详解TF-Ranking:Google开源的排序框架,应用于邮件检索、推荐系统等场景
今天分享的是一个有关LTR框架的介绍,LTR是Learning-To-Rank,解决的是排序问题。排序问题在人工智能领域应用很广,比如在Gmail里搜索一个关键词,返回最匹配的邮件。再比如进入Google Drive后的一些文章推荐。
傲海的分享主要参考Google2019年发布的一篇论文《TF-Ranking:Scalable TensorFlow Library for Learning-to-Rank》,蛮长的,看了小一周才学习完。这个库已经开源了,大家可以在下方地址访问并使用:
https://github.com/tensorflow/ranking
介绍LTR的话先要讲下Pointwise、Pairwise、Listwise这三个模式的区别,以生活中的一个例子说明:
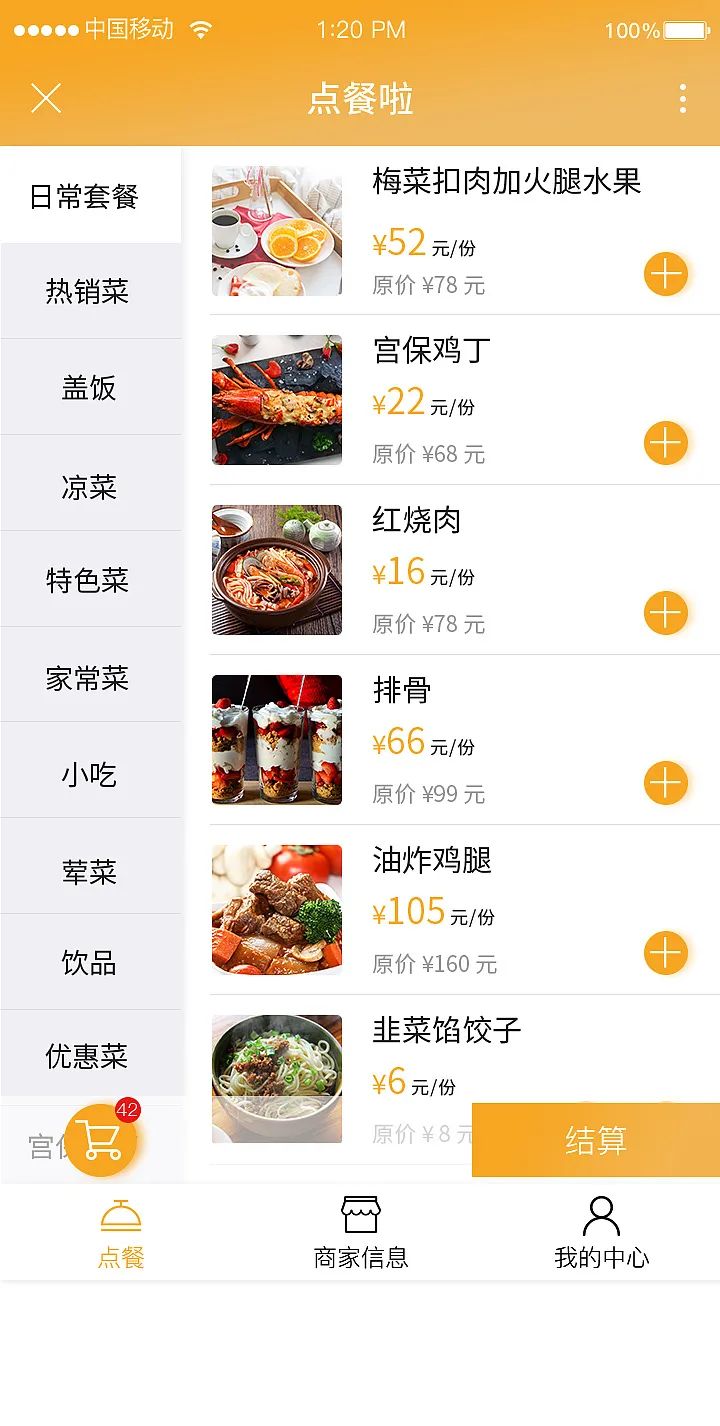
上图是一个点餐界面,假设我们强制用户只能在界面中点一个菜,那么Pointwise、Pairwise、Listwise是如何构建训练过程的呢:
Pointwise:只关心单点的优化,比如用户点了排骨。那么就把排骨构建成正样本,其它菜都是负样本,构建成一个二分类问题,进行训练。Pointwise的问题在于缺少对整个列表的关系属性的挖掘
Pairwise:把优化问题看作两个样本的组合,训练的时候输入的是两个样本的特征组合,返回值比较高的样本
Listwise:把整个序列看作一个训练样本进行优化,Listwise也是目前比较好的一种推荐场景训练模式,因为它会完全考虑所有样本的关联属性。比方说我点了红烧肉,那么排骨也可能是我喜欢的即使我没点,这种潜在的属性挖掘用Listwise更合理
Pointwise、Pairwise、Listwise的训练模式的不同主要会影响训练中使用的Metrics评价方法,也就是DCG、NDCG等,这里就不展开说。
大部分同学可能还是偏应用层,所以废话不多,直接介绍TF-LTR的框架。
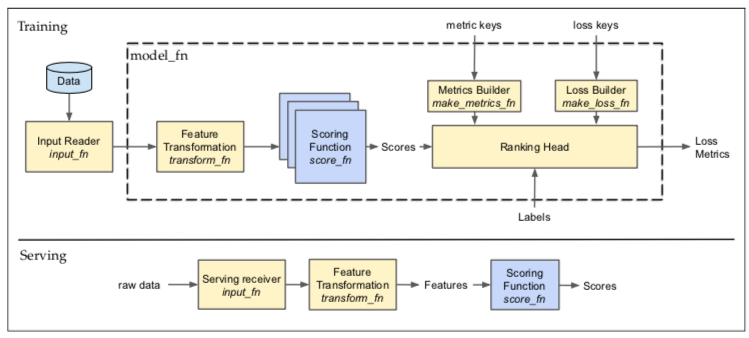
TF里面LTR框架把整个排序流程分为Training和Serving两个部分,其中包含input_fn、transform_fn、scoring_fn、ranking head这几个大的模块,下面就分别介绍下。
1.input_fn
input_fn是一个数据IO的框架,这个框架可以从存储空间拉取数据,也可以从进程中直接读取。兼容了Libsvm、tf.sequence等数据格式,也可以自定义。
有一个定义挺有意思的,他把per item feature定义叫做3-D tensor,就是这样的三元组(queries,items,feature)。context feature定义叫做2-D tensor,是个二元组(queries,feature)。PS:这个可以用到以后写架构PPT里面,看上去很专业的样子。
2.transform_fn
这一步骤做的是特征转换,把sparse feature转换成dense feature。总之,特征embedding就得了,想办法把特征给embedding了。
3.scoring_fn
定义打分规则,在training和predicting的过程中用这个函数进行打分。官方给的例子挺奇怪,为啥打分函数要这么复杂--

4.ranking模块
首先要定义ranking loss和ranking metric,这也是模型训练的最基本流程,按照Pointwise、Pairwise、Listwise的不同模式在这里配置metric函数就好了。
ranking模块的输入是scoring_fn的分数以及真实的客户行为label,根据这两个反馈计算loss,根据metric不断迭代模型,最终实现收敛。
TensorFlow在向业务层不断贡献各种开源库,把整个人工智能应用领域的门槛降低,这是个挺好的现象,后续如果做推荐或者文章检索可以考虑使用TF-LTR库试试。



