昨天在华为开发者大会上,华为首席科学家陈雷发布的全场景AI计算框架MindSpore开源框架,引起业界广泛关注,毕竟在短短一周之内,国内相继涌现出计图(Jittor,清华)、天元(MegEngine,旷视)、MindSpore(华为)三个深度学习开源框架,可谓“2020年是深度学习框架井喷的一年”。
但在昨天的大会中,华为发布的另一项重要计划却似乎受到了忽视,这是由田奇博士主导的 “
华为计算视觉基础研究进展暨华为视觉计划发布
” 。
田奇博士,计算机视觉领域的人士应该都不陌生,毕业于清华电工系,后赴伊利诺伊大学香槟分校,师从计算视觉之父 Thomas S.Huang 教授。在2018年加入华为之前,一直在德克萨斯大学圣安东尼奥分校任教,是2016年多媒体领域 10 大最具影响力的学者,并于当年入选IEEE Fellow。
田奇博士加入之后,华为诺亚方舟在计算机视觉领域的研究突飞猛进。以论文来讲,ICCV 2019、CVPR 2019 分别有 19篇和29篇入选论文,CVPR 2020上更是多达 33 篇,且不论他们在类似ICLR、ICML这类篇算法的顶会上发表的论文。
在这次“研究进展&计划发布”上,田奇博士将他们的研究内容梳理为三大方向,即
数据:如何从数据中挖掘有效信息?
模型:怎样设计高效的视觉识别模型?
知识:如何表达并存储知识?
在此基础上,他提出了华为诺亚的六大视觉计划:
数据冰山计划
、
数据魔方计划
、
模型摸高计划
、
模型瘦身计划
、
万物预视计划
、
虚实合一计划
。
每个计划听着都很带感,其中逻辑是什么?
各自代表了什么
?
田奇博士在演讲中,将当下计算机视觉面临的挑战分为三大方向,分别为数据、模型和知识表达。(为什么没有算力?毕竟这不是做视觉的人所能决定的,对算力的考虑其实包含在模型里面)
