从基础到 RNN 和 LSTM,NLP 取得的进展都有哪些?


本文基于 NLP 的基础知识,全方位介绍了 NLP 随着深度学习和神经网络的应用所取得的进展。
原标题 | Natural Language Processing: From Basics to using RNN and LSTM
作者 | vibhor nigam
译者 | 黄闯(浙江大学)、路双宁(成都信息工程大学)
注:本文的相关链接请访问文末【阅读原文】
计算机如何理解语言?
计算机要处理任何概念,都必须以一种数学模型的形式表达这些概念。
什么是自然语言处理?
自然语言处理,或简称为NLP,被广泛地定义为通过软件对自然语言(如语音和文本)的自动操作。
基本的转换
分词,词干提取,词形还原
由于词干提取是基于一组规则发生的,因此词干返回的词根可能并不总是英语单词。 另一方面,词形还原可以适当地减少变形词,确保词根属于英语。
N-grams(N元模型)
将一门自然语言分解成n-gram是保持句子中出现的单词数量的关键,而句子是自然语言处理中使用的传统数学过程的主干。
转换方法
TF-IDF
TF-IDF是一种对词汇进行评分的方式,按照它对句子含义的影响的比例为单词提供足够的权重。得分是两个独立评分,词频(tf)和逆文件频率(idf)的乘积。

独热编码
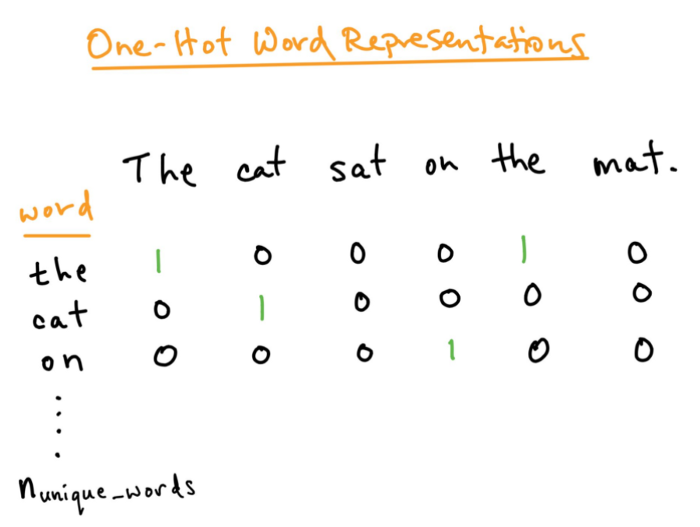
词嵌入
 每个词被映射到一个特征空间里(性别,王室成员,年龄,食物等)
每个词被映射到一个特征空间里(性别,王室成员,年龄,食物等)
