ICLR 2018 | 深度可逆网络i-RevNet:信息丢弃不是泛化的必要条件
选自openreview
作者:Jörn-Henrik Jacobsen
机器之心编译
参与:Nurhachu Null、刘晓坤
本文介绍了一种可逆网络架构 i-RevNet,证明对于分类网络的泛化能力,通过信息丢弃构造信息瓶颈并不是必要条件,该结论甚至对 ImageNet 这样的大型数据集也是成立的;此外,通过保留中间表征的所有信息,使得逆向完全地恢复原图变得可行。
虽然卷积神经网络(CNN)在进行图像分类的时候特别有效(He et al., 2016; Krizhevsky et al., 2012),但是非线性算子和线性算子的级联在揭示内部表征对分类的贡献方面却是很有限的。学习过程的主要特点是能够稳定地减少图片中大量的无信息可变性(uninformative variability),同时揭示图像类别的本质特征。普遍认为这个过程是基于逐步丢弃与问题输入相对应的无信息可变性 (Dosovitskiy & Brox, 2016; Mahendran & Vedaldi, 2016; Shwartz-Ziv & Tishby, 2017; Achille & Soatto, 2017)。然而,关于抛弃信息的程度信息在某些中间非线性过程中丢失了。在这篇论文中,研究者通过提出一种可逆卷积神经网络来提供关于可变性减少过程的一些洞见,这个可逆卷积神经网络不会损失关于输入的任何信息。
很多常用的网络结构都面临着从隐藏表征中恢复图片的困难 (Dosovitskiy & Brox, 2016; Mahendran & Vedaldi, 2016)。这引发了一个问题:在成功的分类模型中,大量的信息损失是否必要。本文将证明,没有信息是必须被丢弃的。通过使用同胚层(homeomorphic layers),不变性可以仅仅在最后一层通过投影的方式建立。
Shwartz-Ziv 和 Tishby 的研究中(2017)建议采用最少而充足的统计量来解释可变性的减少。Tishby 和 Zaslavsky2015 年的研究介绍了信息瓶颈原则——为了尽可能多地减少无信息可变性,一个最优的表征必须减少输入与其表征之间的互信息。同时,为了有效地防止一个类别被混淆到其他类别,网络还应该最大化表征与其期望输出之间的互信息。Shwartz-Ziv & Tishby (2017) 和 Achille & Soatto (2017) 基于一些小数据集阐述了信息瓶颈效应。然而,本文将证明,这并不是一个必要条件,而且通过构建级联的同胚层,可以保留输入和隐藏表征之间的互信息,并且证明信息损失可以仅仅发生在最后一层。以此,我们可以证明,在诸如 ImageNet 这样的大规模数据集上也可以避免信息损失的问题。
减少可变性的一种方式就是逐步地收缩中间表征的 L2 范数对应的可变性。
有几项研究已经注意到了在有限数据集上训练的非可逆网络存在逐步分离和收缩的现象 (Oyallon, 2017; Zeiler & Fergus, 2014)。这种逐步提升性能的现象可以被解释为逐步增强不变性,以改善分类结果。理想情况下,这种收缩不应该太暴力,以避免从中间信号中移除重要信息。这证明区分度和不变性之间的权衡必须逐步建立。在这篇论文中,作者将 Zeiler & Fergus (2014) 和 Oyallon (2017) 的工作扩展到了 ImageNet (Russakovsky et al., 2015) 上,并且最重要的是,他们证明了在逐步收缩的过程中,信息损失是可以避免的。
Mallat (2016) 讨论了不同类别的不变性和区分度之间的二重性。这里用李群为类内部可变性建模,类内部可变性可以通过在这些对称性中执行并行传递来处理。在学习过程中可以将卷积核适应到数据集的特定偏差上,进而可以避免沿着可区分方向的收缩。然而,使用不属于欧几里得范畴的群进行图像分类是很困难的。主要原因是与这些抽象可变性相关的群是难以评估的,因为它们具有高维度的属性以及需要合适自由度的不变性。Mallat(2012) 通过散射变换给出了这个框架在欧氏群上的一个描述,它在一定程度可恢复的同时建立了小幅度转译的不变性。在这篇论文中,作者引入了一个网络结构,它不会在除最后一层的其他地方丢弃任何信息,同时他们还定量地展示了信号类别中的渐进收缩和分离。
研究者引入了 i-RevNet,这是一种可逆的深度网络,i-RevNets 在除最后一层的所有中间表征中保留了输入信号的所有信息。该架构架构是基于最近提出的 RevNet(Gomez et al., 2017) 建立的,用可逆组件代替了原始 RevNets 结构中的非可逆组件,i-RevNet 在 ImageNet 上达到了与非可逆 RevNet 和 ResNet 相同的性能 (Gomez et al., 2017; He et al., 2016)。在这个架构中,本文证明:在学习可以泛化到陌生数据的表征时,信息损失并不是必要条件。
为了揭示学习表征泛化能力的机制,作者证明了 i-RevNets 随着深度的增加会逐渐分离和收缩信号。结果表明:通过使用对可恢复输入进行收缩,可以有效地减少可变性。
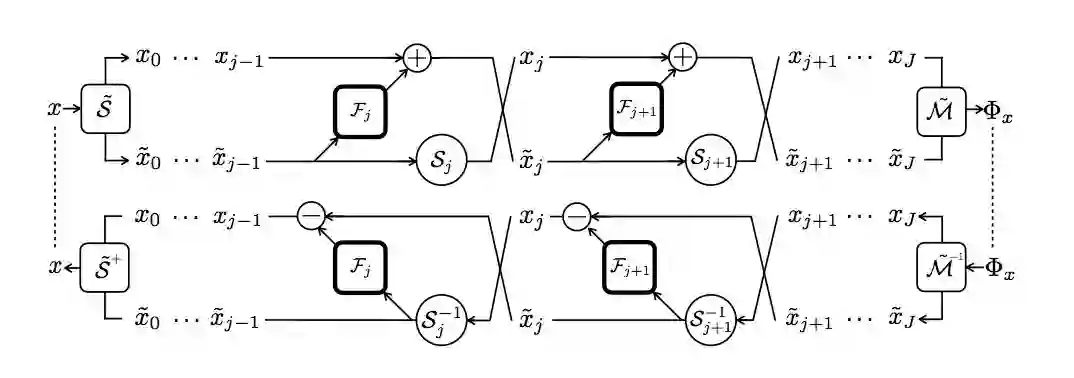
图 1: i-RevNet 和它的逆网络的主要组成。RevNet 模块与卷积瓶颈 F_j 交替连接,并且对 S_j 运算进行洗牌,以保证架构的可逆性和计算效率。输入通过分割算子 S˜进行处理,输出结果通过 M˜处理进行合并,注意,逆网络是通过最小适应(minimal adaptations)获得的。
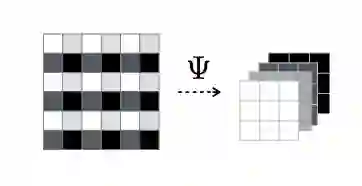
图 2:可逆下采样的图示

