xlarge CPU 实例和运行时间为 4 小时的 G4dn.xlarge GPU 实例。比较结果如下表所示:
![]()
SageMaker 只有持久存储,但与 Google Drive 不同的是,它的速度足以训练;
Colab 暂存盘因实例而异;
Colab 的持久存储是 Google Drive 免费分配的;
Colab Pro 可以分配 Tesla T4 或 Tesla K80;
免费版 Colab 也可以分配 Tesla T4 或 Tesla P100;
Kaggle 的持久存储为每个笔记本 20GB;
Kaggle 有一个每周 GPU 运行时间上限,它根据总使用量而变化,每周大约 40 小时。
启动 SageMaker Studio Lab 后将获得稍有修改的 JupyterLab 实例,其中安装了一些扩展,例如 Git。
![]()
在我的测试中,SageMaker Studio Lab 的 JupyterLab 的行为与在自己系统上正常安装 JupyterLab 完全相同。甚至之前对 JupyterLab 做的修改和已安装的 python 包都还在。
例如,我能够从 Jupyterlab Awesome List 中安装 python 语言服务器和 markdown 拼写检查器。但这也带来了一个问题,即亚马逊是否会更新像 PyTorch 这样的预安装包,或者维护更新的环境是否完全依赖于用户。
亚马逊后续可能会销毁我的实例,或者将来会升级底层映像,删除自定义安装的包和扩展。但就目前而言,相比于 Colab 和 Kaggle,Studio Lab 是三者中可定制程度最高的服务。
我选择了两个小数据集来对 SageMaker 和 Colab 进行基准测试:Imagenette 以及 IMDB。Imagenette 数据集用于计算机视觉,Hugging Face 的 IMDB 用于 NLP。为了减少训练时间,在训练 IMDB 时,我随机抽取了 20% 的测试集。