在信息时代,做计算机视觉其实面临一个尴尬的事情,即互联网上存在着海量的视觉数据,甚至已经远远超过了人类处理的极限;标注数据,无论规模多大,都只是视觉大数据中的“沧海一粟”。如何从海量数据中挖掘出有效的信息,依旧是一个很大的挑战。
华为在这方面提出了两个典型的场景,一是如何利用生成数据训练模型;二是如何对齐多模态数据。
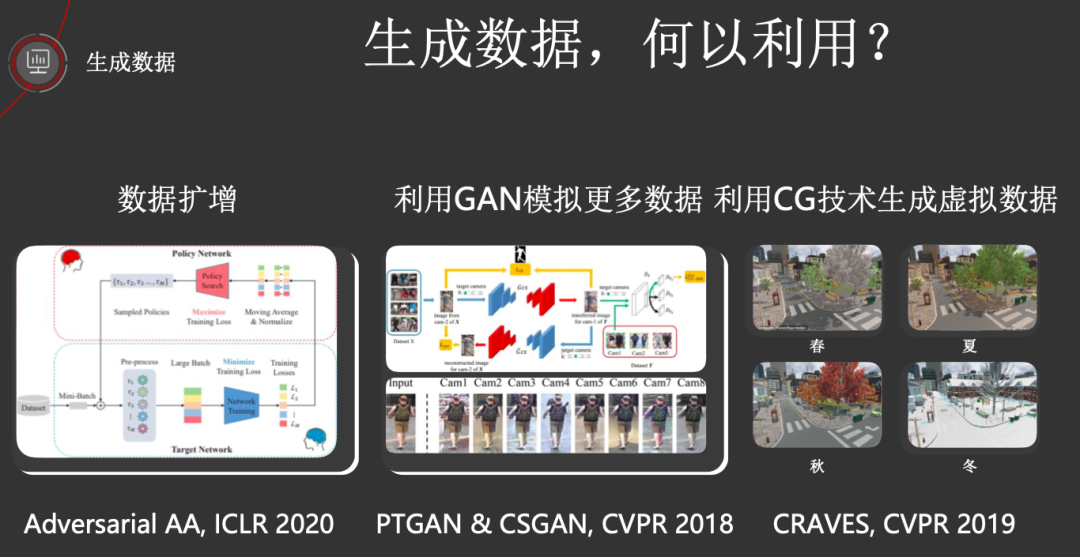
首先是生成数据,华为在这方面投入了大量的研究。具体来说,分为三部分。
第一,自动数据扩充。
这个以发表在ICLR 2020 上的 「Adversarial AutoAugment」为代表,这篇文章针对以前NAS(例如 AutoAugment)做数据增强计算开销大、policy是静态的问题,借用 GAN 的“对抗”思想,引入了 adversarial loss,这样一方面大大减少了训练所需的时间;另一方面,可以认为policy generator 在不断产生难样本,从而能帮助分类器学到 robust features,从而学的更好。(ICLR 2020 | 巧妙思想,NAS与「对抗」结合,速率提高11倍 )
第二,利用GAN来模拟更多的数据。
这个以发表在CVPR 2018 上的PTGAN 和 CSGAN 为代表。前者(「Person Transfer GAN to Bridge Domain Gap for Person Re-Identification」)是针对行人重识别问题的生成对抗网络,使用GAN将一个数据集的行人迁移到另一个数据集当中。后者(「Compressed sensing using generative models」)是针对感知的GAN压缩,换句话来说,即利用GAN来重构出“原始数据”,相比于其他的重构算法来讲,CSGAN在更少的测量(可理解为采样后的数据)情况下能够重构出很好的原始数据。
第三,利用计算机图形学技术来生成虚拟数据。