表 1:在 ILSVRC-2012 上训练的几个不同架构的对比:包括分类准确率和参数数量
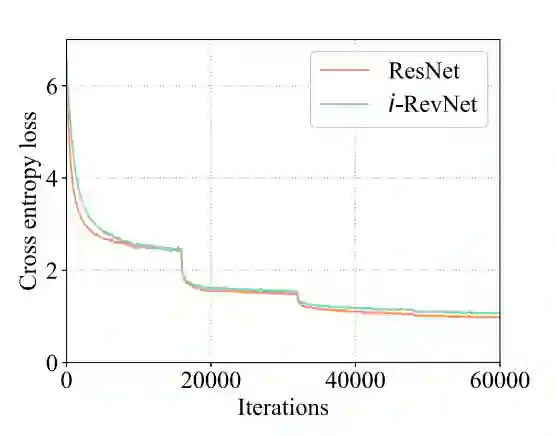
图 3:在 ImageNet 上 i-RevNet (b) 和 ResNet 的训练损失对比。
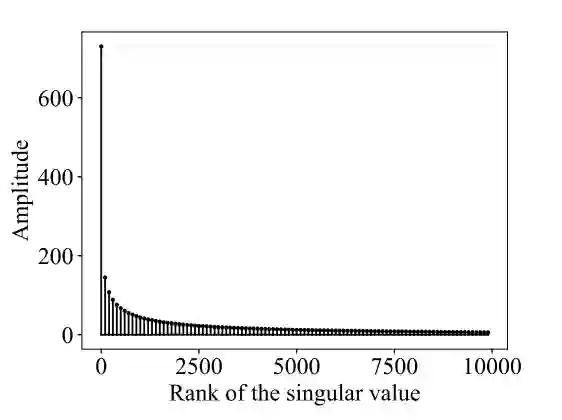
图 4:∂φ_x 的归一化排序奇异值

图 5:这幅图展示了几个重建序列 {x^t }_t。左边的图对应 x^0,右边的图对应 x^1。

图 6:应用到空间平均Φ_j 上时,深度为 j 的线性 SVM 和 1-最近邻分类器的准确率
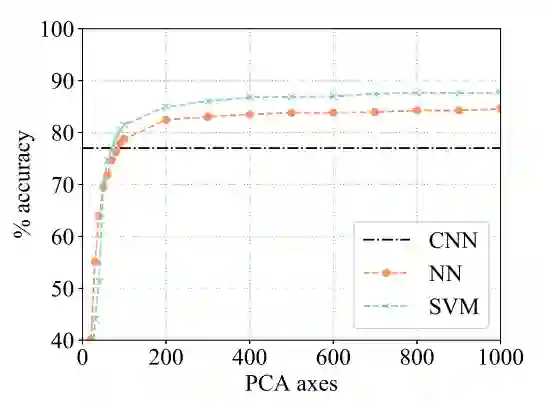
图 7:线性 SVM 和最近邻在保留不同维度的主成分时的准确率
论文:i-RevNet:深度可逆网络(i-RevNet: Deep Invertible Networks)

论文链接:https://openreview.net/forum?id=HJsjkMb0Z
普遍认为,卷积神经网络的成功是基于对问题输入的无信息可变性的逐渐丢弃。在绝大多数常见的网络架构中,难以从图像的隐藏表征恢复图像,经验地支撑了上述观点。我们在这篇论文中证明了这种信息丢失不是泛化到复杂问题 (如 ImageNet ) 上的必要条件。通过使用级联同胚层,我们建立了 i-RevNet,这是一个可以完全倒转到类别的最终投影上的网络,也就是说,不会丢弃任何信息。建立一个可逆架构是很困难的,因为局部可逆是病态的,我们通过一种显式的逆向过程克服了这个问题。通过对 i-RevNet 学习到的表征的分析,我们提出了一种通过渐进收缩和按深度的线性分离来解释良好准确率的方法。为了揭示 i- RevNet 学习模型的性质,我们重构了自然图像表征之间的线性插值。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



