节点嵌入训练加快300倍!解读开源高性能图嵌入系统GraphVite

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)

目前,GraphVite 已为 3 种应用提供了完整的训练和评价框架,包括节点嵌入、知识图谱嵌入以及图和高维数据可视化。此外,它还包含了 9 种流行的模型以及这些模型在一系列标准数据集上的基准测试结果。
GitHub 项目入口:https://github.com/DeepGraphLearning/graphvite
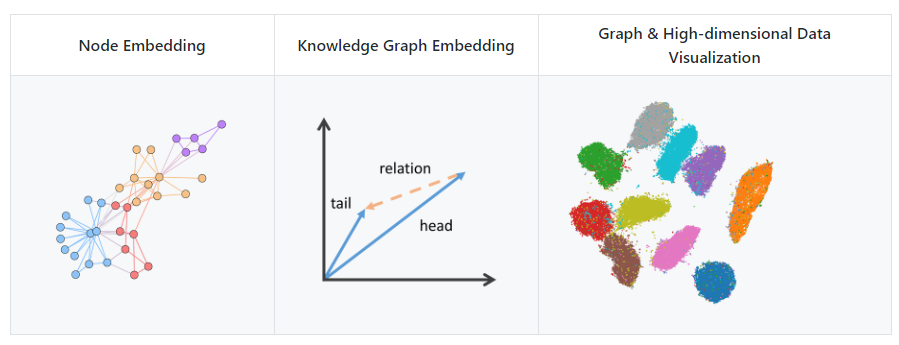
GraphVite 现支持的三种任务
为了展示 GaphVite 的速度,MilaGraph 提供了在三种应用上最好的开源实现与 GraphVite 的训练速度报告,报告基于 24 个 CPU 线程以及 4 个 Tesla V100GPU 的硬件系统。在 Youtube 数据集上,节点嵌入任务的训练速度如下:
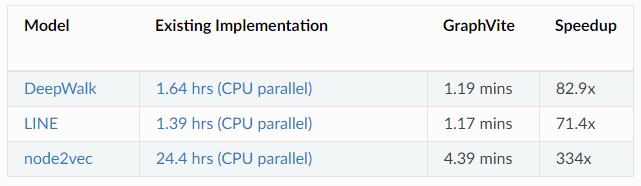
Youtube 数据集上节点嵌入任务训练时间
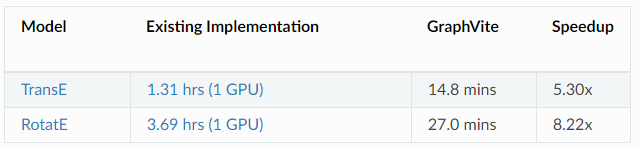
在 FB15k 数据库上实现的知识图谱任务报告如下:
在 MNIST 数据集上实现的高维数据可视化任务报告如下:

可以看出在以上三个任务中,相较于目前最好的开源实现,GraphVite 最多可以提升 300 多倍的速度。 并且,在提高了速度的同时,GraphVite 没有任何性能上的牺牲,这点可以从该项目提供的基准测试报告中发现。在使用与上述速度报告相同硬件的情况下,GraphVite 的说明文档中还提供了使用 GraphVite 实现的所有模型的基准测试结果。在节点嵌入任务上,作者在 Youtube、Flicke 和 Friendster-small 三个数据集上提供了每个模型的 micro-F1 和 macro-F1 指标。
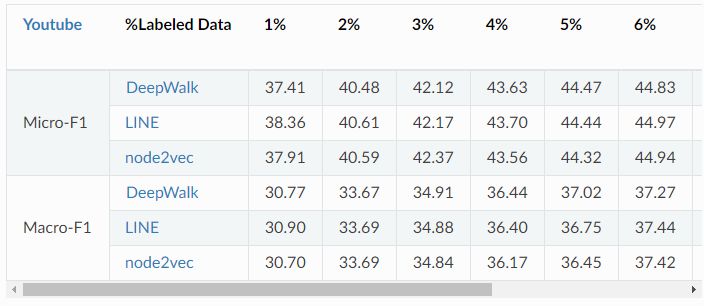
Youtube 数据集上三种不同模型的结果报告
在知识图谱嵌入任务上,作者对 TransE、DistMult、ComplE、SimplE 和 RotatE 四种方法进行了测试。
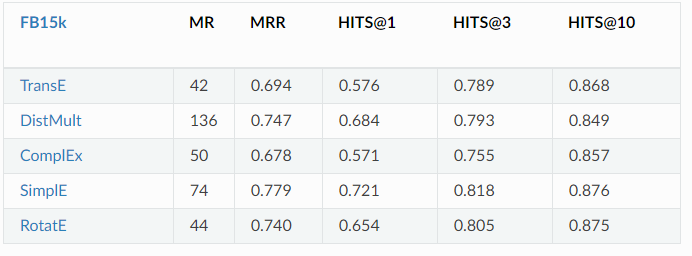
Youtube 数据集上五种不同模型的结果报告
作者在两个流行的数据集上对图及高维数据可视化任务进行了测试。LargeVis 所需的训练时间和资源如下表所示。请注意,超过 95%的 GPU 内存成本来自 KNN Graph 的构建,并且可以在必要时与速度进行权衡。
