ICML2018强化学习部分总结(1)
最近由于个人比较忙的原因,文章更新速度有点慢,还望大家谅解!今天主要分享一下前沿动态,不更新算法讲解!
人工智能的发展方向,基本可以从每年顶会(ICML, NPIS, CVPR)上可以看出,今年ICML于7月10号在著名的瑞典斯德哥尔摩举行,说起斯德哥尔摩,唯一能让我想起的就是"斯德哥尔摩综合征",自行google. 下面进入主题.
本文是根据David Abel 的笔进行整理,原英文见文末引用, ICML中关于RL的内容在第2,3,4,6天,
(1)基于模型的RL救援(Model-Based RL To The Rescue)
主要思路:收集一些模拟数据,应该有
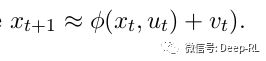
一个想法是通过监督学习来适应动态:
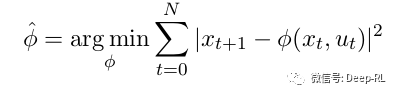
然后,解决近似问题,与LQR相同,但使用φ作为模型。
这里的难点是我们解决的控制问题是什么? 我们知道我们的模型并不完美。 从而
我们需要像Robust Control / Coarse-ID控制这样的东西。
在Coarse-ID控制中:
• 解决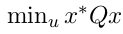
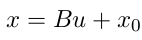
• 然后,收集数据:
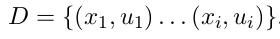
• 估计B:
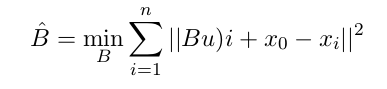
• 估计
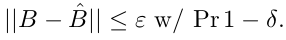
然后,我们可以将其转换为强大的优化问题:
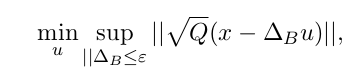
受x = Bu + x0的影响。 然后我们可以通过三角不等式将其放宽到一个凸问题:
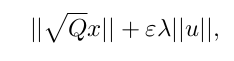
受同样的约束。 他们展示了如何将估计误差转换为LQR系统中的控制误差 - 有点像来自Yields基于稳健模型的控制的模拟引理:显示了一些实验结果,一直很好(肯定比无模型更好)。
回归线性化原则:现在,当我们消除线性时会发生什么?(QR?)。 他们尝试在MuJocoo上运行随机搜索算法,并发现它做得更好(或至少同样好)的自然灰度法和TRPO。 Bens'提出的前进方向:使用模型。 特别是模型预测控制(MPC):
想法:计划在短时间内,获得反馈,重新计划。
结论和剩下要做的事情:
• 粗ID结果是否最佳? 甚至w.r.t. 问题参数?
• 我们能否针对各种控制问题获得紧张和较低的样本复杂性?
• 自适应和迭代学习控制
• 非线性模型,约束和不正确的学习。
• 安全探索,了解不确定的环境。
所以,有很多令人兴奋的事情要做! 而且不只是RL而不仅仅是控制理论。 也许我们需要一个更具包容性的新名称,如“Actionable Intelligence”。 所以,得出结论:

本部分完,
这是原作者英文版,地址:https://pan.baidu.com/s/1R8LtR262FKoHOSrXTj4f2Q,密码:jz9z
顺便问一下,谁知道公众号怎么输入公式,不能输入公式太烦了,麻烦请私信!




