参考资料
[1] Fiaz, Mustansar, et al. "Handcrafted and deep trackers: Recent visual object tracking approaches and trends." ACM Computing Surveys (CSUR) 52.2 (2019): 1-44.
[2] Wu, Yi, Jongwoo Lim, and Ming-Hsuan Yang. "Object tracking benchmark." IEEE Transactions on Pattern Analysis and Machine Intelligence 37.9 (2015): 1834-1848.
[3] VOT2018 dataset, http://www.votchallenge.net/vot2018/dataset.html.
[4] Wang, Naiyan, et al. "Understanding and diagnosing visual tracking systems." Proceedings of the IEEE international conference on computer vision. 2015.
[5] Yilmaz, Alper, Omar Javed, and Mubarak Shah. "Object tracking: A survey." ACM computing surveys (CSUR) 38.4 (2006): 13-es.
[6] Henriques, João F., et al. "High-speed tracking with kernelized correlation filters." IEEE transactions on pattern analysis and machine intelligence 37.3 (2014): 583-596.
[7] Gonzalez, Rafael C., Richard E. Woods, and Steven L. Eddins. Digital image processing using MATLAB. Pearson Education India, 2004.
[8] Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. Deep learning. MIT Press, 2016.
[9] Li, Xi, et al. "A survey of appearance models in visual object tracking." ACM transactions on Intelligent Systems and Technology (TIST) 4.4 (2013): 1-48.
[10] Ross, David A., et al. "Incremental learning for robust visual tracking." International journal of computer vision 77.1-3 (2008): 125-141.
[11] Jia, Xu, Huchuan Lu, and Ming-Hsuan Yang. "Visual tracking via adaptive structural local sparse appearance model." 2012 IEEE Conference on computer vision and pattern recognition. IEEE, 2012.
[12] Pérez, Patrick, et al. "Color-based probabilistic tracking." European Conference on Computer Vision. Springer, Berlin, Heidelberg, 2002.
[13] Adam, Amit, Ehud Rivlin, and Ilan Shimshoni. "Robust fragments-based tracking using the integral histogram." 2006 IEEE Computer society conference on computer vision and pattern recognition (CVPR'06). Vol. 1. IEEE, 2006.
[14] Comaniciu, Dorin, Visvanathan Ramesh, and Peter Meer. "Kernel-based object tracking." IEEE Transactions on pattern analysis and machine intelligence 25.5 (2003): 564-577.
[15] Hare, Sam, et al. "Struck: Structured output tracking with kernels." IEEE transactions on pattern analysis and machine intelligence 38.10 (2015): 2096-2109.
[16] Kalal, Zdenek, Krystian Mikolajczyk, and Jiri Matas. "Tracking-learning-detection." IEEE transactions on pattern analysis and machine intelligence 34.7 (2011): 1409-1422.
[17] https://github.com/foolwood/benchmark_results.
[18] Mueller, Matthias, Neil Smith, and Bernard Ghanem. "A benchmark and simulator for uav tracking." European conference on computer vision. Springer, Cham, 2016.
[19] Huang, Lianghua, Xin Zhao, and Kaiqi Huang. "Got-10k: A large high-diversity benchmark for generic object tracking in the wild." IEEE Transactions on Pattern Analysis and Machine Intelligence (2019).
[20] Russakovsky, Olga, et al. "Imagenet large scale visual recognition challenge." International journal of computer vision 115.3 (2015): 211-252.
[21] Lin, Tsung-Yi, et al. "Microsoft coco: Common objects in context." European conference on computer vision. Springer, Cham, 2014.