这个以发表在CVPR 2019 上的「CRAVES: Controlling Robotic Arm with a Vision-based, Economic System」为代表。在CRAVES这篇工作中,他们设计了一套基于虚拟数据生成和域迁移的训练流程,机械臂只需要借助一个额外的摄像头,便可以完成抓取骰子并放置在指定位置的任务。注意,这里的数据是基于CG技术生成的,对机械臂的训练完全不需要提供额外的监督数据。
田奇也介绍了他们在数据生成方面最近的一项工作,这是一项
基于知识蒸馏与自动数据扩增结合的方法
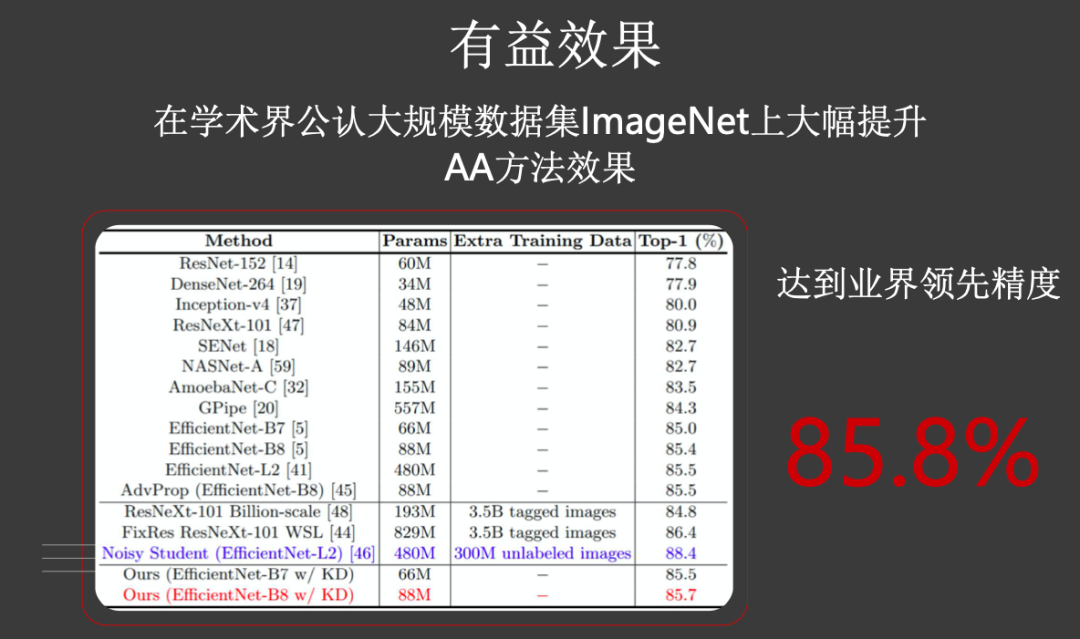
。我们知道,自动数据扩充(AutoAugment,以下简写为 AA)来源于对数据集的全局优化。对每个图片,AA可能带来图像语义的混淆。
如左边的图所示,原图是一只狐狸;如果对它进行亮度变化,它看起来会更像一只狗;如果对它进行反转,这个时候看起来像一只猫。因此在训练模型的时候,如果仍然使用原来的硬标签(“fox”)显然是不合适的。
为了解决这个问题,华为提出了知识蒸馏的办法,通过预训练的模型,对AA的图片,产生软标签,再用软标签指导图形的训练。上图便是知识蒸馏后产生的软标签。
从结果上来看,这种知识蒸馏与自动数据扩增相结合的方法,在ImageNet上能够取得85.8%的效果。
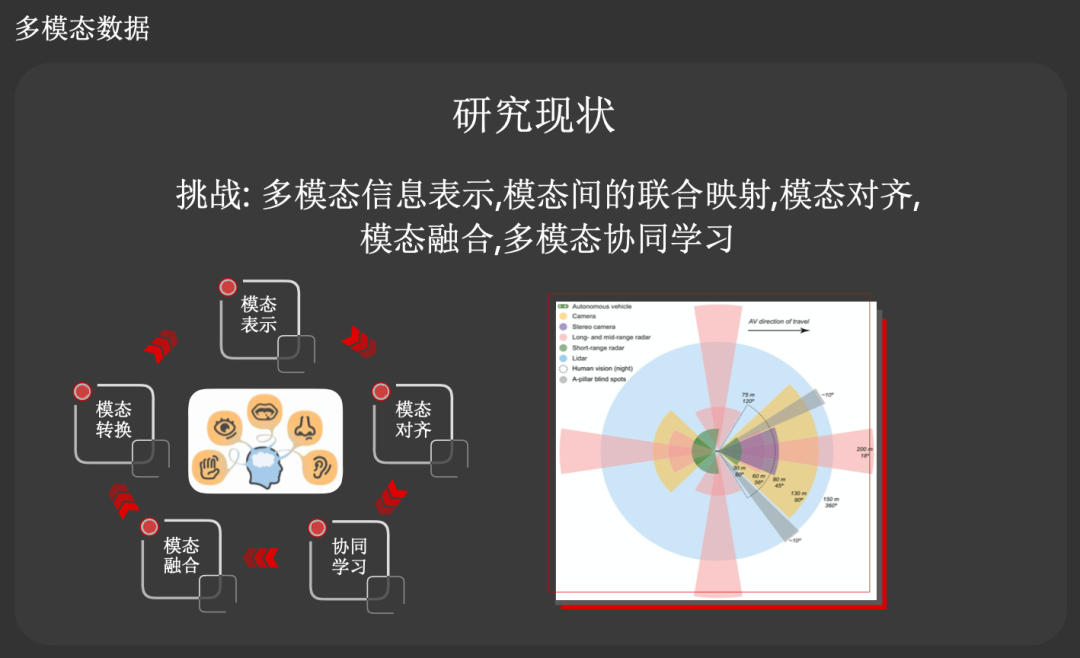
针对第二个场景,多模态数据,田奇博士认为
多模态学习将成为未来计算机视觉领域的主流学习模式
,因此非常重要,他们也将在这个领域进行重点布局。当前多模态学习面临的挑战包括:多模态信息表示,模态间的联合映射,模态对齐,模态融合,多模态协同学习。
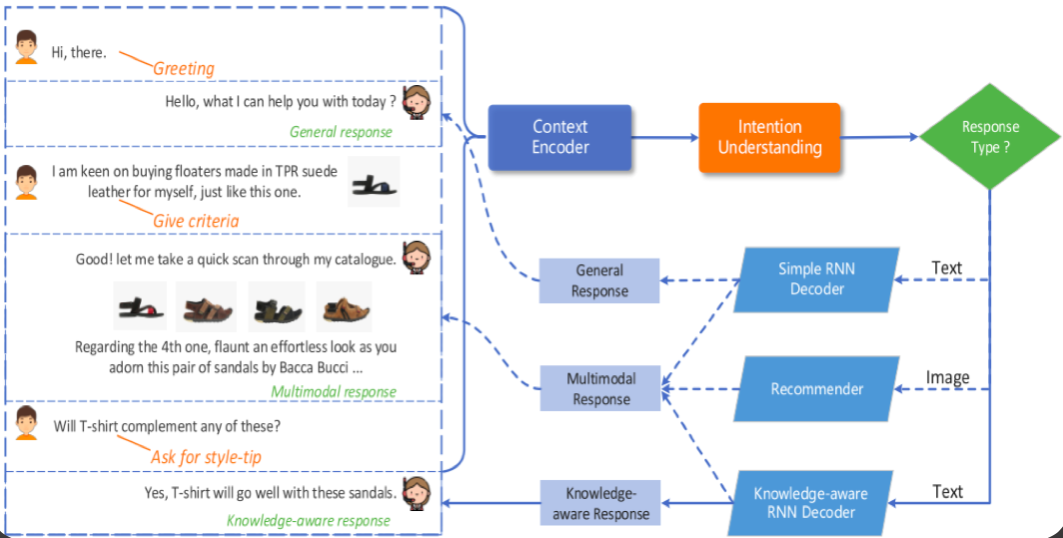
