多场景适配,TNN如何优化模型部署的存储与计算?

在新基建大潮下,人工智能在社会发展中的角色越来越重要。技术开源构建了开放共进的生态环境,帮助行业应用加速落地,同时在解决行业实际问题时不断迭代,推动了人工智能技术普及。
6 月 10 日,腾讯优图实验室宣布正式开源新一代移动端深度学习推理框架 TNN,通过模型部署在存储上的优化以及在计算上的优化,实现在多个不同平台的轻量部署落地,性能优异、简单易用。基于 TNN,开发者能够轻松将深度学习算法移植到手机端高效的执行,开发出各式各样充满个性和特色的 App。本文整理自腾讯优图实验室、极客邦科技和 InfoQ 联合主办的「优 Tech 沙龙」,分享嘉宾是来自腾讯优图实验室的高级研究员 Darren。
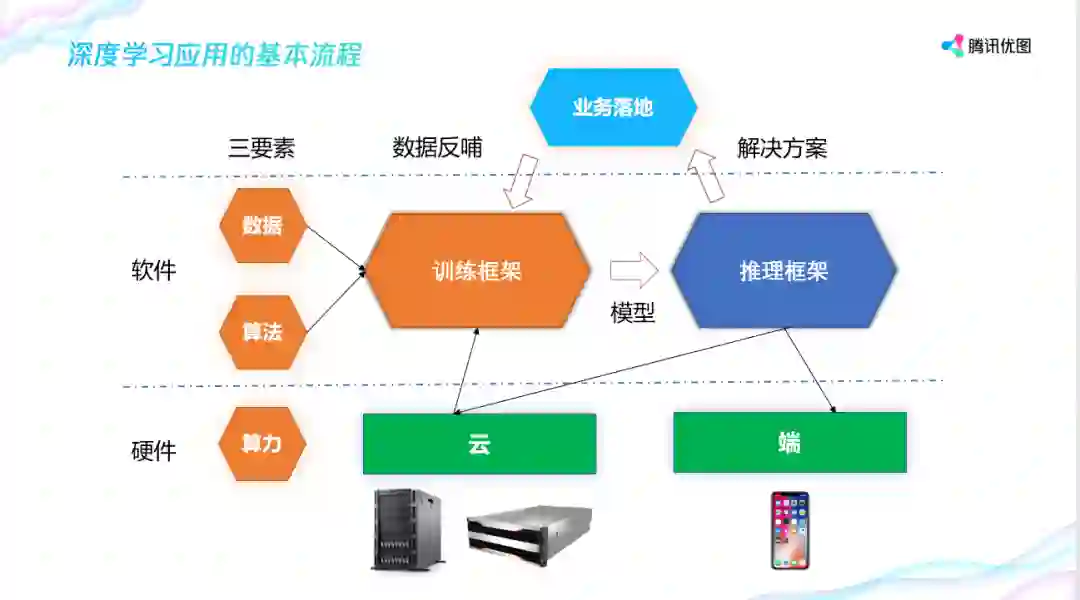
深度学习有三个要素:数据、算法、算力。 按照软件和硬件划分,算力代表硬件,数据和算法代表软件。
在硬件层面又分云和端侧,云端硬件以英特尔和英伟达的服务器为代表,端侧则包括手机和摄像头等。在软件层面,数据和算法通过训练框架练出算法模型,然后与推理框架结合,形成各种各样的解决方案在业务中落地。业务落地之后又会反哺实际业务场景的一些数据给到训练框架,这样一个循环过程使算法模型在业务场景下的精度越来越高。
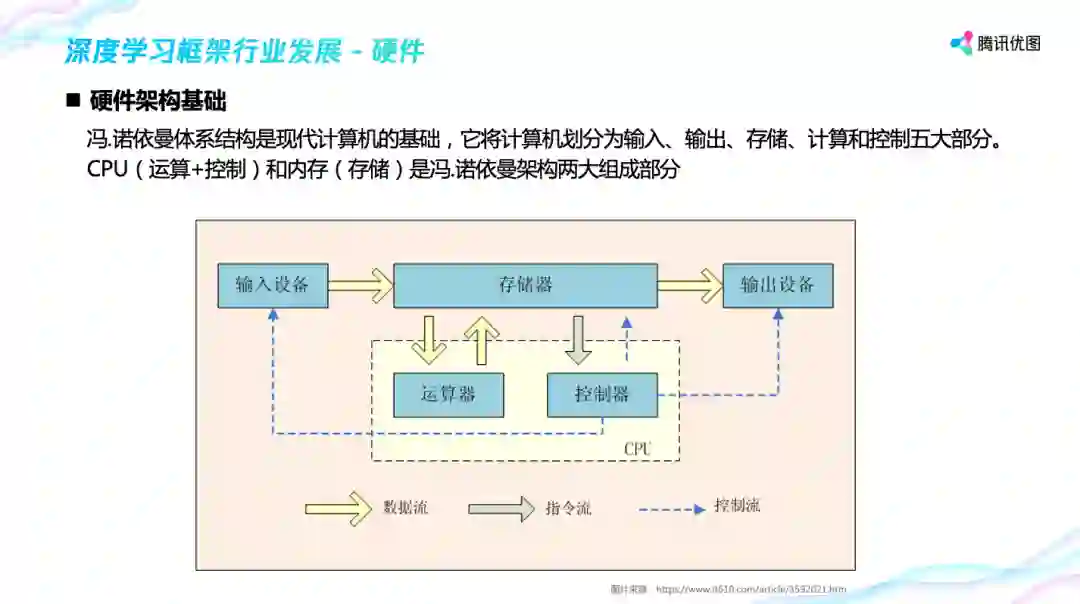