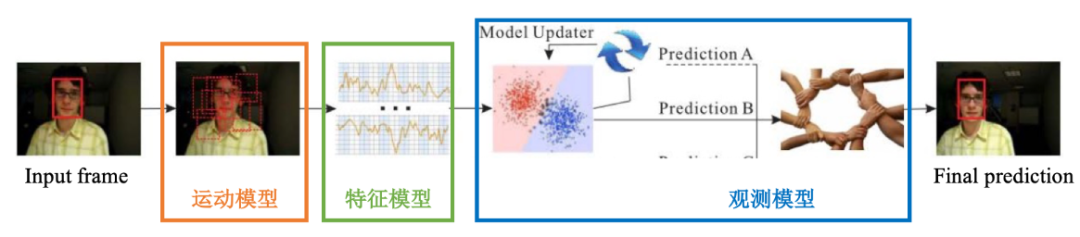
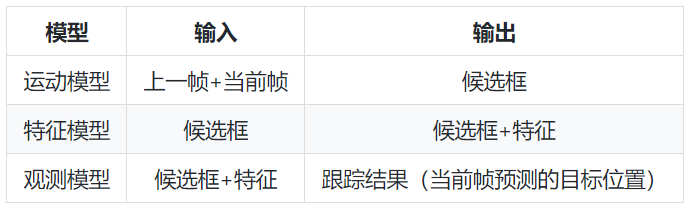
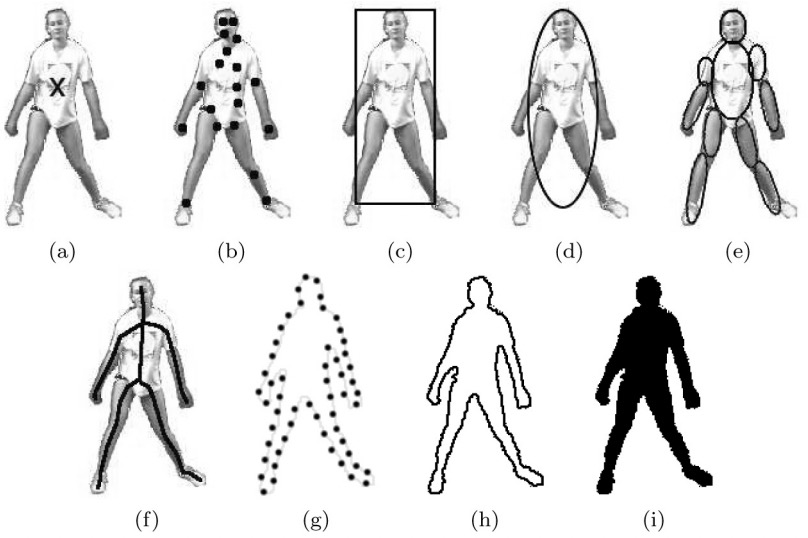
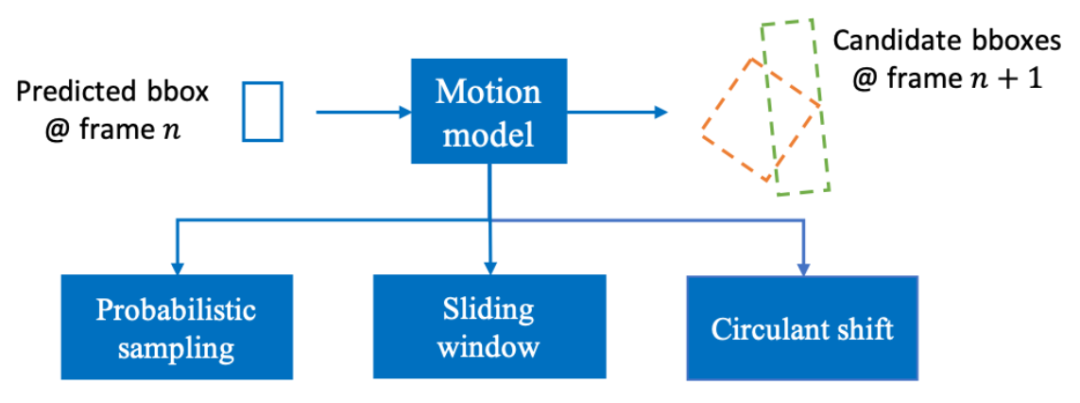
