深度学习的理论来源:一个炼金术师的自述
上大学的时候有那么一次,我在食堂遇到一个哥们儿。
我和他说我现在在上一门叫“理论神经科学”的课。
过了半个学期我向他请教一个拉格朗日乘数(Lagrange Multiplier)的问题,说作业里要用。
他满脸吃惊地看着我说 ,“‘理论神经科学’不是讲什么人死了以后意识到哪里去了的吗?!”
Christof Koch 口中“宇宙中最复杂的物质”——人脑——是一个复杂的物理系统。用量化的手段描述复杂系统的性质,正是理论神经科学的初衷。缺乏理论上的指引和理解,我们对到底应该做什么实验、怎么分析得到的实验数据愈发无助。在实验工具愈发精密、数据愈发全面的今天,这是一个尤为重要的难题。
有时,对理论神经科学的缺乏了解,导致一些三十年前已经充分研究过的系统被当成新问题、新结论来研究。由此我想写写如今大热的深度学习和理论神经科学间千丝万缕。
深度学习和炼金术
机器学习里有个很有名的会议叫神经信息处理系统进展大会(NIPS,全称是 Neural Information Processing Systems)。2017年的 NIPS 上,Google 的工程师 Ali Rahimi 在他获得一项大奖之后的发言中称,深度学习成为了今天的炼金术。这个说法由此而来。这个说法在业界引起了大论战,既有强烈反对这个说法,感到被侮辱的;也有支持这个说法,反思深度学习当前发展态势的。
炼金术是把一种金属变成另外一种金属的买卖。在现代化学发现不同的金属是由不同原子组成的之前,炼金术师们幻想着通过捣腾金属来实现元素之间的转变。当今上过初中物理的朋友大概就知道这不大可行,然而就连了不得的艾萨克·苹果大王·牛顿也曾沉迷于炼金术。炼金术师们缺乏现代理论的指导,通过不断摸索尝试,没能变出金子来,倒是歪打正着地推动了冶金、化学等行业的发展。

描述炼金术师的刻板画,看上去还真是……很邪乎| H. Stanley Redgrove/wikimedia commons
在有的深度学习从业者看来,深度学习是当代的炼金术。
Rahimi 的这个比喻这么说,是因为深度学习中理论的匮乏。用最宽泛的定义来说,深度学习是对已有机器学习方法的叠加;用比较容易想象的定义来说,深度学习使用类似神经网络的系统来学习。不管用哪个定义,深度学习都涉及到把学界已经不太理解的东西聚合在一起,变成了更难理解的,额,大东西。应对着这样复杂的系统,深度学习从业者没有可靠的理论作为支撑,只能东试试西试试,“歪打正着”地取得进展。
神经网络
各种不知道为什么
要想直观地体验深度学习的发展是多么歪打正着,我们可以比较一下我现在戴着的眼镜,和在机器视觉领域经典的神经网络,AlexNet。咱们来一项一项考虑它们是怎么设计出来的。
AlexNet第一层的卷积内核是11像素x11像素的。为什么是11不是10,不是12?不知道,作者写论文的时候也没讲。在 AlexNet 之后的机器视觉系统也要么是沿用了 11x11 的设计,要么同样莫名其妙地选了另一组参数。
而AlexNet为什么有9层,为什么第一层的卷积内核是11乘11的,第二层就变成5乘5,后面又变成3乘3了?作者也没说。甚至,为什么这个内核的大小越来越小也没有交代。
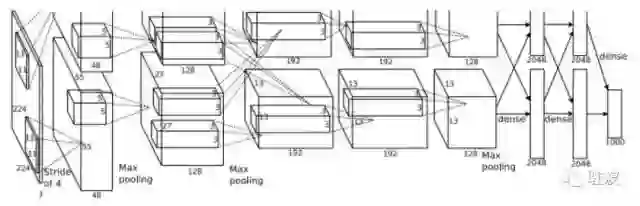
AlexNet 的结构示意图。反正就是有很多瞎选出来的数字就对了 | [1]
而眼镜的设计原因就清晰多了。眼镜上面有一层白光下面有看起来五颜六色的薄膜。这层膜利用了光波的相消干涉原理,减少眼镜片的反光;眼镜片打磨成的弧度,是根据我的近视度数,和我的眼镜片材料的折射率计算出来的曲线。
所以说,名噪一时的卷积神经网络,理论基础还不如我鼻梁上挂着的眼镜。
设计 AlexNet 的 作者Alex Krizhevsky,他的一篇论文下来能有几十个上百个完全没有解释的设计选择,连大的设计思路都没有很好的理论基础和 motivation。即便如此,只要最后搞出来的神经网络表现出众,那就够了。可能有人会觉得,什么理论不理论的,都是读书人的迂腐罢了!
然而理论还真不是读书人的迂腐,它很重要。掌握了一个问题的理论基础,我们就能提前进行预测,知道什么样的设计能成功,什么样的设计不用浪费时间尝试(否则造飞机也要靠随便设计一个试试看也太危险了吧!);一个设计成功了,我们能分析哪个细节,下次便多用这个细节;如果理论已经能证明一些目标是不可能实现的(比如,永动机),那我们也不必大开脑洞地去试图实现这个目标;通过理论,我们也能看出新的设计是否只是新瓶装旧酒,还是真的有实质性突破。
理论不够好?
因为人才被挖走了
理论大法这么好,为什么深度学习没有好的理论呢?
第一个原因是,深度学习的研究,现在很多是由工业界的科研部门在驱动,而工业界的科研当时注重应(zhuan)用(qian)的啦。
明明试试不同的神经网络的参数就能取得一些性能上的提升,给企业带来收益,干嘛要去干开发理论这种又不知道要花多少时间又不知道能不能成功的东西呢?
按道理说,工业界科研总的来说都是比较在意应用的,理论研发要靠学术界来带,这一点在什么学科都是一样的。但是深度学习在性能上的重大成功,让工业界的企业们不惜重金挖走学术界的大佬们。在工作环境、薪金等方面,科技企业能提供非常诱人的 offer,很多在大学里取得教职的教授也是很心动。不少人就抛弃了理论事业,投身工业的应用去了。
2017年的 认知计算神经科学会议 (CCN,全称Cognitive Computational Neuroscience)上,MIT的脑与认知科学系主任 James DiCarlo 提到强化学习(reinforcement learning)时打趣说,Yann LeCun 在 facebook 工作,所以肯定不缺 reinforcement 吧!又比如说,开发了 AlphaGo等系统的Deepmind,14年平均每个雇员的”staff cost“高达34.5万美元[4]。
工业界科研力量缺乏做理论研究的动力只是一个方面。另一点是,深度学习的理论很难做。对于神经网络的理论研究,远在机器学习的浪潮之前就开始了。然而直到今天,我们对于神经网络的理论还较为原始。解释力不足、难以产生可以实验认证的预测,成为神经科学理论的重要问题。
神经网络
找到了物理小伙伴
神经网络的复杂性驱使了理论学家诉诸统计物理。19世纪末开始的统计物理今天已经是较为成熟的学科。统计物理所研究的问题,确实和理论神经科学有不少相通之处:可以说,这两个学科都是研究复杂的宏观行为是如何由微观结构和性质产生的。在70年代,众多统计物理学家们转行做起了神经网络的理论,开始把神经网络的问题转换成在数学上研究较为充分的物理问题:
工作记忆(working memory)成了神经网络中能量曲面(energy landscape)上的吸引子(attractor)。原来记电话号码几个数字的能力也可以说的这么酷炫吗!
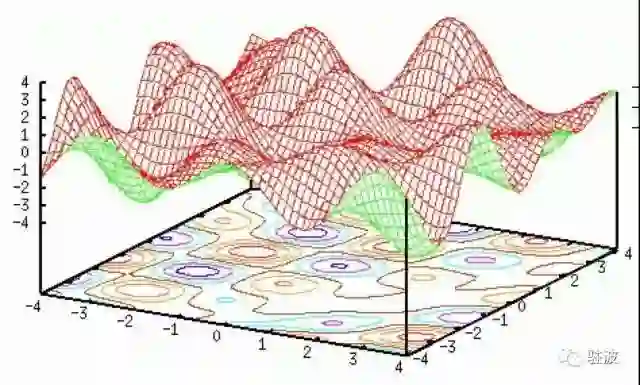
Hopfield Network 的能量曲面
而感觉系统(大概就是眼睛鼻子耳朵这种)变成了信息论中的一个 information channel。