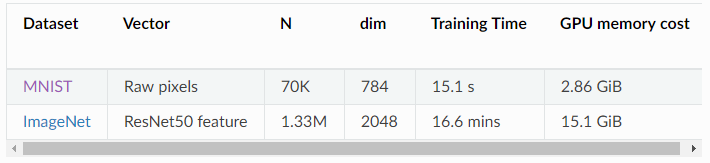
在 MNIST 和 ImageNet 数据集上 LargeVis 的测试结果
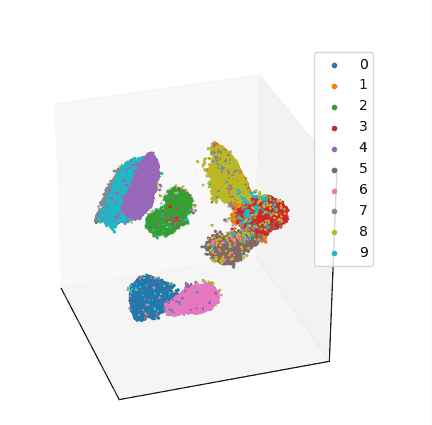
其中,MNIST 数据集上 3D 可视化结果如下:
与类似的工作 Pytorch-BigGraph 相比,GraphVite 速度更快,测试结果如下:
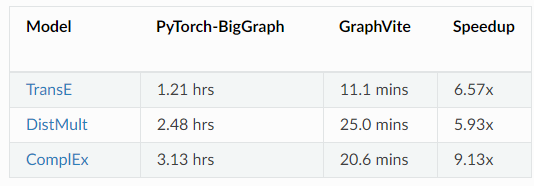
同时,GraphVite 还比前者多了节点嵌入以及可视化两个功能,为研究和开发提供了更多的便利。
GraphVite 为什么可以这么快?这是因为 GraphVite 根据 CPU 和 GPU 各自的优势,解决了混合节点嵌入系统的三大挑战。
混合节点嵌入系统的难点主要包含:1)基于 mini-batch 的 SGD 方法无法直接用关于大型网络上的节点嵌入,2)由于 GPU 与 CPU 总线带宽的差异,在 CPU 与 GPU 之间的数据转送会成为系统瓶颈,3) 多 CPU 与 GPU 设备间的同步成本巨大。
GraphVite 使用了并行在线增广方法在 CPU 上有效地扩充网络规模。同时使用了并行负采样方法对多 GPU 的嵌入训练进行协调。GraphVite 还使用了一种协作策略来降低 CPU 和 GPU 之间的同步成本。
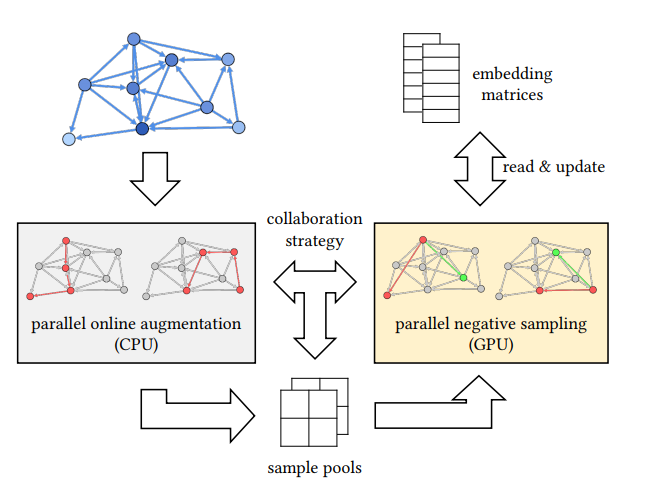
GraphVite 系统结构图,灰色及黄色部分分别表示并行数据增广过程与嵌入训练过程。
对于节点嵌入方法,其第一阶段需要使用随机遍历来扩充原始网络。由于增广网络通常比原始网络要大一到两个数量级,因此,如果原始网络已经非常大,则其网络结构将很难被加载到主存储器中。GraphVite 采用了并行在线增广,可以在不显示网络增强的情况下生成增广的边样本。
作者首先绘制一个出发节点(depature node),其选择概率与每个节点的度成正比。然后从出发节点开始执行随机游走,并在特定的增广距离 s 内挑选节点对产生边样本。由于随机游走中生成边样本具有相关性,因此训练效果可能会变差。作者受到强化学习中广泛使用的经验回放方法的启发,收集边样本到样本池,并在对它混洗(shuffle)后再转发到 GPU 进行嵌入训练。当每个线程预先分配有独立的样池时,上述方法可以并行化处理。算法 2 给出了并行在线增广的详细过程:

为了更好的训练效果,对样本池进行混洗非常重要,但同时它也会减慢网络增广的速度。原因是普通的洗牌方法包含大量随机内存访问,并且不能由 CPU 缓存加速。如果服务器有多个 CPU 插槽,速度损失将更加严重。为了缓解这个问题,作者提出了一种伪混洗技术,它以更加缓存友好的方式对相关样本进行洗牌,并显着提高系统的速度。
