PyG实战图分类
“他山之石,可以攻玉”,站在巨人的肩膀才能看得更高,走得更远。在科研的道路上,更需借助东风才能更快前行。为此,我们特别搜集整理了一些实用的代码链接,数据集,软件,编程技巧等,开辟“他山之石”专栏,助你乘风破浪,一路奋勇向前,敬请关注。
地址:https://zhuanlan.zhihu.com/p/435945714
import torchfrom torch_geometric.datasets import TUDatasetdataset = TUDataset('data/TUDataset', name = 'MUTAG')print()print(f'Dataset: {dataset}:')print('====================')print(f'Number of graphs: {len(dataset)}')print(f'Number of features: {dataset.num_features}')print(f'Number of classes: {dataset.num_classes}')data = dataset[0] # Get the first graph object.print()print(data)print('=============================================================')# Gather some statistics about the first graph.print(f'Number of nodes: {data.num_nodes}')print(f'Number of edges: {data.num_edges}')print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')print(f'Has isolated nodes: {data.has_isolated_nodes()}')print(f'Has self-loops: {data.has_self_loops()}')print(f'Is undirected: {data.is_undirected()}')# 输出结果Dataset: MUTAG(188):====================Number of graphs: 188Number of features: 7Number of classes: 2Data(edge_index=[2, 38], x=[17, 7], edge_attr=[38, 4], y=[1])=============================================================Number of nodes: 17Number of edges: 38Average node degree: 2.24Has isolated nodes: FalseHas self-loops: FalseIs undirected: True
torch.manual_seed(12345)dataset = dataset.shuffle()train_dataset = dataset[:150]test_dataset = dataset[150:]print(f'Number of training graphs: {len(train_dataset)}')print(f'Number of test graphs: {len(test_dataset)}')# 输出结果Number of training graphs: 150Number of test graphs: 38
01
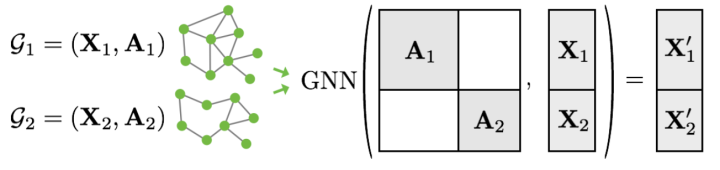
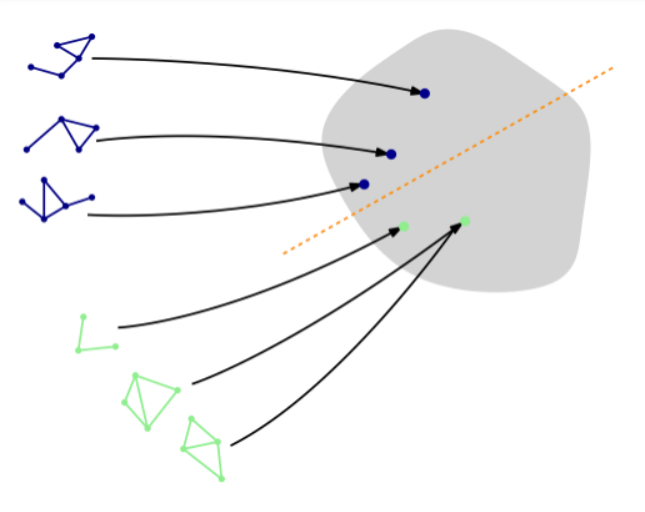
# from torch_geometric.loader import DataLoader# train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)# for step, data in enumerate(train_loader):# print(f'Step {step + 1}:')# print('=======')# print(f'Number of graphs in the current batch: {data.num_graphs}')# print(data)# print()from torch_geometric.loader import DataLoadertrain_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)for step, data in enumerate(train_loader):print(f'Step {step + 1}:')print('=======')print(f'Number of graphs in the current batch: {data.num_graphs}')print(data)print()# 输出结果Step 1:=======Number of graphs in the current batch: 64DataBatch(edge_index=[2, 