对于计算机视觉,模型选择 XResNet 和 XSE-ResNet,即 ResNet 的 fast.ai 版本;对于 NLP,我选择 Hugging Face 实现的 RoBERTa。
Imagenette 地址:https://github.com/fastai/imagenette#imagenette
IMDB 地址:https://huggingface.co/datasets/imdb
fast.ai 地址:https://docs.fast.ai/
训练 Imagenette 采用 fast.ai ,其在进行数据扩充时,可以对图像进行随机调整 crop 和随机水平翻转。
训练 IMDB 采用 blurr 库,该库将 fast.ai 和 Hugging Face Transformers 集成在一起。除了向 fast.ai 添加 Transformers 训练和推理支持外,blurr 还集成了每 batch token 化和 fast.ai 文本数据加载器,后者根据序列长度对数据集进行随机排序,以最大限度地减少训练时的填充(padding)。
XSE-ResNet50 和 RoBERTa 采用单精度和混合精度训练的方式 。XSE-ResNet50 训练图像大小为 224 像素,混合精度 batch 大小为 64,单精度 batch 大小为为 32。RoBERTa 混合精度 batch 大小为 16,单精度 batch 大小为 8。
为了探索 CPU 使用极限,我还训练了一个 XResNet18 模型,图像大小为 128 像素,batch 大小为 64。
blurr 地址:https://ohmeow.github.io/blurr/
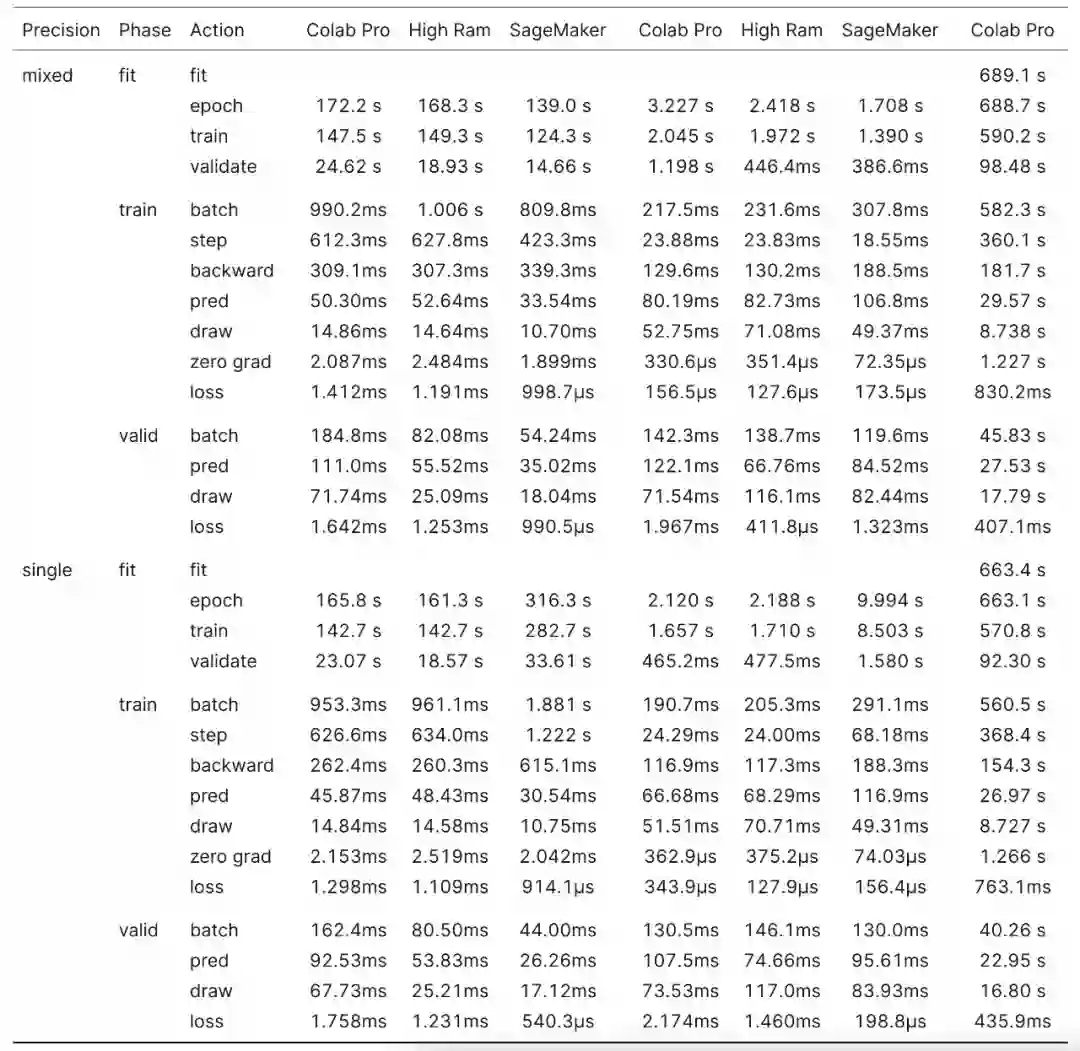
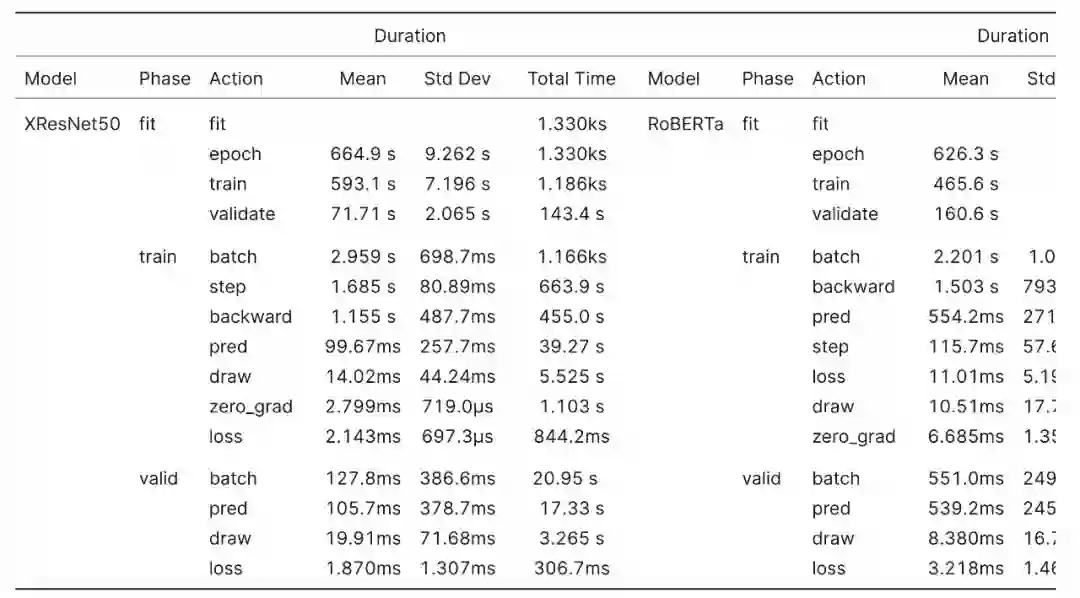
