并行算法演进,从MapReduce到MPI

再不点蓝字关注,机会就要飞走了哦
1 MapReduce路线
从函数式编程中的受到启发,google发布了MapReduce的分布式计算方式;通过将任务切分成多个叠加的Map+Reduce任务,来完成复杂的计算任务,示意图如下
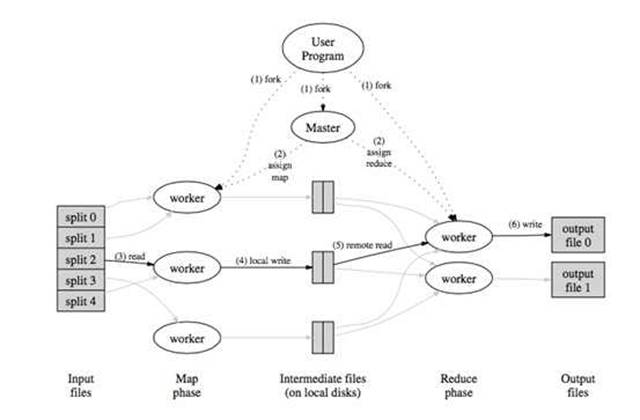
MapReduce的主要问题有两个,一是原语的语义过于低级,直接使用其来写复杂算法,开发量比较大;另一个问题是依赖于磁盘进行数据传递,性能跟不上业务需求。
为了解决MapReduce的两个问题,Matei提出了一种新的数据结构RDD,并构建了Spark框架。Spark框架在MR语义之上封装了DAG调度器,极大降低了算法使用的门槛。较长时间内spark几乎可以说是大规模机器学习的代表,直至后来沐帅的参数服务器进一步开拓了大规模机器学习的领域以后,spark才暴露出一点点不足。如下图
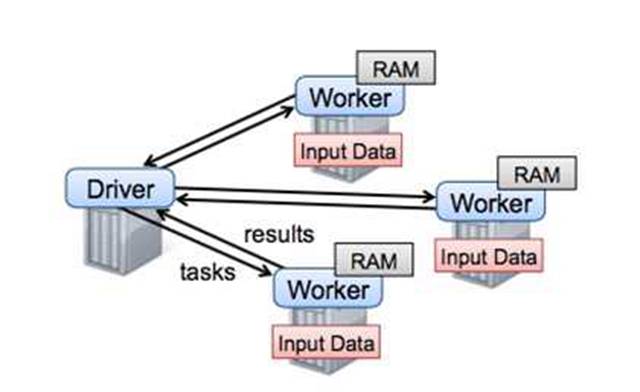
从图中可以看出,spark框架以Driver为核心,任务调度和参数汇总都在driver,而driver是单机结构,所以spark的瓶颈非常明显,就在Driver这里。当模型规模大到一台机器存不下的时候,Spark就无法正常运行了。所以从今天的眼光来看,Spark只能称为一个中等规模的机器学习框架。剧透一句,公司开源的Angel通过修改Driver的底层协议将Spark扩展到了一个高一层的境界。后面还会再详细介绍这部分。
MapReduce不仅是一个框架,还是一种思想,google开创性的工作为我们找到了大数据分析的一个可行方向,时至今日,仍不过时。只是逐渐从业务层下沉到底层语义应该处于的框架下层。
2 MPI技术
沐帅对MPI的前景做了简要介绍;和Spark不同,MPI是类似socket的一种系统通信API,只是支持了消息广播等功能。因为对MPI研究不深入,这里简单介绍下优点和缺点吧;优点是系统级支持,性能杠杠的;缺点也比较多,一是和MR一样因为原语过于低级,用MPI写算法,往往代码量比较大。另一方面是基于MPI的集群,如果某个任务失败,往往需要重启整个集群,而MPI集群的任务成功率并不高。阿里在论文中中给出了下图:
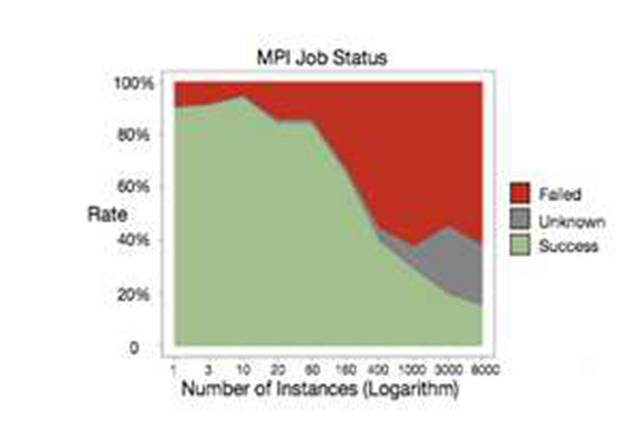
从图中可以看出,MPI作业失败的几率接近五成。MPI也并不是完全没有可取之处,正如沐帅所说,在超算集群上还是有场景的。对于工业届依赖于云计算、依赖于commodity计算机来说,则显得性价比不够高。当然如果在参数服务器的框架下,对单组worker再使用MPI未尝不是个好的尝试,[鲲鹏系统正式这么设计的。
转自36大数据
长按指纹
一键关注