2624], x=[1185, 7], edge_attr=[2624, 4], y=[64], batch=[1185], ptr=[65])Step 2:=======Number of graphs in the current batch: 64DataBatch(edge_index=[2, 2538], x=[1146, 7], edge_attr=[2538, 4], y=[64], batch=[1146], ptr=[65])Step 3:=======Number of graphs in the current batch: 22DataBatch(edge_index=[2, 832], x=[383, 7], edge_attr=[832, 4], y=[22], batch=[383], ptr=[23])
02
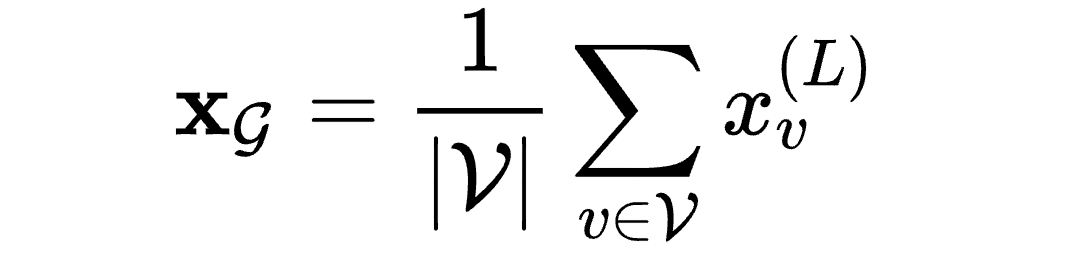
from torch.nn import Linearimport torch.nn.functional as Ffrom torch_geometric.nn import GCNConvfrom torch_geometric.nn import global_mean_poolclass GCN(torch.nn.Module):def __init__(self, hidden_channels):super(GCN, self).__init__()torch.manual_seed(12345)self.conv1 = GCNConv(dataset.num_node_features, hidden_channels)self.conv2 = GCNConv(hidden_channels, hidden_channels)self.conv3 = GCNConv(hidden_channels, hidden_channels)self.lin = Linear(hidden_channels, dataset.num_classes)def forward(self, x, edge_index, batch):# 1. 获得节点嵌入x = self.conv1(x, edge_index)x = x.relu()x = self.conv2(x, edge_index)x = x.relu()x = self.conv3(x, edge_index)# 2. Readout layerx = global_mean_pool(x, batch) # [batch_size, hidden_channels]# 3. 分类器x = F.dropout(x, p=0.5, training=self.training)x = self.lin(x)return xmodel = GCN(hidden_channels=64)print(model)# 输出结果GCN((conv1): GCNConv(7, 64)(conv2): GCNConv(64, 64)(conv3): GCNConv(64, 64)(lin): Linear(in_features=64, out_features=2, bias=True))
model = GCN(hidden_channels=64)optimizer = torch.optim.Adam(model.parameters(), lr=0.01)criterion = torch.nn.CrossEntropyLoss()def train():model.train()for data in train_loader:optimizer.zero_grad()out = model(data.x, data.edge_index, data.batch)loss = criterion(out, data.y)loss.backward()optimizer.step()def test(loader):model.eval()correct = 0for data in loader: # 批遍历测试集数据集。out = model(data.x, data.edge_index, data.batch) # 一次前向传播pred = out.argmax(dim=1) # 使用概率最高的类别correct += int((pred == data.y).sum()) # 检查真实标签return correct / len(loader.dataset)for epoch in range(1, 121):train()train_acc = test(train_loader)test_acc = test(test_loader)print(f'Epoch: {epoch:03d}, Train Acc: {train_acc:.4f}, Test Acc: {test_acc:.4f}')