然而,事实上这些维度并不那么清楚或便于理解。但由于算法是在维度的数学关系上训练的,因此这不会产生问题。从训练和预测的角度来看,维度所代表的内容对于神经网络来说是没有意义的。
表示方法
词袋
词袋是一种以表格表示数据的方法,其中列表示语料库的总词汇表,每一行表示一个观察。单元格(行和列的交集)表示该特定观察中的列所代表的单词数。 它有助于机器用易于理解的矩阵范式理解句子,从而使各种线性代数运算和其他算法能够应用到数据上,构建预测模型。
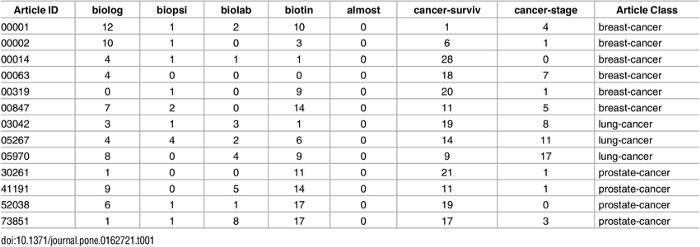
-
它忽视了文本的顺序/语法,从而失去了单词的上下文。 -
这种表示方法生成的矩阵非常稀疏,并且更偏向于最常见的单词。试想,算法主要依赖于单词的数量,而在语言中,单词的重要性实际上与出现频率成反比。频率较高的词是更通用的词,如the,is,an,它们不会显着改变句子的含义。因此,重要的是适当地衡量这些词,以反映它们对句子含义的影响。
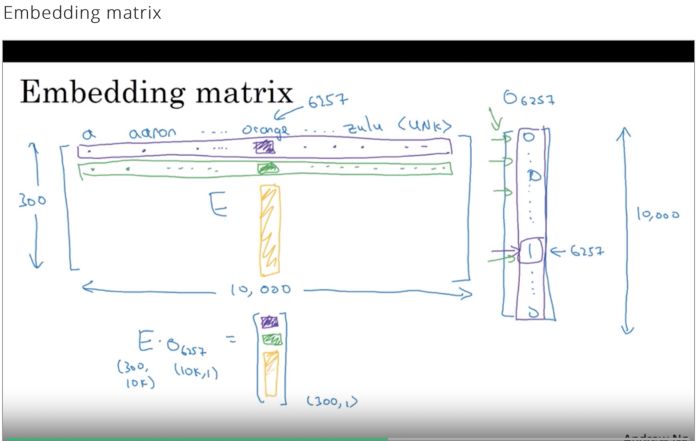
嵌入矩阵
为了将样本转换为其嵌入形式,将独热编码形式中的每个单词乘以嵌入矩阵,从而得到样本的词嵌入形式。
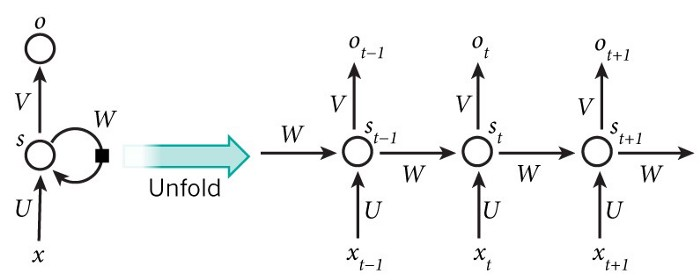
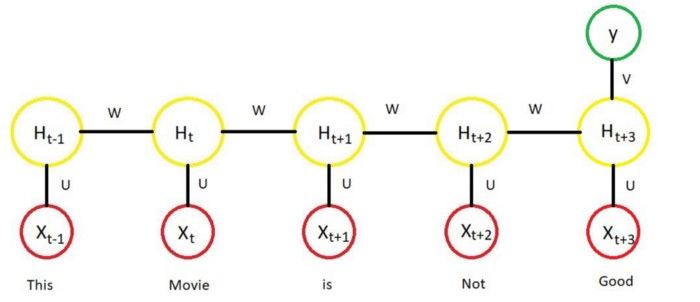
循环神经网络(RNN)
循环神经网络的的标准输入是一个词而不是一个完整的样本,这是概念上与标准神经网络的不同之处。这给神经网络提供了能够处理不同长度句子的灵活性,而这是标准神经网络无法做到的(由于它固定的结构)。它也提供了一个额外的在不同文本位置共享特征学习的优势,而这也是标准神经网络无法做到的。