针对这方面的工作,即如何对齐多模态数据,田奇重点介绍了他们在ACM MM 2019 上获得最佳论文提名的论文「Multimodal Dialog System: Generating Responses via Adaptive Decoders」。他们称之为“魔术模型”,论文本身是针对电子商务场景,用户在与机器克服对话过程中存在输入文本或图片的需求。他们针对这一问题,使用了一个统一的模型来编码不同模态的信息,从而能够根据上下文来反馈文字或图片。
田奇博士提出,华为诺亚在视觉模型方面的主要研究在于如何设计出高效的神经网络模型以及如何加速/小型化神经网络计算。换句话来说,即
模型如何更快、更小、更高效。
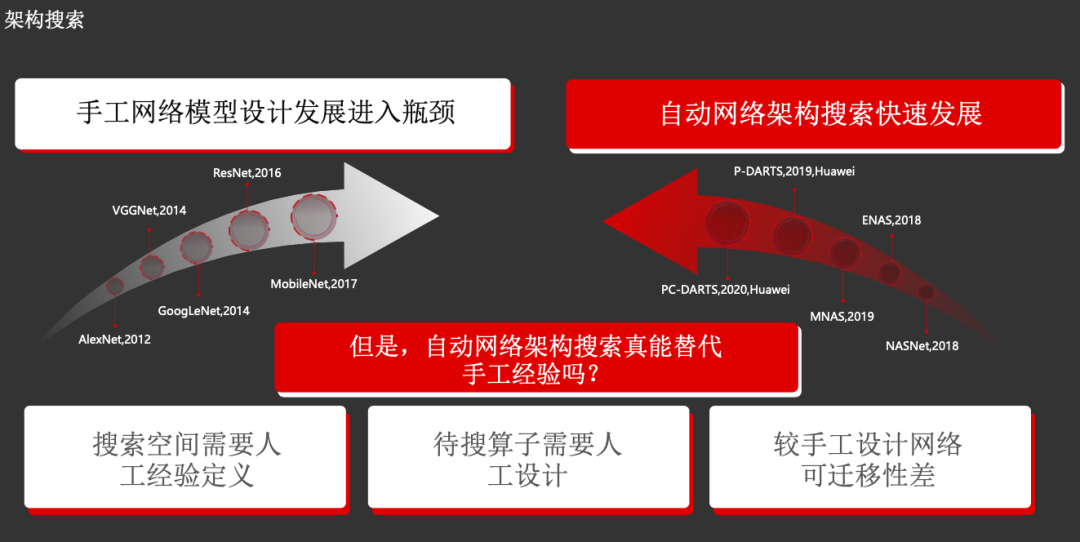
神经网络模型的设计,最初都是手工设计,但现阶段手工网络模型设计已经进入了瓶颈期。而作为对应,从2017年开始,自动网络架构搜索(NAS)迅猛发展,尽管只有三年时间,却已经取得了可喜的进展。
田奇博士认为,NAS目前存在三大挑战,分别为:1)搜索空间仍需人工经验定义;2)待搜算子需要人工设计;3)相较手工设计网络,可迁移性较差。
田奇博士在这方面仅举了他们的一个工作,发表在ICLR 2020 上的「PC-DARTS: Partial Channel Connections for Memory-Efficient Architecture Search」。PC-DARTS针对现有DARTS模型训练时需要 large memory and computing 问题,提出了局部连接和边正则化的技术,分别解决了网络冗余问题和局部连接带来的不稳定性。这个模型能够在性能无损的情况下,做到更快(与同类相比快一倍)。
针对如何加速神经网络及模型小型化,田奇博士是这样思考的。目前大的网络模型发展如火如荼,但这样的模型更适合配置在云侧,而无法适配端侧。从2016年起,业界便开始探索模型加速和小型化的研究,也提出了大量小型化方案。但这些方案在实际中面临着诸多问题,包括:1)低比特量化使得精度受限;2)混合比特网络对硬件却并不友好;3)新型算子并没有得到充分的验证。
