开源分布式跟踪方案概览

作者丨Juraci Paixão Kröhling
译者丨张卫滨
入门分布式跟踪可能是一项很艰难的任务。这个领域有太多新术语、框架和工具,它们有着明显互相重叠的功能,初学者很容易迷失或偏离主题。本文对最流行的工具进行了概述和分类,能够帮助你掌握分布式跟踪领域的概况。
虽然跟踪和采样分析是密切相关的两个学科,但是分布式跟踪通常被理解将应用中不同工作单元的信息连接在一起,以便理解整个事件链的技术,这些工作单元会在不同的进程或主机中执行。在现代应用程序中,这意味着分布式跟踪可以用来描述 HTTP 请求在穿越大量微服务时的情况。
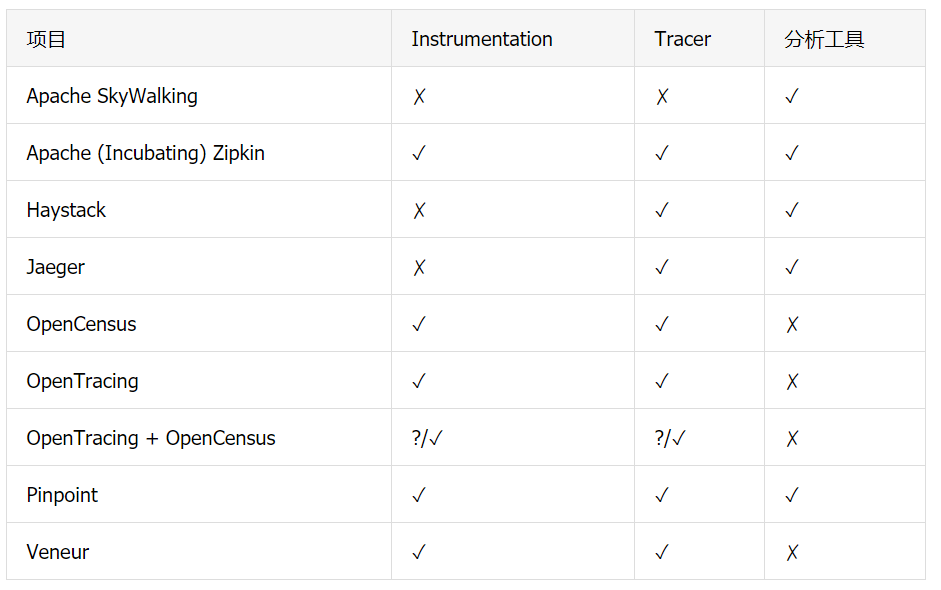
这里所列的大多数工具可以大致分为 instrumentation 库、tracer、分析工具(analysis tool,后端 +UI),以及它们的任意组合。博文“各种跟踪方式的差异”很好地描述了分布式跟踪的这三个方面。
对于本文来讲,我们将 instrumentation 定义为用来告诉记录哪些信息的库,将 tracer 定义为如何记录并提交数据的库,将分析工具定义为接收跟踪信息的后端。在现实中,这些分类是不断变化的,instrumentation 和 tracer 的区别并不会始终那么明显。类似的,分析工具这个术语可能会过于宽泛,因为有些工具会关注探索跟踪信息,而有些则是完整的可观察性平台。
本指南只列出了开源的项目,不过还有一些其他的厂商和解决方案值得关注,比如 AWS X-Ray、Datadog、Google Stackdriver、Instana、LightStep 等。

Apache SkyWalking 最初是在 2015 年作为一个理解分布式系统的培训项目而开发的。创建之后,它在中国流行起来,致力于成为一个完整的应用程序性能监控平台(Application Performance Monitoring,APM),它主要关注通过代理实现自动化的 instrumentation 并与现有的 tracer(比如 Zipkin 和 Jaeger 的 tracer)或基础设施组件进行集成(如服务网格)。Skywalk 已经被提升为 Apache 基金会的顶级项目。

Apache(Incubating) Zipkin 最初是由 Twitter 开发的并于 2012 年开源。它是最成熟的开源跟踪系统之一,并激发了几乎所有的现代分布式跟踪工具。Zipkin 是一个完整的跟踪解决方案,包括 instrumentation 库、tracer 和分析工具。数据的传播格式 B3 目前是分布式跟踪的通用语言,另外它的数据格式也得到了其他工具的原生支持,比如数据生成端的 Envoy Proxy 和消费端的其他跟踪解决方案。Zipkin 的优势之一是拥有大量高质量的框架 instrumentation 库。