在嵌入训练阶段,作者将训练任务分为多个子任务并将它们分配给多个 GPU 设备。子任务必须设计成具有很少的共享数据的形式以最小化 GPU 之间的同步成本。为了了解如何将模型参数分配给多个 GPU 而不重叠,作者首先介绍了ε- 梯度可交换的概念:

其中,作者将 0- 梯度可交换称为梯度可交换。由于节点嵌入训练过程的稀疏性质,在网络中会存在很多形成梯度可交换对的集合。例如,对于两个边缘样本集例如,对于两个边缘样本集 X1,X2⊆E,如果它们不共享任何源节点或目标节点,则 X1 和 X2 是梯度可交换的。即使 X1 和 X2 共享一些节点,如果学习率α和迭代次数有界,它们仍然可以是ε- 梯度可交换的。
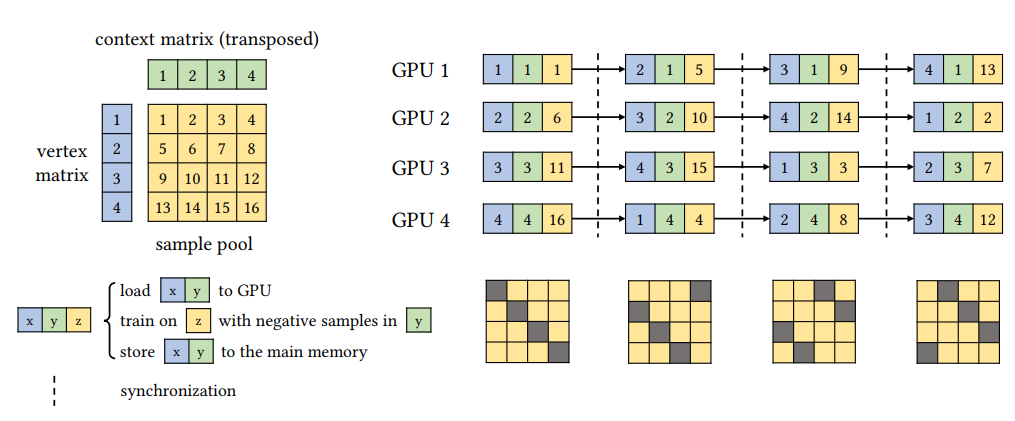
基于节点嵌入中观察到的梯度交换性,作者提出了一种用于嵌入训练阶段的并行负采样算法。对于 n 个 GPU,我们将顶点和上下文行分别划分为 n 个分区(上图的左上角)。这导致样本池的 n×n 分区网格,其中每个边缘属于其中一个块。这样,任何不共享行或列的块都是可梯度交换的。只要限制每个块上的迭代次数,同一行或列中的块都是ε- 梯度可交换的。
作者将集(episode)定义为并行负抽样中使用的块级步骤。在每一集中,我们分别向 n 个 GPU 发送 n 个正交块及其对应的顶点和上下文分区。然后,每个 GPU 使用 ASGD 更新自己的嵌入分区。因为这些块是相互梯度可交换的并且不共享参数矩阵中的任何行,所以多个 GPU 可以在没有任何同步的情况下同时执行 ASGD。在每集结束时,我们从所有 GPU 收集更新的参数并分配另外 n 个正交块。这里ε- 梯度可交换由 n 个正交块中的总样本数控制,我们将其定义为集的大小。较小的集有利于ε- 梯度可交换嵌入式训练。但是同时也会导致更频繁的同步。因此作者调整了集的大小,以便在速度和ε- 梯度可交换之间有一个很好的权衡。上图给出了具有 4 个分区的并行负采样的示例。
虽然作者使用等于 n 的分区数量来说明了负采样的有效性,但是并行负采样可以很容易地推广到任何数量大于 n 的分区的情况,只需在每集中处理 n 个子组中的正交块。算法 3 给出了用于多个 GPU 的混合系统的并行负采样算法的详细步骤:
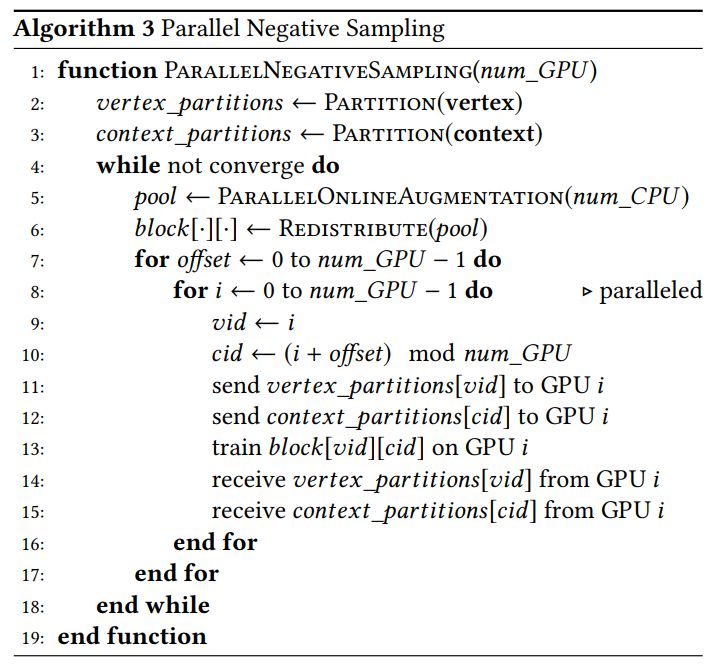
我们的并行负采样使不同的 GPU 能够同时训练节点嵌入,只需要在集之间进行同步。但是,应该注意到,样本池也在 CPU 和 GPU 之间共享。如果它们在样本池上同步,则只有同一阶段的设备可以同时访问样本池,这意味着硬件在一半时间内处于空闲状态。为了提高效率,作者提出了一种协作策略来降低同步成本。
