为什么经过三十年的发展,现代计算机的响应速度甚至比不上Apple 2?

我有一种感觉,就是我们现在使用的电脑比小时候用的那些要慢。但我又不能完全相信这种感觉,因为一些研究表明,人类的直觉是不可靠的。于是,在过去几个月,我用高速相机拍下了一些设备的响应速度,得出的结果如下图所示。

这组结果显示了从按下按键到屏幕上显示相应字符的延迟时间,并按照从快到慢的顺序进行了排列。在延迟时间那一列,单元格的颜色从绿色变成黄色,再到红色,然后是黑色,颜色越暗说明设备的响应速度越慢。从上述表格可以看出,没有一个设备的单元格背景色是绿色的。我也对同一设备上的不同操作系统进行了测试,所以把操作系统的名字部分加粗显示。如果同一设备使用了不同的刷新频率,那么刷新频率就用斜体显示。
在年份那一列,如果设备年份越久远,单元格的紫色越深。
后面两列分别表示 CPU 频率和处理器的晶体管数量。数字越小则单元格的蓝色越深。
为了便于参考,我把数据包在光纤中的传输时间也放在了表格当中。数据包从纽约出发,经过东京和伦敦,再回到纽约。
从表中可以看出,速度最快的机器居然是最古老的那个。配备极高刷新率显示器的游戏主机也只能与 70 年代后期和 80 年代早期的机器一比高下,而普通的现代电脑甚至都比不过 30 年前或 40 年前的老机器。
我们也可以对移动设备做一番比较,如下图所示。
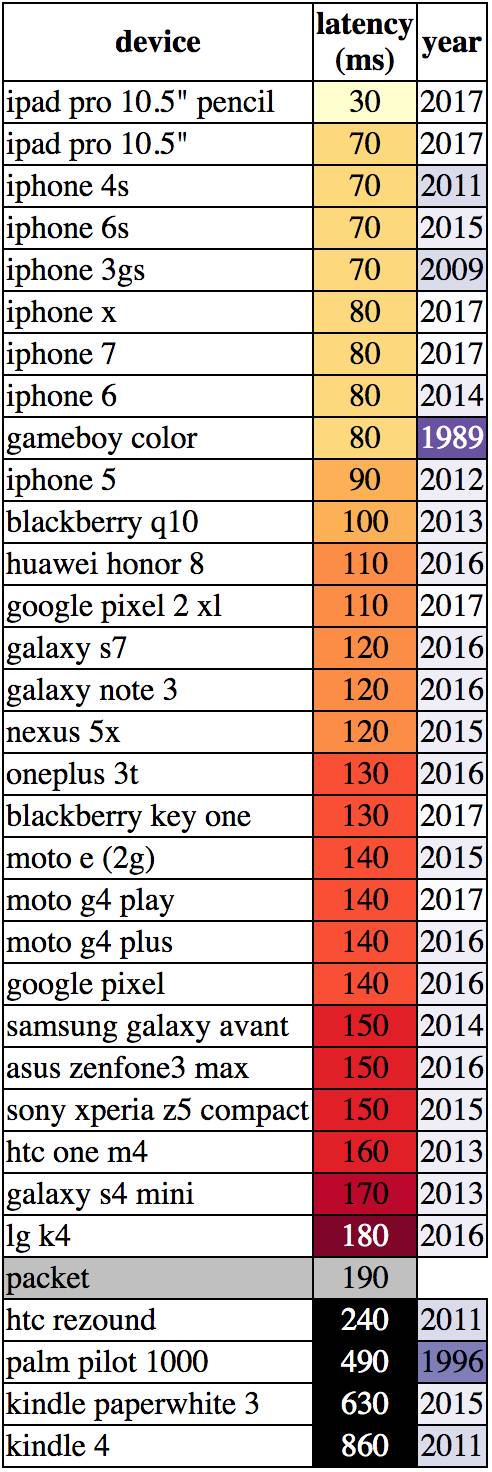
如上图所示,结果也经过排序,设备速度越慢,那么颜色将从绿色到黄色,再到红色,然后是黑色。设备的年份也是通过紫色来表示,设备越老,紫色就越深。
如果我们把 Gameboy Color 排除掉(该设备有别于其他设备),那么最快的那些设备几乎被苹果的手机和平板占据了,其次是黑莓 Q10。尽管我们没有足够的数据解释为什么黑莓 Q10 会比苹果之外的设备快,可能因为黑莓配备了实体键盘,在实现低延迟输入方面比触摸屏要容易得多。另外两款配备了实体键盘的是 Gameboy Color 和 Kindle 4。
接下来就是各种安卓设备。最底下是最古老的 Palm Pilot 1000 和 Kindle。Palm 使用了早期的触摸屏,速度比较慢,而 Kindle 使用了电子墨水屏,它的显示速度比现代手机屏幕要慢很多,所以这些设备垫底一点也不奇怪。
与现代计算机相比(除 iPad Pro 之外),Apple 2 不管在输入和输出上都有很大的优势,因为它不需要进行进程间的上下文切换和缓冲。
在输入方面,现代键盘一般使用 100Hz 到 200Hz 的速度来扫描用户的输入,而 Apple 2 的扫描速度是 556Hz。
如果我们从显示屏方面来分析,我们会发现,显示屏带来了很大的延迟。我有一个显示器,广告上说它的显示切换只需要 1 毫秒,但实际上,我看到一个字符从开始到完全显示需要 10 毫秒。一些高刷新率的显示器声称具备很低的延迟,但实际上都言过其实了。
当刷新率达到 144Hz 时,每一个帧需要 7 毫秒。每个屏幕变化都需要 0 到 7 毫秒的延迟,因为在渲染之前它需要等待下一帧。除此之外,我家的那个声称只需要 1 毫秒切换时间的显示器在完全变换颜色时需要 10 毫秒时间。如果把等待下一帧的时间加上变换颜色的时间,那么总的平均延迟是 7/2+10=13.5 毫秒。