冯. 诺依曼体系结构是现代计算机的基础,它把 计算机划分为输入、输出、存储、计算和控制五大部分,CPU(运算 + 控制)和内存(存储)是其中两大组成部分,硬件架构发展以及软件框架的优化都与这两个模块息息相关。
在硬件架构的演进中,CPU 为保证通用处理性能,大量面积用于控制单元,像应用于计算的 ALU 单元就比较小,导致算力比较弱。
与 CPU 架构设计相反, GPU 中运算器的规模远远超过控制器,极大的增强了数据并行处理的计算能力,使得 GPU 在图形 / 图像处理领域中快速崛起,但是,GPU 功耗太高。英伟达最新的 A100 型号 625T 算力下功耗 400W。
针对功耗高,业界又产生了 AI 芯片,它根据深度学习算法中卷积运算占绝对大头的特点,专用卷积加速模块,同时保障了算力强和功耗低优点。

2017 年称为 AI 芯片元年,Google TPU 率先发布,号称领先 GPU 10 倍。随后,从 APU 到 ZPU 各种 AI 芯片陆续推出,NVIDIA 也在其的 volta 和 turing GPU 中加入了专为 AI 设计的 tensorcore 矩阵计算单元,AI 芯片战争全面打响。
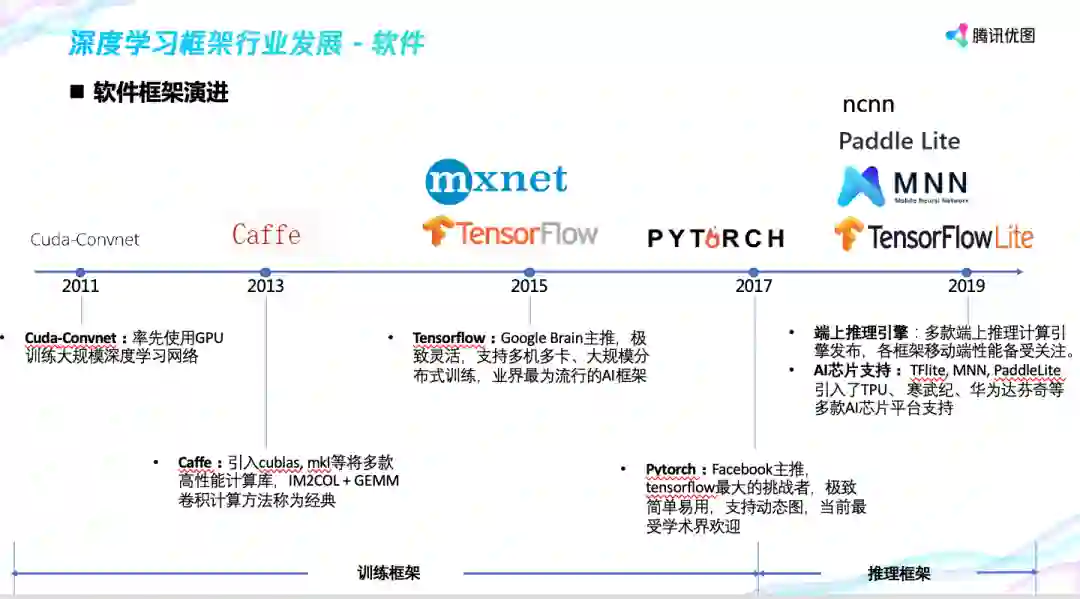
不断变得强大的算力为 AI 计算提供了高性能的硬件基础设施。好马配好鞍,AI 计算还需要强大的配套软件框架,帮助算法工程师们实现更便捷的算法模型设计、优化和部署,下图是软件框架的演进。
优图实验室作为腾讯顶级的 AI 实验室,很早就在业务落地中遇到了推断性能的瓶颈,布局推断框架。