Haystack 是一个具有类似 APM 能力的跟踪系统,比如异常检测(anomaly detection)和趋势可视化。它最初是 Expedia 开发的,其技术架构非常关注高可用性。Haystack 利用 OpenTracing 作为它主要的 instrumentation 库,并且像 Pitchfork 这样的附加组件可以以其他格式摄取数据。

Jaeger 最初是由 Uber 开发的,并于 2017 年开源,在此之后,该项目转移至了云原生计算基金会(Cloud Native Computing Foundation,CNCF)。我们可以在 Jaeger 最初的架构、数据模型和命名法中看到来自 Dapper 和 Zipkin 的灵感,但是它的发展已经超出了这个范围。对于 instrumentation 部分,Jaeger 利用 OpenTracing API,该 API 从一开始就是一等公民。分析工具非常轻量级,非常适合用于开发阶段和高度弹性的环境(例如多租户 Kubernetes 集群),并且它是 Istio 等工具的默认跟踪器。

OpenCensus 最初是谷歌基于其内部跟踪平台开发的,它既是一个 tracer,也是一个 instrumentation 库。它的 tracer 可以连接到“导出器”,向 Jaeger、Zipkin 和 Haystack 等开源分析工具发送数据,也可以向 Instana 和谷歌 Stackdriver 等该领域的供应商发送数据。除了 tracer 之外,OpenCensus Agent 还可以用作进程外的导出器,允许 instrumented 的应用程序完全不受数据终点的分析工具的影响。OpenCensus 的另一个方面就是跟踪,最终得到度量指标。它在框架 instrumentation 库方面还没有那么丰富,但是一旦与 OpenTracing 项目的合并完成,这一点可能会有所改观。

如果说在分布式跟踪的 instrumentation 方面有什么接近标准的东西的话,那就是 OpenTracing 。这个由 CNCF 托管的项目是由在各种场景中实现分布式跟踪系统的人员启动的,包括供应商、用户和内部实现的开发人员。在项目的一端,有许多框架 instrumentation 库,比如 JAX-RS、Spring Boot 或 JDBC。另一方面,有一些 tracer 完全支持 OpenTracing API,包括 Jaeger 和 Haystack,以及该领域的知名的供应商,如 Instana、LightStep、Datadog 和 New Relic。Zipkin 也有兼容的实现。

OpenTracing 最近宣布将与 OpenCensus 合并。虽然目前还不清楚未来的工具会是什么样子,甚至不知道它将如何命名,但这肯定是值得关注的。目前,它们已经发布了一个暂定的路线图以及一些具体的代码建议,展示了这个新工具的方向。

Pinpoint 最初是由 Naver 在 2012 年开发的,并于 2015 年开源。它包含 APM 功能,具有网络拓扑、JVM 遥测图和跟踪视图的特性。Instrumentation 只能通过代理完成,可以通过插件进行扩展。这种方法的优点是,instrumentation 不需要代码变更,但缺点是,它缺乏对显式 instrumentation 的支持。Pinpoint 适用于基于 PHP 和 JVM 的应用程序,在这个领域,它对框架和库提供了广泛的支持。

Veneur 项目是由 Stripe 发起的,它可以描述为可观察性数据的管道。它与本指南中几乎所有其他工具的不同之处在于,它对可观察性应该是什么有自己的见解:span。它附带了一组本地代理 (称为“sink”),这些代理能够接收 span,从中提取或聚合数据,并将输出发送到像 Kafka 这样的外部系统。为了更好地实现这一点,Veneur 提供了自己的数据格式 SSF 。指标可以嵌入到 span 中,也可以基于“常规”span 数据进行汇总 / 聚合。
Dapper 分布式跟踪解决方案起源于谷歌,并在 2010 年的一篇论文中进行了描述。它是这里所列的大多数工具的共同祖先,包括 Zipkin、Jaeger、Haystack、OpenTracing 和 OpenCensus。虽然 Dapper 并不是一种可以直接下载和安装的解决方案,但是该论文依然是现代分布式跟踪解决方案中所使用原语(primitive)的参考资料,并且有助于了解设计决策背后的原因。
在当前分布式跟踪生态系统中,一个很大问题就是使用不同 tracer 检测的应用程序之间的互操作性。为了解决这个问题,万维网联盟 (World Wide Web Consortium,W3C) 成立了分布式跟踪工作组(Distributed Tracing Working Group ),负责传播格式的 Trace Context 推荐方案。
本文最初发表于 RedHat 的开发者博客,经 RedHat 和原作者 Juraci Paixão Kröhling 授权由 InfoQ 中文站翻译分享。原文链接:
https://developers.redhat.com/blog/2019/05/01/a-guide-to-the-open-source-distributed-tracing-landscape/

点个在看少个 bug 👇