Apple 2 的老式 CRT 显示器的刷新率为 30Hz,延迟只有 8.3 毫秒,这是现在的设备很难超越的。尽管一些高端的游戏显示器可以把延迟降到同等范围,但很少人能够买得起这样的显示器,更何况广告上宣称的速度不一定靠谱。
如果要仔细比较 Apple 2 和现代设备在输入和输出方面的细微差别,那完全可以写成一本书。前 iOS/UIKit 工程师 Andy Matuschak 对 iOS 的渲染机制进行了描述:
硬件有自己的扫描速率,所以会带来最多 8 毫秒的延迟。
渲染事件通过固件传给内核,虽然这个过程很快,但系统在进行调度时仍然会带来几毫秒的延迟。内核将这些事件通过 Mach 端口发送给订阅者(也就是 backboardd)。
backboardd 决定事件应该由谁来接收,这个时候需要加锁,因为与内核之间有一个来回,所以加重了调度延迟。
backboardd 将事件发送给目标进程,在事件得到处理之前,延迟会加重。
这些事件是从主线程出队列的,如果主线程发生了堵塞,也会加重延迟。
UIKit 需要额外的 1 到 2 毫秒的时间来处理事件。
应用程序需要决定如何针对事件作出响应,如果应用程序写得不好,那么可能需要数毫秒时间。最终结果通过 IPC 发送给了渲染服务器。
如果应用程序需要一个共享视频缓冲区,那么与渲染服务器之间又需要一个来回,又会产生调度延迟。
渲染服务器可以自己处理一些轻微的变更事件,如仿射变换货颜色变换;当然也需要处理一些与文本、光栅和矢量有关的操作。
这些更新操作通常需要三个缓冲区:GPU 使用一个缓冲区进行即时渲染,渲染服务器需要另一个缓冲区将当前事件缓冲起来,以便等待下一帧,而应用程序又要用到另一个缓冲区。这里需要更多的锁、更多与内核之间的来回交互。
渲染服务器将这些更新操作应用在渲染树上(这需要几毫秒时间)。
渲染树会被冲刷到 GPU 上,以便填充视频缓冲区。
视频缓冲区与另一个视频缓冲区进行交换。
Andy 说“这些任务所需要的开销其实是很小的,可能是几毫秒的 CPU 时间。其主要开销来自:”
扫描速率(输入设备、渲染服务器、显示器)的不匹配。
进程间的任务移交。
需要太多的锁。
通过比较,Apple 2 几乎没有进程间的任务移交、锁和进程边界问题。显示结果直接被写到显示器内存里,在进行下一轮扫描时会更新显示结果。
刷新频率对延迟有很大的影响。刷新频率从 24Hz 增加到 165Hz 会降低 90 毫秒的延迟。在 24Hz 刷新频率下,每一帧需要 41.67 毫秒,而在 165Hz 下,每一帧只需要 6.061 毫秒。如果不存在缓冲区,那么有望让延迟分别降到 20.8 毫秒和 3.03 毫秒,之间相差了 18 毫秒。但实际相差 90 毫秒,相当于两个帧的延迟,因为 (90-18)/(41.67-6.061)=2。
如果在同一台设备上使用其他的刷新频率,我们将会得到一条“最佳匹配”的曲线,在这台机器上运行 PowerShell,不管刷新频率是多少,都会有 2.5 帧的延迟。于是,我不禁好奇,如果在低延迟的游戏主机上使用无限赫兹的显示器,那么延迟将会是 140-25*41.67=36 毫秒,而一般的机器延迟在 70 毫秒到 80 毫秒之间。