作者主存储器中分配两个样本池,让 CPU 和 GPU 始终在不同的样本池上工作。CPU 首先填充样本池并将其传递给 GPU。之后,并行在线增广和并行负采样分别在 CPU 和 GPU 上执行。当 CPU 填满新的样本池时,将交换这两个池。通过协作策略,CPU 和 GPU 之间的同步成本降低,混合系统的速度几乎翻倍。
作者使用了 Youtube、Reiendster-small、Hyperlink-PLD 和 Friendster 四个数据库对 GraphVite 的性能进行了测试。部分实验结果已在第一章中展示,详细的实验结果在 论文原文 以及 GraphVite官方网站(https://graphvite.io/)的 Docs 中都有详细的展示。
GraphVite 可以在 CUDA>=9.2 的 Linux 系统上运行,兼容 Python2.7 和 Python3.5/3.6/3.7 版本。GraphVite 对待新手十分友好,它提供了关于节点嵌入任务的快速入门示例供用户学习。用户可以选择通过 Conda 源进行安装或使用源码编译,使用 Conda 安装仅需在命令行输入命令:
conda install -c milagraph graphvite
如果仅需要嵌入训练而不要测试部分,还可以选择更加轻量级的最小化 GraphVite 系统:
conda install -c milagraph graphvite-mini
或者用户也可以选择使用源码编译:
git clone https://github.com/DeepGraphLearning/graphvite
cd graphvite
conda install -y --file conda/requirements.txt
mkdir build
cd build && cmake .. && make && cd -
cd python && python setup.py install && cd -
安装完成 GraphVite 后,直接执行即可查看示例,在终端输入:
conda install -c milagraph graphvite-mini
示例需要运行约一分多钟的时间,然后会输出结果:
Batch id: 6000
loss = 0.371641
macro-F1@20%: 0.236794
micro-F1@20%: 0.388110
相关链接:
论文原文:https://arxiv.org/pdf/1903.00757.pdf
官方网站:https://graphvite.io/
Github 主页:
https://github.com/DeepGraphLearning/graphvite

你也「在看」吗?👇




