如何用R语言做词云图,以某部网络小说为例

作者:horo R语言中文社区专栏作者
知乎ID:
https://www.zhihu.com/people/lin-jia-chuan
前言
一开始,我在学做词云图时,逛了不少论坛和博客,虽然他们都说的好像很简单的样子,但总觉得自己还是不会做(现在也是)。之所以不会主要是不知道它的原理是什么,所以这里写一下经验,避免后面的人掉坑。
首先我们要知道,R语言做词云图,是用wordcloud或是wordcloud2制作的,所以要先安装好任意一个。这里先全部安装,并导入目录当中:
install.packages("wordcloud")
install.packages("wordcloud2")
library(wordcloud)
library(wordcloud2)wordcloud的基本输入格式如下,其他的暂时没用到先不管,需要时再百度
wordcloud(words=词向量,freq=词频向量,
min.freq=n,max.words=m,random.order=TRUE/FALSE)先看了一下这个词向量和词频向量指什么意思,以下面的文件为例,一本相对热门的网络小说的文件,已经处理好的了。
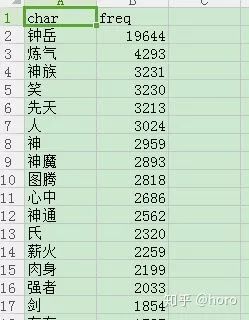
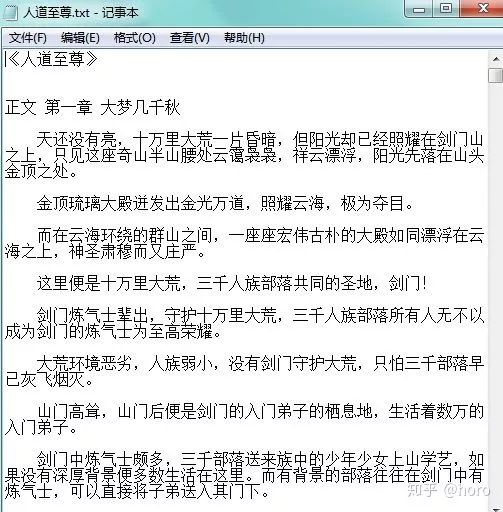
由此可知,wordcloud最最主要需要的就是这么两个变量,一个是分好的词,一个是词的频率,wordcloud2也是如此,但是在日常中我们并没有直接分好的文件,而是一大堆混杂在一起的字符数字或是无意义的符号,所以我们要做词云图,关键是要做如下几步,一是把词给分好,第二是将文件的的词的频率计算出来,三是将无意义的符号给去除掉。拿人道至尊这部小说为例。
第一步涉及到自然语言处理的知识,这里暂且不表,相关论文可自己去看,R里面有不少包可以用来分词,主要有Rwordseg(这个包已经不适用最新版本了,不过用的人太多了容易找到教程)还有jiebaR这个包,jiebaR这个包与jiebaRD这个包是配套的,所以请一同下载,如果出错,估计是配置环境没有弄好,如JAVA什么的,直接下载或百度即可。
我们这里主要是用jieba包进行分词的,所以输入下列程序:
install.packages("jiebaR")
install.packages("jiebaRD")
library(jiebaRD)
library(jiebaR)
jiebaR包里有一个叫segment的函数,它可以用来分词,主要的输入格式如下:
segment(code,jieba)code是文件的内容,jieba是用来分词的工具,我们首先设置下分词的工具,输入:
engine = worker() 然后把文件也写进去:
segment("人道至尊.txt",engine)这时它就会反馈给你一个新的,已经分好的txt文件,直接将那个文件导入到R中即可。输入:
word <- scan('人道至尊.segment.2018-12-06_18_38_22.txt',sep='\n',what='',encoding="UTF-8") 导入好了之后就可以进行下一步,计算词频了,这里我直接输入:
word <- qseg[word]
word <- freq(word)然后就可以得到下列结果:
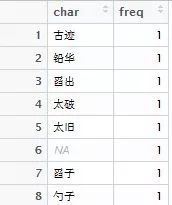
可以看到制作词云图的两个关键参数已经满足了,接下来就可以直接制作了。如下面所写的书写格式,可输入下列程序:
wordcloud(word$char,word$freq,min.freq = 1000,scale=c(8,0.5),colors=colors,random.order=F)值得注意的是,我这里的min.freq选择了一千,指的是我只要词频大于一千的词,原因是小说的分词太多,词频设置的太少会突出不了重点,不利于之后分析。故得到了下列图:

这时我们就可以看到有一些词是没有意义的,比如说“的”,“它”,“你”等等,通常人们叫它停词,所以我们应当把这些无意义的词去掉,通常人们解决这种问题的手段,是通过手动增加停词的文件,或是引用其他人已经做好的停词文件。我这里则是直接通过Excel解决的,因为这里的停词是清晰可见的,而且数量较少,备份一下,然后手动删除,利用vlookup函数或是排序后,手动删除(条条大路通罗马,才不会告诉你我不会用停词表呢,哼)。
所以先将上述的词频文件word导出成excel文件,输入下列语句:
write.csv(word, file = "人道至尊分词.csv")处理好了效果如下:
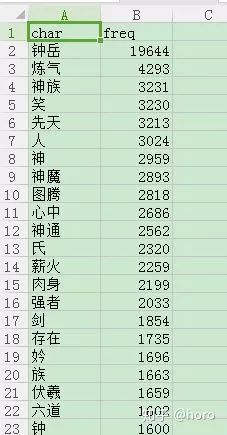
再将文件重新导入回去:
word2 <-read.csv(file = "人道至尊分词.csv")好了,接下来可以重新制作了,因为删掉一些无意义的词,所以min.freq可以放宽一点,设置为500,输入语句如下:
wordcloud(word2$char,word2$freq,min.freq = 500,scale=c(8,0.5),colors=colors,random.order=F)得到效果如下:

这下效果就不错了,wordcloud就先到这里,接下来介绍wordcloud2。
为什么要用wordcloud2包,因为它做出来的图更好看,而且在词云图中可以看到每一个词的频率,它的基本输入格式如下。当然有更强大的参数没有列出来,详情请百度wordcloud2参数。
wordcloud2(file,color = 颜色, backgroundColor = 颜色,shape='形状')file指的是词的文件,注意,由于wordcloud2不像wordcloud那样,可以设置最低词频,所以所有的词都会一股脑的塞进入词云之中,这样词量过大会造成词云图很难看,所以要事先做处理(这里我不是很确定,也许有可以直接设置的劳烦大神告知),我这里将词频高于300的都挑出来了,输入下列程序:
word3 <- word2[1:300,]然后开始制作:
wordcloud2(word3,color = "random-light", backgroundColor = "grey")得到下列结果:

我们可以选择不同的形状,如默认是‘circle’(圆形),‘cardioid’(苹果形或心形),‘star’(星形),‘diamond’(钻石),‘triangle-forward’(三角形),‘triangle’(三角形),‘pentagon’(五边形);输入下列程序:
wordcloud2(word3,color = "random-light", backgroundColor = "grey",shape='star')结果得:

当然看起来一般般,不过wordcloud2还可以自己选择图片去制作,比如说小鸟图片,人物图片什么的,暂且不表,可以参考原文档或直接百度。


公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
登录查看更多
相关内容
Arxiv
11+阅读 · 2019年6月9日
Arxiv
11+阅读 · 2018年7月12日
Arxiv
5+阅读 · 2018年4月3日





相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2019年6月9日
Arxiv
11+阅读 · 2018年7月12日
Arxiv
5+阅读 · 2018年4月3日