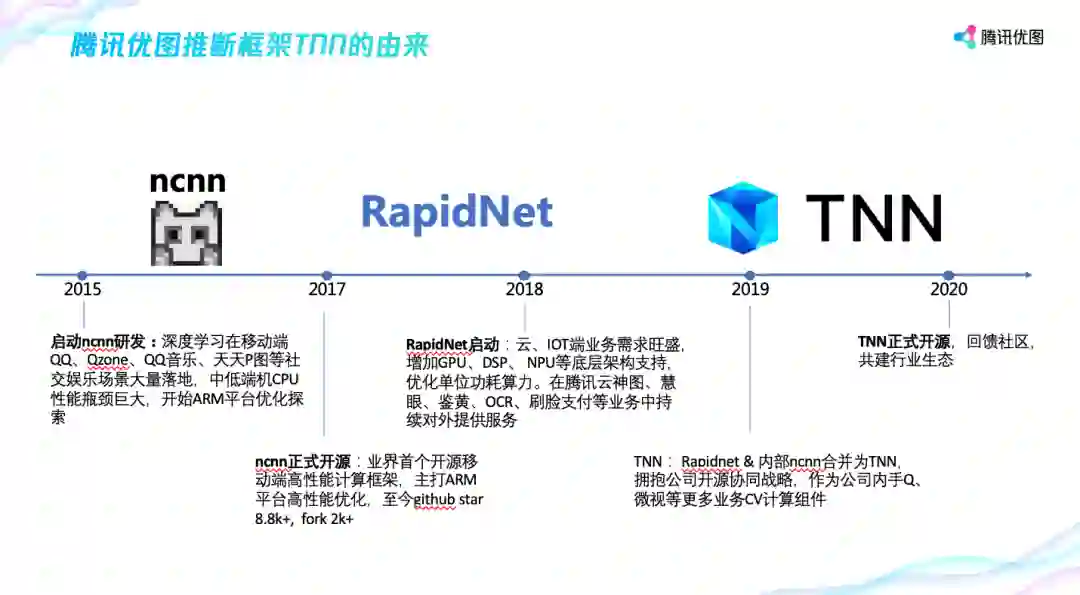
早在 2015 年,在 Tensorflow 等训练框架出现之前,腾讯优图就开始了推断框架的布局。2017 年,优图实验室开源了 ncnn 推断框架,这是首个专注于移动端的开源推断框架。2018 年,伴随着部门业务场景由 2C 转向 2B,云、IoT 端业务需求变得旺盛起来,英伟达 GPU 和 AI 专有芯片拥有巨大的性能和成本优势,为此优图内部整合了之前移动端的经验并适配英伟达 GPU 和 AI 专有芯片推出新的框架 RapidNet。2019 年后公司大力推行开源协同战略,优图实验室协同公司其它做框架的部门如天天 P 图团队、TEG 的 AI 平台部一起推出的 TNN 框架,并于 6 月 10 日全球开源。
TNN 在移动端上对 CPU、GPU 做了极致优化,性能达到行业前列。TNN 也支持多种精度的计算以及多种内存复用以适配低端设备。
在模型支持上,ONNX 作为中间格式以支持 Pytorch、Tensorflow 等主流训练框架,当前算子数目超过 80+。
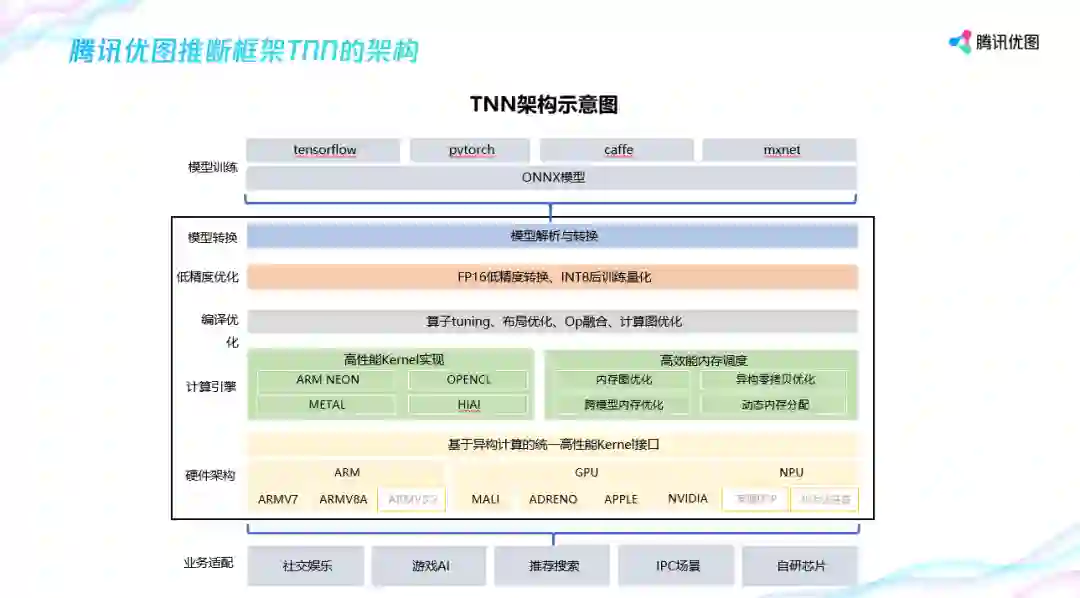
硬件架构适配方面,TNN 适配了 ARM 的 v7\v8, 移动端 GPU 的 mali、高通和苹果,NPU 上也适配了华为的达芬奇和 Intel 的 Movidius,这部分目前还没有开放出来。在腾讯内部,TNN 已经在手机 QQ、微视、天天 P 图等产品中落地,包括前段时间风靡朋友圈的儿童节变小孩、魔法天空、光感染发等个性玩法。