当进行混合精度训练时,SageMaker Studio Lab 的 Tesla T4 优于 Google Colab 的 Tesla P100,但在训练全单精度模型时表现稍差。
在相似的设置下,Colab Pro High RAM 和 SageMaker 比较,XSE-ResNet50 在 SageMaker 上的总体训练速度提高了 17.4%。仅查看训练循环(training loop)时,SageMaker 比 Colab Pro 快 19.6%。SageMaker 在所有操作中都更快,但有一个明显的例外:在向后传递中,SageMaker 比 Colab Pro 慢 10.4%。
当以单精度训练 XSE-ResNet50 时,结果相反,SageMaker 的执行速度比 Colab Pro High RAM 慢 95.9%, 训练循环比 Colab Pro 慢 93.8%。
![]()
XSE-ResNet50 Imagenette 简单分析器结果
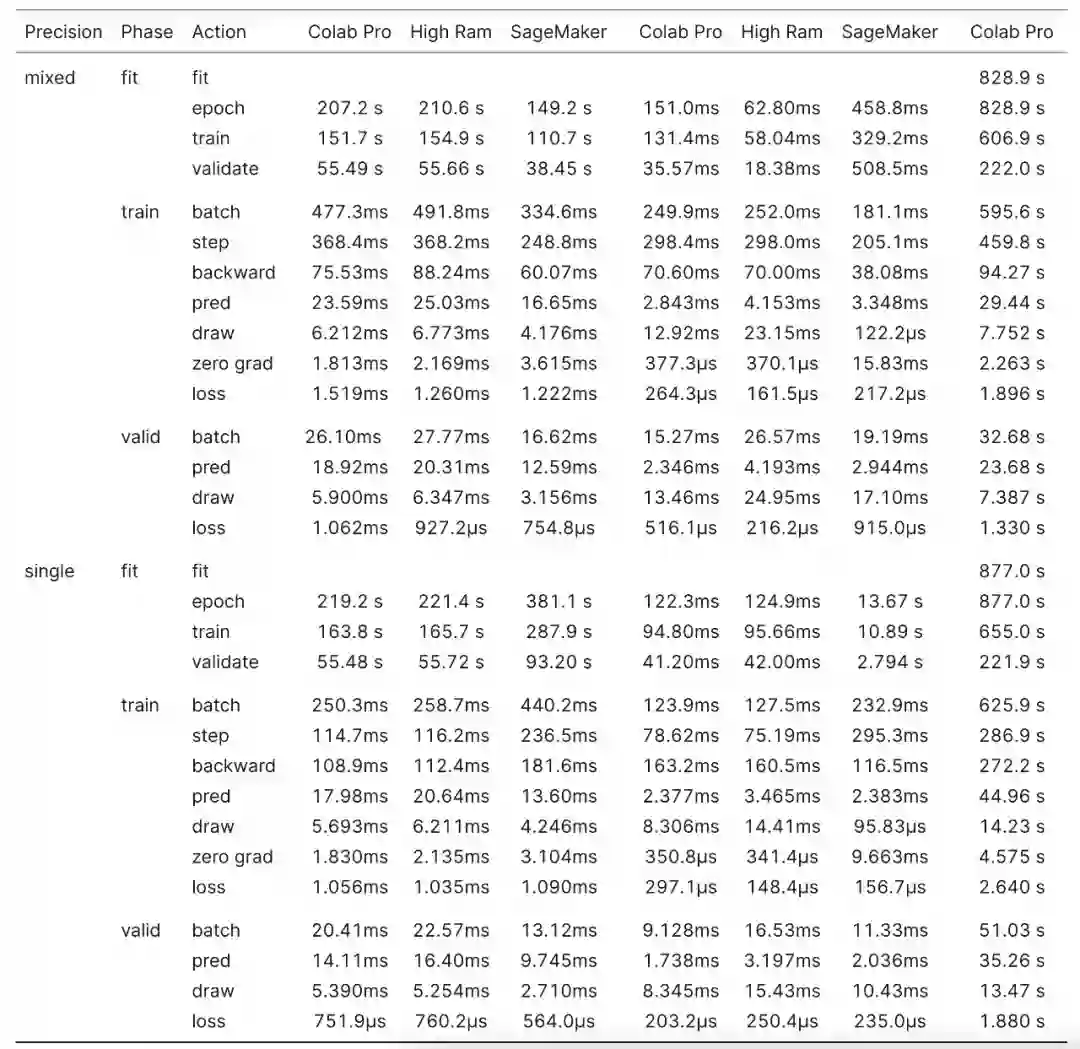
混合精度训练 RoBERTa, SageMaker 进一步领先 Colab Pro,执行速度提高了 29.1%。SageMaker 在训练循环期间比 Colab Pro 快 32.1%,并且在所有操作中 SageMaker 都更快,除了在计算损失时,SageMaker 比 Colab Pro 慢 66.7%。
在单精度下,SageMaker 训练的结果再次翻转,总体上 SageMaker 比 Colab Pro 慢 72.2%。训练循环比 Colab Pro 慢 67.9%。当以单精度训练 XSE-ResNet50 时,由于向后传递和优化器步骤,SageMaker 比 Colab Pro 慢了 83.0%,而 SageMaker 执行所有其他操作的速度快了 27.7%。