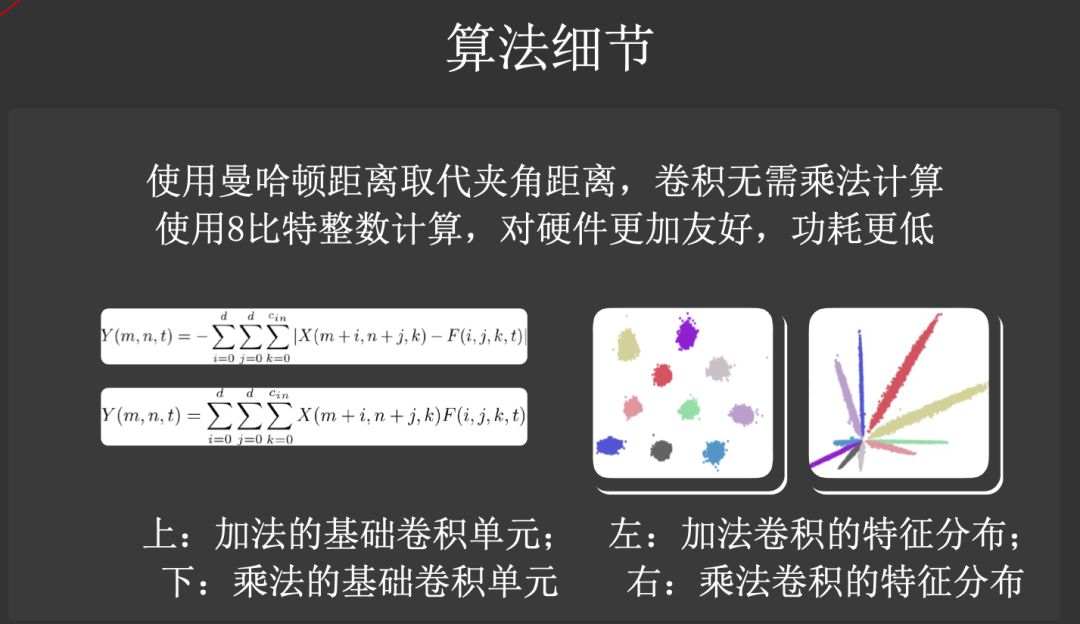
田奇博士同样举了他们最近的一项工作,是CVPR 2020 上的一篇 Oral:「AdderNet: Do We Really Need Multiplications in Deep Learning?」。在计算机中,浮点运算复杂度相比加法要高很多,但神经网络中存在大量的乘法运算,这就限制了模型在移动设备上大规模使用的可能性。那么是否能设计一种基于加法的网络呢?华为的这篇文章正是对这一问题的回答,他们将卷积网络中的乘法规则变成加法,并对网络中的多种规则进行修改:1)使用曼哈顿距离(取代夹角距离)作为各层卷积核与输入特征之间输出的计算方法;2)为AdderNet设计了一种改进的带正则梯度的反向传播算法;3)提出一种针对神经网络每一层数量级不同的适应性学习率调整策略。实验结果上表明,AdderNet能够取得媲美于乘法网络的效果,且在计算功耗上具有明显的优势。
田奇表示,华为的目标是打造下一代视觉感知的通用视觉模型,并把该算法迁移到下游任务进行模型复用。
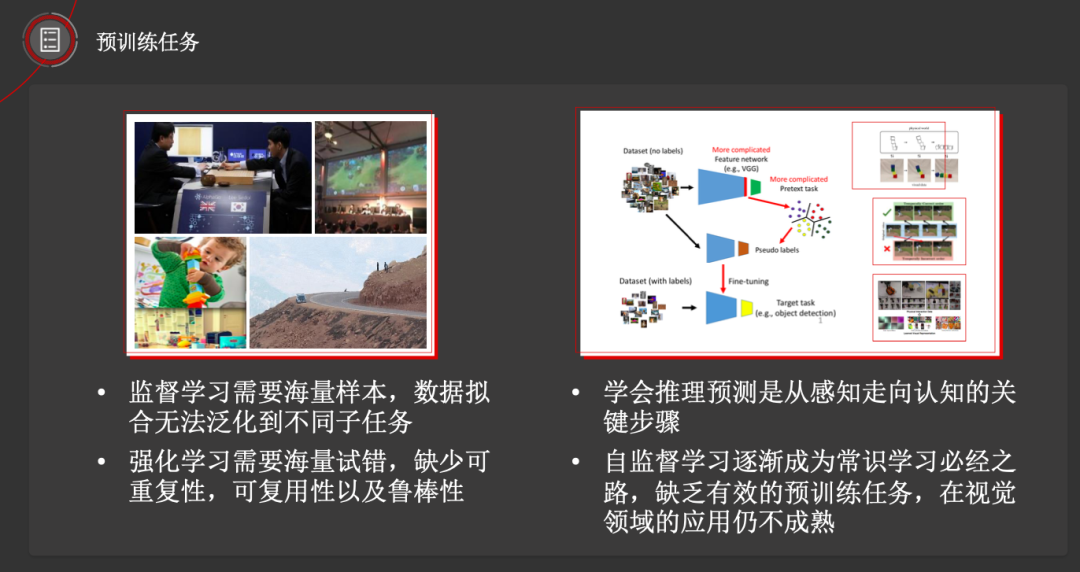
那么,何为“通用视觉模型”?其核心思想事实上就是如何表达并存储知识。
田奇博士提出两种场景。首先是目前比较热的预训练的方式,通过预训练获得的模型来表达和存储知识;其次是通过虚拟环境,在基本不需要标注数据的情况下来学习知识。
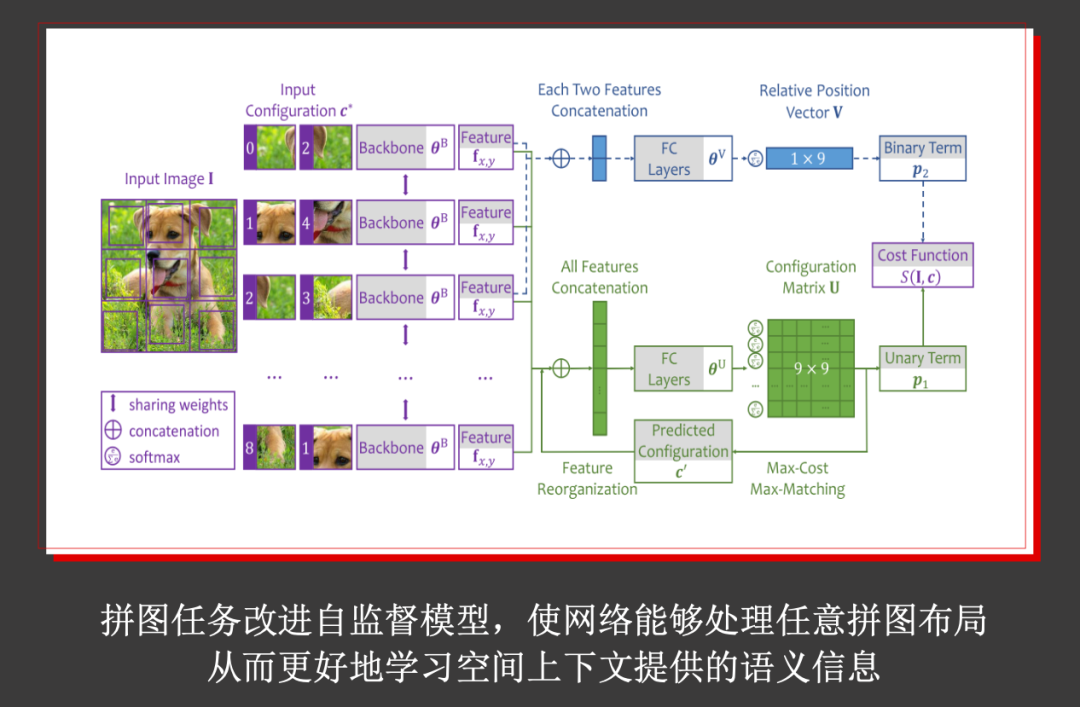