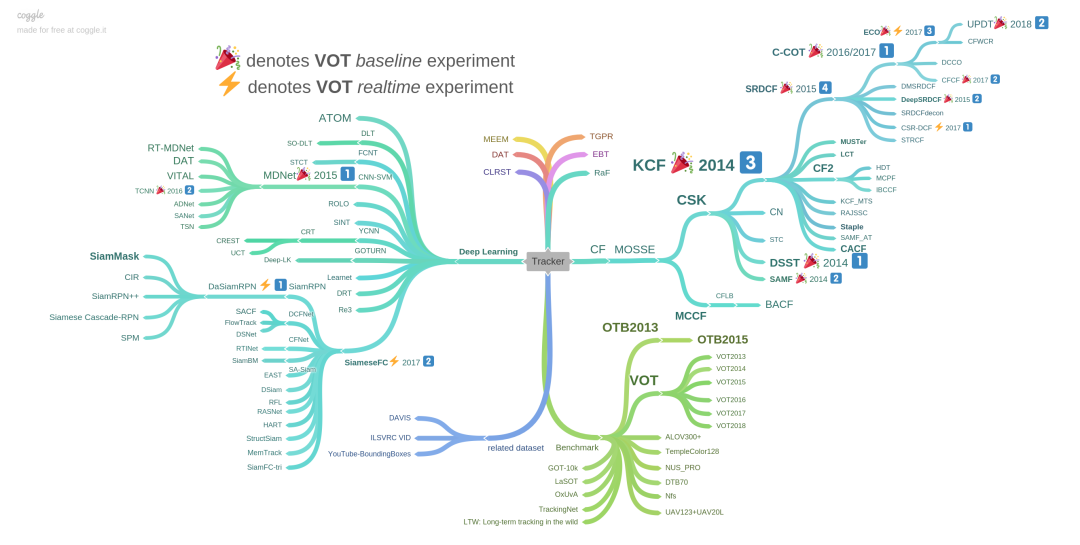

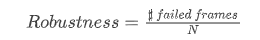
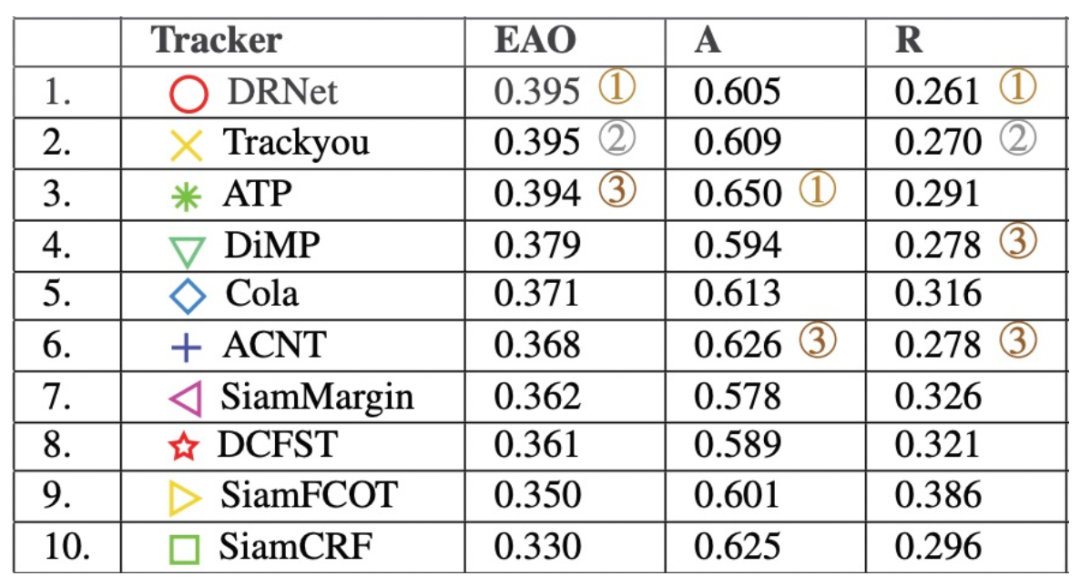 表 3. VOT challenge 2019结果节选
表 3. VOT challenge 2019结果节选