一是内存成本高内存容量不足。以英伟达 GPU 为例,同级 GPU 3 年来算力 30x,内存仅 4x。第二,内存性能问题,以 CPU 为例,内存速度、内存通信带宽的增长速度远慢于 CPU 频率的增长,让内存逐渐成为处理器周围的一道墙,堵住了输入输出,使其无法充分施展性能。这就是所谓的“内存墙”。
为此,在内存上的优化,也主要从两个点着手,尽量减少内存使用,尽量让内存的读写更快。
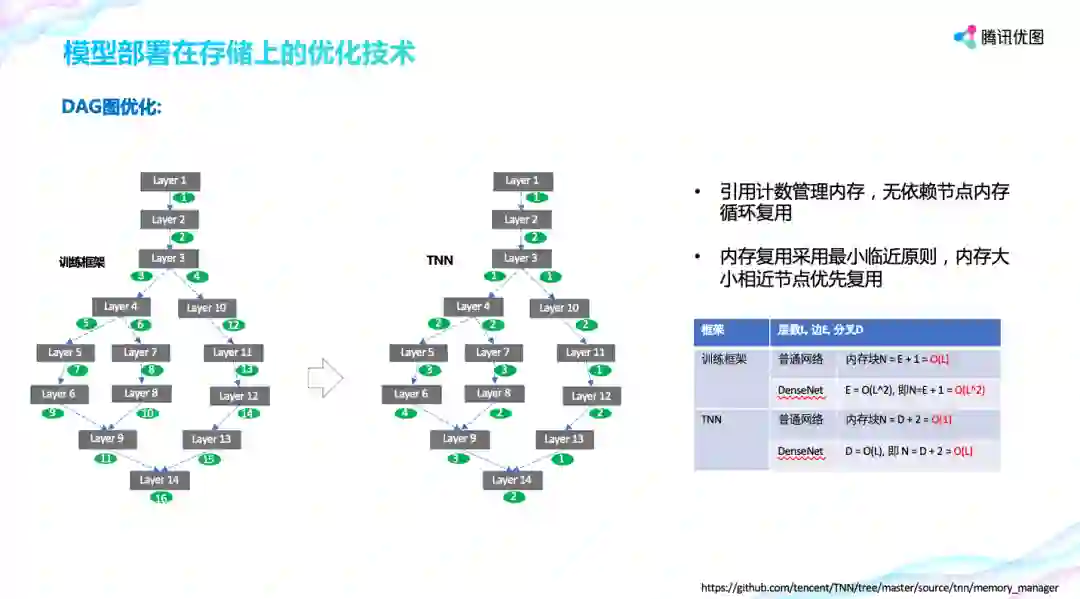
关于内存使用量,腾讯优图引入引用计数管理内存,无依赖节点内存循环复用,极大的减少了内存使用量。 如下所示,左图是一般训练框架的内存使用示例,从图中可以看到需要 16 块内存,而使用引用计数后,通过循环复用,仅需要 3 块。
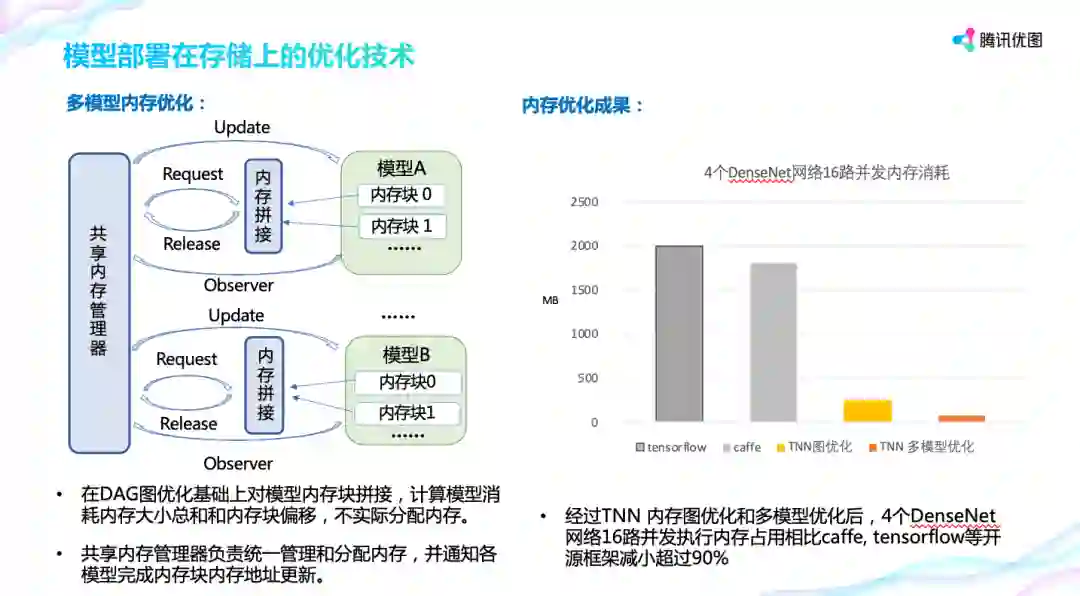
在单模型内存复用的基础上,TNN 引入共享内存管理器,让多个模型间进行复用,这样模型间只要使用最大的内存就可以。实际对比发现,在 DenseNet 网络上,上述优化方案可以带来 90% 的优化空间。
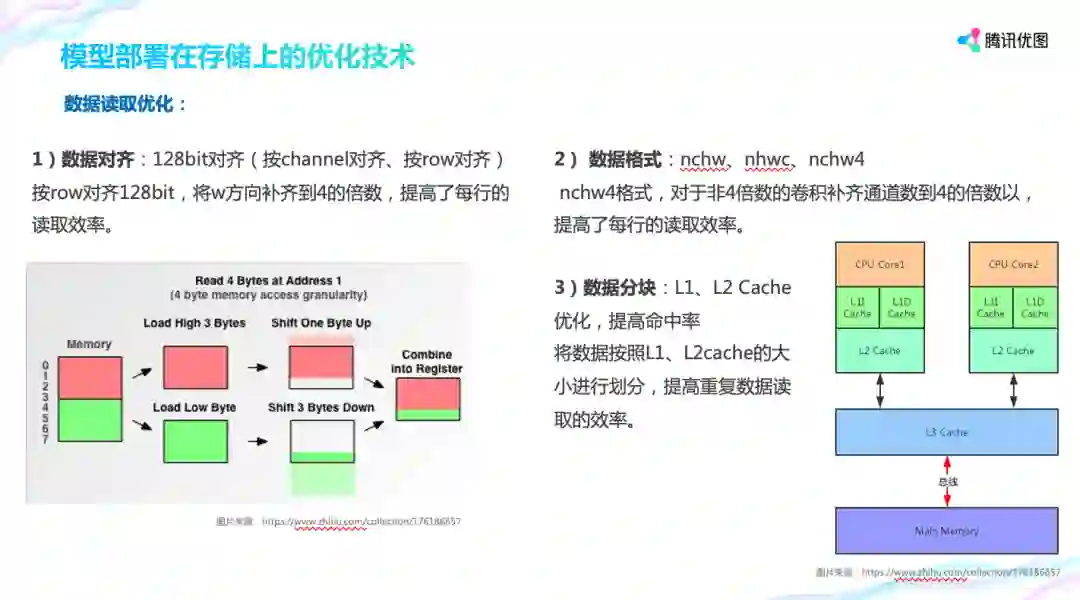
关于内存读写,TNN 尽量让要读取的数据是 128bit 对齐,以提高数据的效率。 如图,在读取 1 位置起始的 4byte 数据时,计算机先读取上面红色的 4byte 然后上移一个 byte,再读取绿色的 4 个 byte 下移 3byte,最后组合在一起,这样就花费了两次读的时间。解决办法是,在深度学习计算中对数据格式进行排布,比如采用 nchw4 格式的数据排布,将 C 方向上的 4 个值合并在一起,提高了每行的读取效率。