针对预训练模型,田奇博士提到了他们在CVPR 2019上发表的工作:「Iterative Reorganization with Weak Spatial Constraints: Solving Arbitrary Jigsaw Puzzles for Unsupervised Representation Learning」。这篇文章提出了一种适用于处理任意维度拼图问题的自监督学习方法。
拼图问题将无标签图像按网格分割为图像块,并打乱它们的顺序,通过网络恢复正确的图像块布局,来达到从无标签图像数据中学习语义信息的目的。这篇文章提出,以迭代的方式逐步调整图像块的顺序直到收敛。在ImageNet上能够取得非常好的性能。
深度学习大量依赖于可标注的数据,但是很多场景下,数据标注成本很高。同时,标注数据也存在一个致命的问题,即知识表达不准确——比如在自动驾驶中,我们有大量的标注信息,但这些标注数据是否真的“最适合”自动驾驶任务呢?此外,人类对外界的感知依赖于常识,而依赖于标注数据来训练的模型则存在缺乏常识的问题。
针对这一问题,田奇博士提出了用虚拟场景构建虚拟场景来学习常识的方法。田奇博士举了他们发表在CVPR 2019 的文章(CRAVES),主要是通过虚拟场景来训练机械臂抓骰子。我们在前面已经提到,这里就不再赘述。
延续以上提到的研究内容,田奇在随后发布了「华为视觉计划」。简单来说包括六个子计划:
与数据相关的:
数据冰山计划
、
数据魔方计划
;
与模型相关的:
模型摸高计划
、
模型瘦身计划
;
与知识相关的:
万物预视计划
、
虚实合一计划
。
该计划是为了解决数据标注瓶颈问题,让数据生成真正代替手工标注。这里包含三个子课题,分别为:
子课题一:
数据生成质量拔高。即通过一到两年时间,解决生成数据质量差和不真实的问题;
子课题二:
数据生成点石成金。即设计数据自动挑选的算法,在海量的生成数据中,挑选高质量的数据;
子课题三:
通用自动数据生成。即对不同的子任务设计不同的生成数据方式,让数据生成具备普惠能力。