奇怪的是,Colab Pro High RAM 实例的训练速度比普通 Colab Pro 实例慢,尽管前者有更多的 CPU 核和 CPU RAM 以及相同的 GPU。然而,它们之间的差异并不大。
![]()
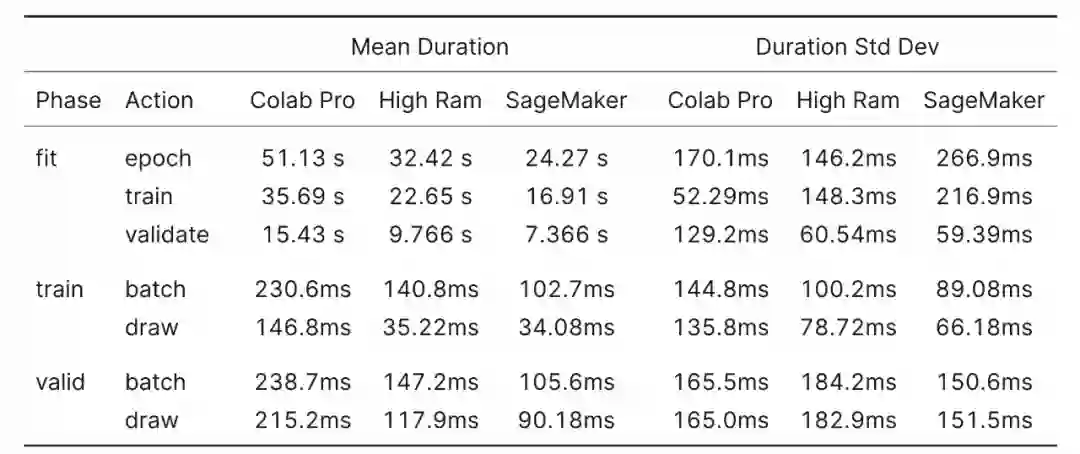
对于 XResNet18 基准测试,了解绘制动作测量内容很关键。XResNet18 基准测试是从数据加载器绘制 batch 之前到开始 batch 操作之间的时间。数据加载器的 prefetch_factor 设置为默认值 2,这意味着研究者尝试在训练循环调用它们之前提前加载两个 batch。其中包括前向和后向传递、损失和优化器 step 和零梯度操作。
这里的结果符合预期,更多的 CPU 核意味着更少的绘制时间,并且在相同的核数下,较新的 CPU 的性能优于较旧的 CPU。
![]()
由于免费 Colab 实例的 Tesla K80 的 RAM 比其他 GPU 少四分之一,因此我将混合精度 batch 大小也减少了四分之一。此外,我没有运行任何单精度测试。
我运行了两个 epoch 的 Imagenette 基准测试,并将 IMDB 数据集从 20% 的样本减少到 10% 的样本,并将训练长度减少到一个 epoch。
Colab K80 在半数 Imagenette epoch 上进行训练花费的时间大约是 Colab Pro 实例的两倍。与 Colab P100 相比,在 Colab K80 上进行等效的 IMDB 训练时间要长 3 倍。如果可能的话,应避免使用 K80 对除小型模型以外的任何其他模型进行训练。
![]()
XResNet & RoBERTa Colab K80 基准结果
总的来说,我认为 SageMaker Studio Lab 是免费计算资源领域一个强有力的竞争对手。特别是对于一直在 K80 上使用免费 Colab 和训练模型的用户来说,SageMaker Studio Lab 将给你全面的升级体验。