移动端、嵌入式端设备型号各异,平台性能参差不齐,而 深度学习算往往需要巨大的运算量。虽然各大厂商旗舰机型不断在刷新性能记录,但中低端机型一直是安卓阵营的主力。 安卓官方数据,超 50% 安卓设备还未用上 2016 年的安卓 7.0;而腾讯 wetest 数据:超 60% 手机依然是中低端 CPU 配置。因此,如何在低端设备上运行深度学习,挑战巨大又至关重要。
如何进行计算优化?从粗粒度到细粒度有几个优化策略:图优化、算子公式优化、算子手动调优、异构调度调优。
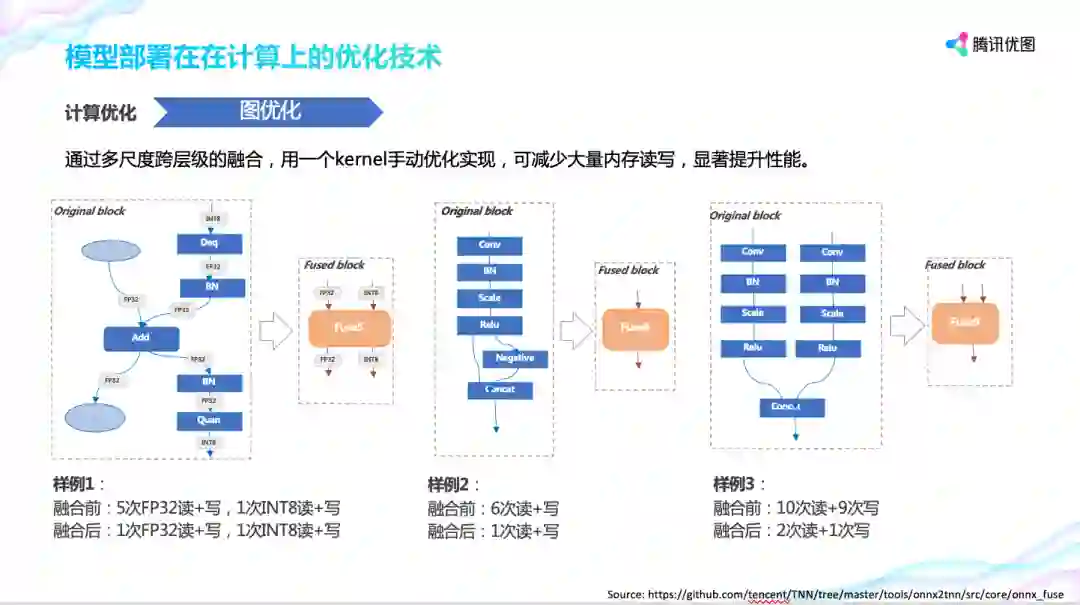
先讲图优化,Tensorflow、PyTorch 等框架生成的网络算子粒度小,存在很多粘合剂算子,导致深度学习网络包含成千上万的运算节点,这会带来线性增长的内存读写次数。TNN 采用图优化对网络进行等效融合,将复杂子图融合成单运算节点来精简整个网络,既减少计算量又减少内存读写。以右边为优化前整个计算流程需要 10 次内存读,9 次内存写,而优化后只需要 2 次读和 1 次写。
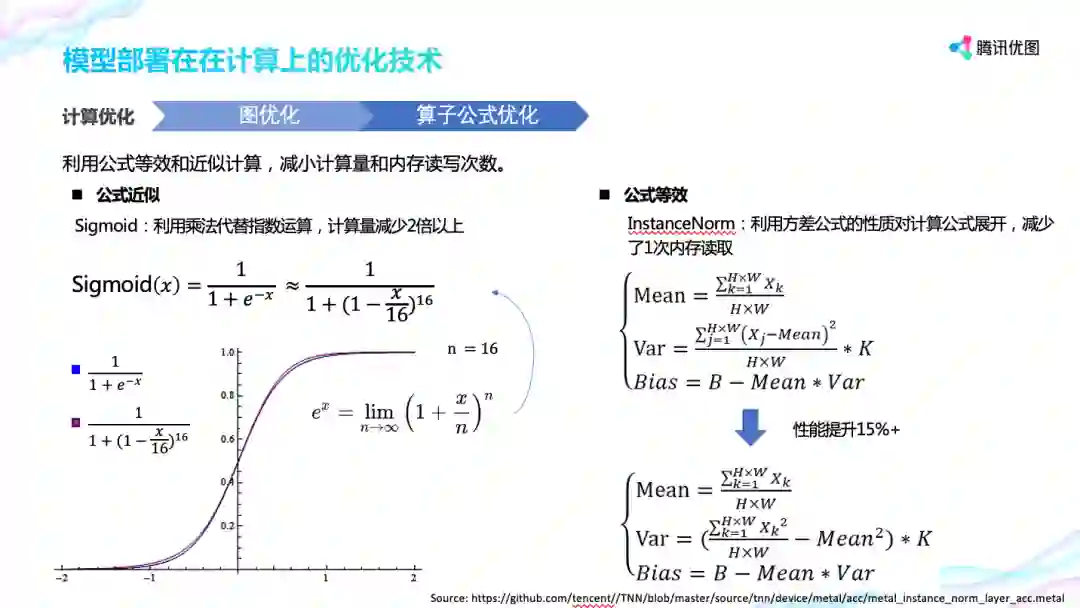
算子公式优化包括公式近似和公式等效。