-
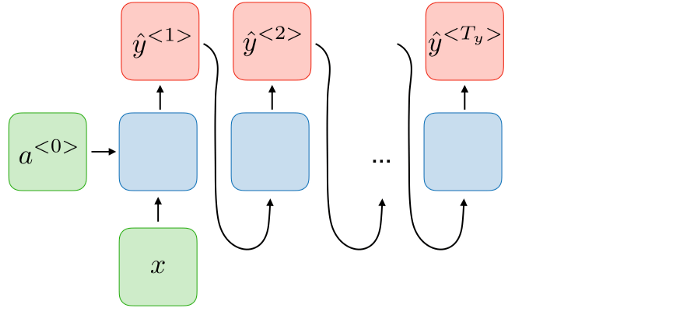
1.多对一的RNN:多对一的架构指的是使用多个输入(Tx)来产生一个输出(Ty)的RNN架构。适用这种架构的例子是分类任务。
上图中,H表示激活函数的输出。 -
2.一对多的RNN:一对多架构指的是RNN基于单个输入值生成一系列输出值的情况。使用这种架构的一个主要示例是音乐生成任务,其中输入是jounre或第一个音符。
-
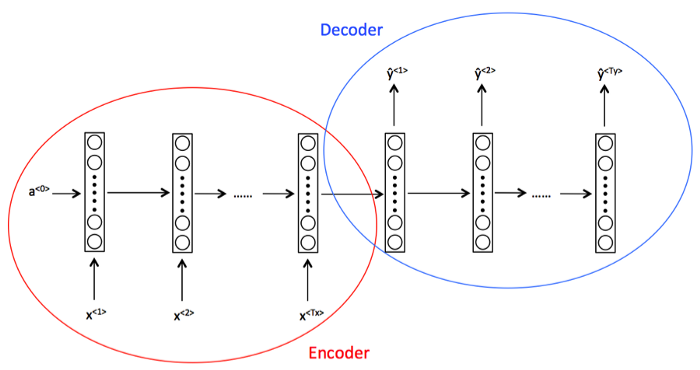
3.多对多(Tx不等于Ty)架构:该架构指的是读取许多输入以产生许多输出的地方,其中,输入的长度不等于输出的长度。使用这种架构的一个主要例子是机器翻译任务。
Encoder(编码器)指的是读取要翻译的句子的网络一部分,Decoder(解码器)是将句子翻译成所需语言的网络的一部分。
RNN的局限性
-
上述RNN架构的示例仅能捕获语言的一个方向上的依赖关系。基本上,在自然语言处理的情况下,它假定后面的单词对之前单词的含义没有影响。根据我们的语言经验,我们知道这肯定是不对的。 -
RNN也不能很好地捕捉长期的依赖关系,梯度消失的问题在RNN中再次出现。
门控循环单元(GRU)
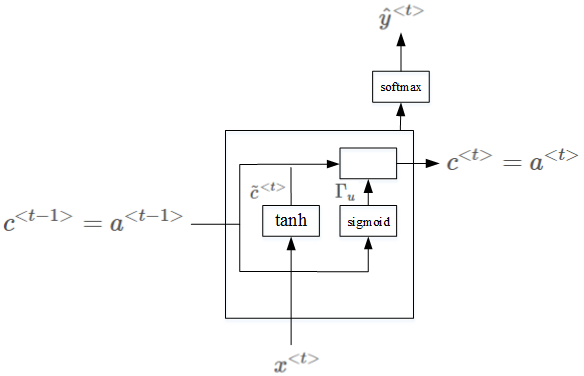
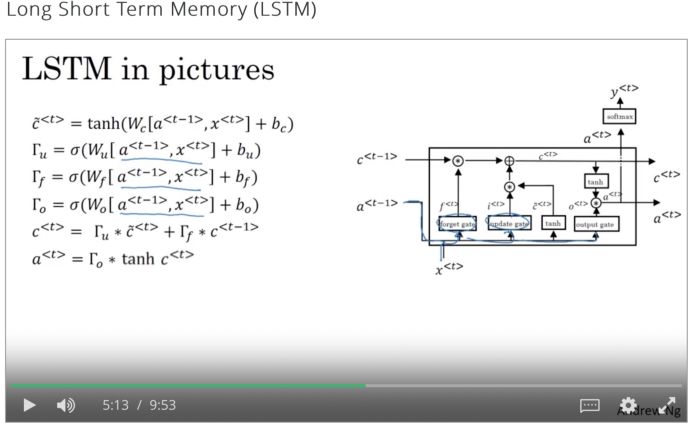
LSTM

 点击
阅读原文
,查看本文相关内容
点击
阅读原文
,查看本文相关内容
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文