现在人们购买的电脑或移动设备比 70 年代或 80 年代的机器都要慢。低延迟游戏主机和 iPad Pro 可以达到与三、四十年前的机器同等的延迟水平,但其他大部分设备就差太多了。
如果说要找出造成延迟最主要的一个因素,那有可能就是“复杂性”。我们都知道复杂性不是什么好东西。如果你在过去十年参加过一些非学院派、非企业组织的技术大会,极可能会听到有人说复杂性是一切罪恶的根源,所以我们应该尽量降低复杂性。
但复杂性也给我们带来了一些好处。使用相对强大和昂贵的一般性处理器来处理键盘输入会比使用更简单、更便宜的专门逻辑来得慢,但处理器为人们带来了定制键盘的功能,让定制键盘从硬件转向了软件,从而降低了键盘的制造成本。虽然处理器芯片增加了生产成本,但从整体来看,设计和定制化成本的降低让整体的生产成本降得更低。
这种权衡到处可见。例如,我们可以对运行在现代设备上的操作系统和运行 Apple 2 上的操作系统做一番比较。现代操作系统支持同时运行多道程序,并提供了合理的性能,但复杂性的增加和进程间任务移交却带来了严重的延迟。
其实,有很多复杂性是偶然出现的,但它们必然会存在。从硬件架构到 IO 框架的接口调用都存在复杂性,如果我们能够重写它们,或许可以消除这些复杂性,但这样做太难了,我们无法重新去发明这一切,况且我们正从这种规模经济中获益,所以只能维持现状。
正因为如此,为了解决因复杂性带来的糟糕性能的问题,通常会增加更多的复杂性。如果我们想要达到三、四十年前机器的速度,我们无法通过降低复杂性来实现,只会堆砌更多的复杂性。
iPad Pro 是现代工程的一个壮举,它在增加输入和输出刷新频率的同时,又要确保软件管道不会有不必要的复杂缓冲区。高刷新频率的显示设计降低了系统延迟,而这在标准的 60Hz 显示器上是很难做到的。
这种情况在降延迟时是很常见的。降低延迟最常见的做法是增加缓存,但增加缓存会让系统变得更复杂。而如果系统一直会产生新数据,那么这种方案就会愈加复杂。
现代游戏主机 CPU 的晶体管数是 Apple 2 的 50 多万倍,运行速度是 Apple 2 的 4000 多倍,但如果要让现代游戏主机达到 Apple 2 的延迟水平,必须保证应用程序的代码写得足够好,并使用将近 3 倍多的刷新频率,这听起来似乎有点荒唐吧?Powerspec G405 是截止到 2017 年 10 月在这个地球上能够找到的单线程性能最好的机器,但它从键盘到屏幕的延迟(3 到 10 英尺)居然比一个数据包环游世界的延迟(从纽约到东京,经过伦敦,再回到纽约)还要大,这个听起来是不是更加荒唐?
从好的一面讲,我们已经走出了延迟的暗黑时代,现在我们完全可以攒一台电脑或购买一台平板能够达到三、四十年前同等的延迟水平。我不禁想起了屏幕分辨率和像素的暗黑时代,90 年代的 CRT 显示器比之后的非笔记本 LCD 屏幕提供了更好的分辨率和更高的像素。现在,4K 显示器开始慢慢普及,但我不知道是不是有机会看到延迟方面的改进。
本文翻译疑惑授权,原文链接:
https://danluu.com/input-lag/