公式近似,以 Sigmoid 为例,根据指数函数的定义,取 n=16, 从图形上看,两者曲线非常近似,而 通过这种利用乘法代替指数运算的方式,sigmoid 的性能提升了 2 倍。
公式等效,以 InstanceNorm 为例,上面是 InstanceNorm 算子的定义,从中可以看到,它会先遍历一次内存计算均值 mean,再遍历一次内存计算数据的方差,也就是说按照定义来实现的话,需要遍历两次内存。而下面 TNN 利用方差公式的性质对 InstanceNorm 计算公式展开,在读取内存的时候同时计算均值和平方和,这样就只需要遍历 1 次内存,根据实测,优化后性能可提升 15% 以上。
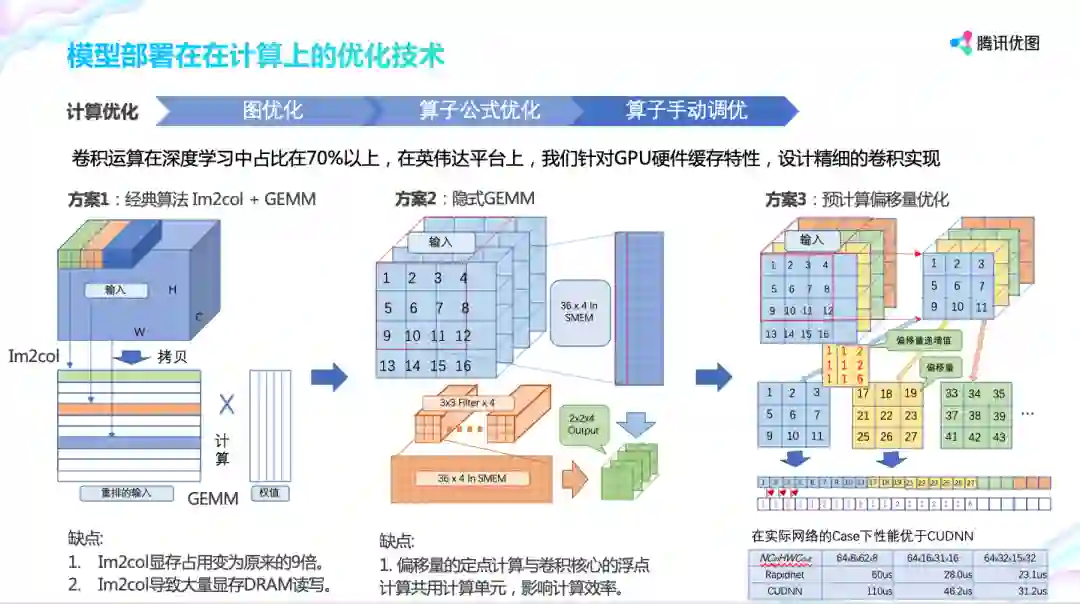
再往底层走,对算子实现进行手动调优。由于卷积运算在深度学习中占比在 70% 以上,这里以英伟达平台为例,讲解如何针对 GPU 硬件缓存特性设计精细的卷积实现。
方案 1 将输入在主存中重排输入,并与权值矩阵进行矩阵 GEMM 乘法运算。它有明显的缺点:Im2col 导致大量显存 DRAM 读写。对于 3x3 的卷积来说 Im2col 显存占用变为原来的 9 倍,导致大量显存 DRAM 读写。
方案 2 隐式 GEMM 将数据就行分块这样它可以在 GPU share memory(高速缓存)进行迭代展开,且只占用固定大小。im2col 相关指令与矩阵乘法指令交替发射,相互掩盖延迟。
方案 3 更进一步,根据偏移量递增值固定的特性,预先计算好递增值,消除数据展开时偏移量的计算,降低计算单元压力,提高计算速度。整个设计的性能加速在 20%-50% 左右。