SageMaker Studio Lab 可以作为机器学习工作流程的有用补充和 Kaggle 或 Colab Pro 的增强版。混合精度的训练速度比 Kaggle 或 Colab Pro 快了 17.4% 到 32.1%,这意味着迭代时的等待时间更少。
此外,更快的训练速度和持久存储让 SageMaker Studio Lab 对于深度学习初学者也非常友好,因为这意味着环境只需要设置一次,让学生能够专注于学习而不是持续的包管理。
原文链接:https://benjaminwarner.dev/2021/12/08/testing-amazon-sagemaker-studio-lab
基于Python,利用 NVIDIA TAO Toolkit 和 Deepstream 快速搭建车辆信息识别系统
NVIDIA TAO Toolkit是一个AI工具包,它提供了AI/DL框架的现成接口,能够更快地构建模型,而不需要编码。
DeepStream是一个用于构建人工智能应用的流媒体分析工具包。它采用流式数据作为输入,并使用人工智能和计算机视觉理解环境,将像素转换为数据。
DeepStream SDK可用于构建视觉应用解决方案,用于智能城市中的交通和行人理解、医院中的健康和安全监控、零售中的自助检验和分析、制造厂中的组件缺陷检测等
12月14日19:30-21:00,本次分享摘要如下:
介绍 TAO Toolkit 的最新特性;
介绍 NVIDIA Deepstream 的最新特性;
利用 TAO Toolkit 丰富的预训练模型库,快速训练模型;
直接利用 TAO Toolkit 的预训练模型和 Deepstream 部署应用;
完成对车辆车牌的检测和识别,并对行人以及车辆的品牌,颜色,种类进行检测。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com