该计划主要解决多模态数据量化、对齐和融合的问题,从而构建下一代智能视觉。包括构建多模态数据量化指标,从而全面评估性能;多模态数据对应策略研究;多模态数据融合方案等。
该计划主要是构建云侧大模型,来刷新各类视觉任务的性能上限。同样包括三个子课题:
子课题一:
全空间网络架构搜索。即突破神经网络架构搜索空间受限的约束,搜索更多的范式、更多网络空间结构的变化,让神经网络架构真正实现自动搜索;
子课题二:
新型算子搜索。即让算子的设计从手工复用到创造新的算子;
子课题三:
搜索模型普适能力的提升。目前搜索出的网络泛化性能、抗攻击性、迁移性都比较差,该子课题希望能够提升网络架构索索的这些性能。
开发端侧小模型,助力各种芯片完成复杂推理,是一个重要的研究方向。华为在这个领域中的目标是,打造高效的端侧视觉计算模型。该计划包含三个子课题:
子课题一:
自动搜索小型化网络。即将硬件的约束融入自动设计中,使得算法能够适配不同的硬件。
子课题二:一比特网络量化。即设计一比特网络,使一比特网络能达到全精度网络的性能,目标是追求极致的性能。
子课题三:
构建新型加法网络。即在卷积网络中,用加法运算代替所有的乘法运算,同时与芯片计算相结合,探索高效计算的新路径。
所谓万物预视,即定义预训练任务,构建通用视觉模型。具体做法是搜集大量公开无标签的亿级数量级的图片,完成知识的抽取与整理。
该计划的目标是在虚拟场景下,不通过标注数据,直接训练智能行为本身。目前业界在这个领域的研究非常还有限。这里涉及如何定义知识、如何构筑虚拟场景、如何模拟用户的真实行为、如何确保数据与智能体的安全等问题。虽然这个计划极具挑战性,但田奇认为这才是通向真正的人工智能的道路。
![]()
![]() 点击“
阅读原文” 查看 ICLR 系列论文解读
点击“
阅读原文” 查看 ICLR 系列论文解读







 点击“
阅读原文” 查看 ICLR 系列论文解读
点击“
阅读原文” 查看 ICLR 系列论文解读