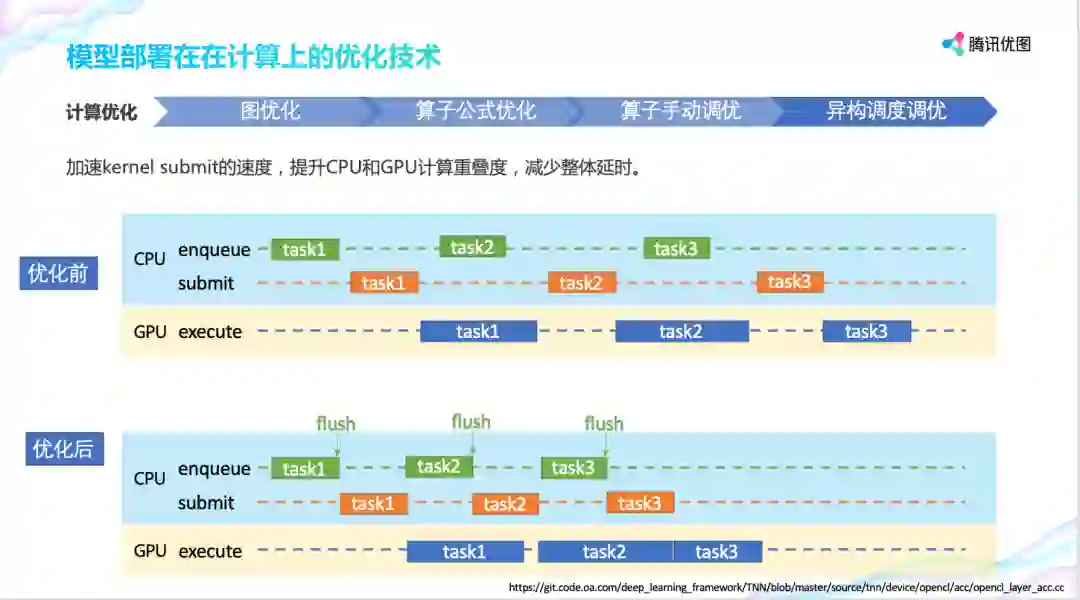
异构调度优化。CPU 在提交计算任务后,GPU 并不一定马上进行计算,这加大了整体任务的时延。TNN 在提交任务时可以手动触发以提高计算的优先级,这样 GPU 实际执行的时间得到提前。以图中 task3 为例,几个色块直接存在 gap,而优化后消除了 gap。
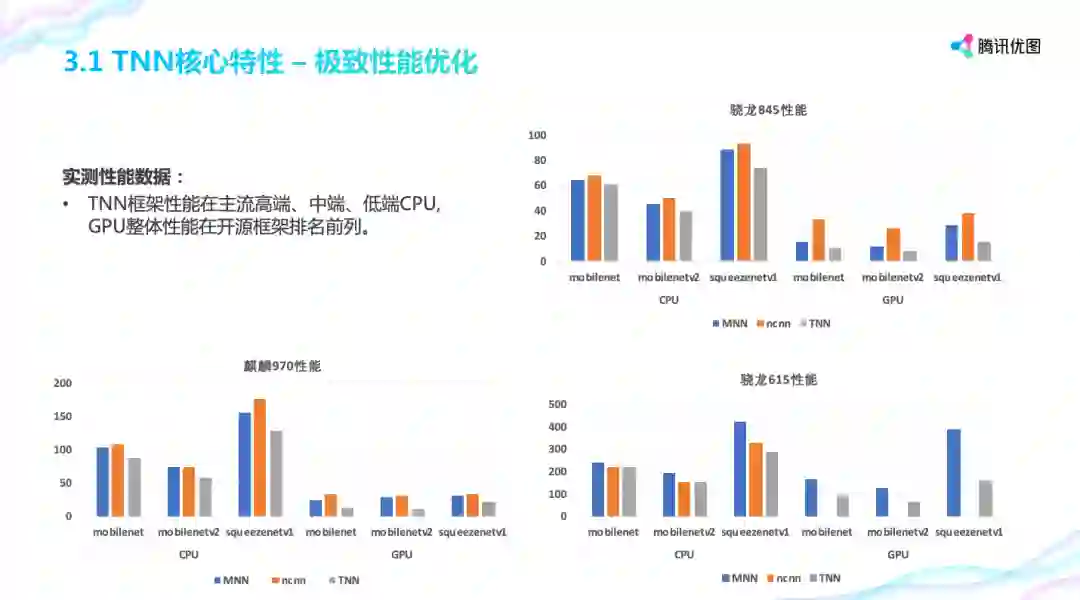
通过前面各种优化手段,TNN 框架性能在主流高端、中端、低端 CPU, GPU 性能在开源框架排名前列。
图像超分辨,是指利用机器学习将低分辨率图像转化为高分辨率图像,并保持图像的细节信息不丢失。
这一技术面临的挑战有两个方面:一方面是需要基于原图尺寸计算,数据运算量大;另一方面是移动端尤其是 Android 端机型范围广,中低端机占比 50% 以上,如何充分利用计算资源挑战极大。
基于这些挑战,优图实验室采用了三步走的技术方案:
第一,采用模型动态部署的方案,将机型划分为高中低三档,不同等级的机型跑不同复杂度的模型,减轻机器的计算压力。第二,异构处理,根据 CPU、GPU 计算性能对图片区域进行任务划分,最后再拼接成超分辨图像。第三,图片分小块处理。异构处理是按 CPU、GPU 进行的大块划分,除此之外,还要把大块区域继续划分成很多小块如 16x16,8x8,使用算法对图片的纹理复杂度进行识别,复杂度小的小块直接使用插值进行放大,复杂度大的小块利用模型进行放大,这样大大提高了图片的处理速率。