Epoch: 108, Train Acc: 0.7933, Test Acc: 0.7368Epoch: 109, Train Acc: 0.8200, Test Acc: 0.7632Epoch: 110, Train Acc: 0.7933, Test Acc: 0.7632Epoch: 111, Train Acc: 0.7867, Test Acc: 0.7368Epoch: 112, Train Acc: 0.7800, Test Acc: 0.7368Epoch: 113, Train Acc: 0.7867, Test Acc: 0.7368Epoch: 114, Train Acc: 0.8000, Test Acc: 0.7368Epoch: 115, Train Acc: 0.7933, Test Acc: 0.7368Epoch: 116, Train Acc: 0.7800, Test Acc: 0.7368Epoch: 117, Train Acc: 0.8000, Test Acc: 0.7632Epoch: 118, Train Acc: 0.8000, Test Acc: 0.7368Epoch: 119, Train Acc: 0.8067, Test Acc: 0.7632Epoch: 120, Train Acc: 0.8200, Test Acc: 0.7632
03
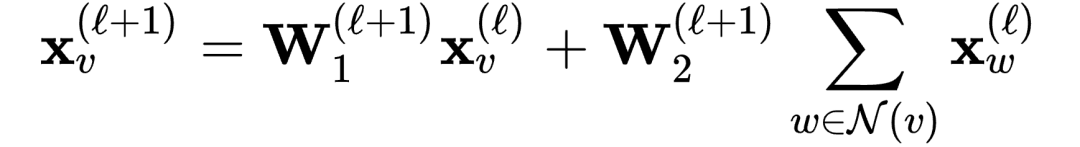
from torch_geometric.nn import GraphConvclass GNN(torch.nn.Module):def __init__(self, hidden_channels):self).__init__()torch.manual_seed(12345)= GraphConv(dataset.num_node_features, hidden_channels)= GraphConv(hidden_channels, hidden_channels)= GraphConv(hidden_channels, hidden_channels)= Linear(hidden_channels, dataset.num_classes)def forward(self, x, edge_index, batch):x = self.conv1(x, edge_index)x = x.relu()x = self.conv2(x, edge_index)x = x.relu()x = self.conv3(x, edge_index)x = global_mean_pool(x, batch)x = F.dropout(x, p=0.5, training=self.training)x = self.lin(x)return xmodel = GNN(hidden_channels=64)print(model)GNN(: GraphConv(7, 64): GraphConv(64, 64): GraphConv(64, 64): Linear(in_features=64, out_features=2, bias=True))model = GNN(hidden_channels=64)print(model)optimizer = torch.optim.Adam(model.parameters(), lr=0.01)for epoch in range(1, 201):train()train_acc = test(train_loader)test_acc = test(test_loader): {epoch:03d}, Train Acc: {train_acc:.4f}, Test Acc: {test_acc:.4f}')# 输出结果GNN(: GraphConv(7, 64): GraphConv(64, 64): GraphConv(64, 64): Linear(in_features=64, out_features=2, bias=True))...省略结果输出Epoch: 191, Train Acc: 0.9467, Test Acc: 0.8421Epoch: 192, Train Acc: 0.9467, Test Acc: 0.8421Epoch: 193, Train Acc: 0.9467, Test Acc: 0.8158Epoch: 194, Train Acc: 0.9400, Test Acc: 0.8421Epoch: 195, Train Acc: 0.9467, Test Acc: 0.8421Epoch: 196, Train Acc: 0.9467, Test Acc: 0.8421Epoch: 197, Train Acc: 0.9467, Test Acc: 0.8421Epoch: 198, Train Acc: 0.9467, Test Acc: 0.8421Epoch: 199, Train Acc: 0.9467, Test Acc: 0.8421Epoch: 200, Train Acc: 0.9467, Test Acc: 0.8421
04
-
将GNN应用到图分类任务上 -
图数据的批处理 -
使用readout layer获得图的嵌入
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月17日
Arxiv
20+阅读 · 2021年5月10日
Arxiv
14+阅读 · 2021年2月16日
Arxiv
13+阅读 · 2018年9月7日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月17日
Arxiv
20+阅读 · 2021年5月10日
Arxiv
14+阅读 · 2021年2月16日
Arxiv
13+阅读 · 2018年9月7日