图像超分辨到时是业界超分辨深度神经网络在移动端首次落地,节省了 75% 的流量,图片下载响应时间从 600ms 降低到 180ms。同时依靠前面所说的优化策略,实现在安卓侧机型覆盖率达到 74.3%,iOS 侧机型覆盖率达到 95%。
Q: TNN 支持多种计算单元中的不同类别、不同架构、不同序列的计算单元,最优性能的优化策略普遍存在差异,请问是 deviceQuery 查询动态实现底层接口还是开发者自行判断和选择最优的方式?
A: 目前来说 TNN 在计算设备会根据不同架构自适应做一些策略优化,比如说 Mali GPU、高通 GPU 采用不同的 localsize。但在上层应用上还没有自动选择使用哪种计算设备的功能。自动选择是个很好的建议,但是这需要根据模型和设备能力做出选择,框架内部比较难或者说难以用优雅的方式实现,当前还是交给 APP 层做选择。
Q:通过近似计算会不会造成误差累计?特别是网络层数很多时,腾讯优图是如何评估这些误差的?
A:首先近似计算目前默认是不打开的。是否打开需要开对应的算子在整个网络中的耗时占比,比如整体占比就 15%,近似计算性能翻倍的情况下整体也就提升 7%,收益不大。而在确实需要的情况下,也可以通过部分打开的方式来解决累积误差的问题。可以在测试集上评估,看每个位置上的算子打开近似计算后对精度的影响,最后综合考虑。更进一步的方式是训练的时候把近似计算的误差也带进去,通过反复训练来减小误差。

点个在看少个 bug 👇