信息学之父克劳德·香农:你们啊,就知道蹭我的热度
还有神经网络中神经元的互相作用,变成二维伊辛模型(Ising Model)里磁铁之间的吸引和排斥。
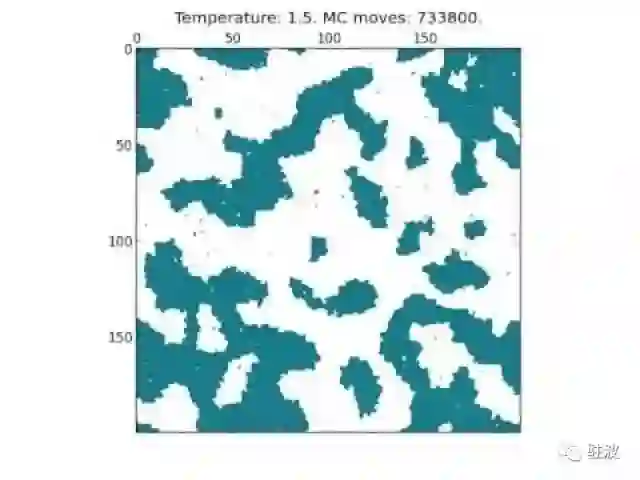
一个正方晶格二维伊辛模型(蒙特卡洛模拟)
所以感觉神经网络是个物理问题啊!这货是怎么被扯到机器学习里去的呢?
人脑是不断变化的,神经元之间连接的强度可大可小,让人获得了学习的能力。
于是心理学家们想着,那咱们也搞个会变化的神经网络模型呗。他们提出了一个叫 perceptron的简单模型,并指出这种系统虽然简陋,但是也有有存储信息的能力!这种模型,指出了像“记忆”、“学习”这样的心理学现象,是如何能由一个物理系统来实现的。
蠢蠢欲动的统计物理学家们,如爱丁堡大学的Elizabeth Gardner[7]、普林斯顿的 John Hopfield[8]等人蜂拥而上,硬是把一个直直的心理问题掰成弯弯的物理问题。其中,以Hopfield 命名的 Hopfield Network 把神经网络的变化和一个单一的标量自由能函数联系在了一起。在这个模型里,所有神经元之间的连接变化,都是在最小化系统的自由能。

警察同志,Hopfield 就是他!| Princeton.edu
这就给了机器学习的熊孩子们以思路。在 Hopfield Network 的自由能表达式中,既有神经元之间连接带来的自由能,也有”外界环境“带来的自由能。这个结构本身便是受了伊辛模型的启发,神经元连接的自由能就像是相邻原子自旋相同/相反导致的能量,外界环境的自由能就像是外界磁场带来的能量。
我们能否利用这个原理,让这个神经网络“记住”外界环境中的一些信息呢?
在 Hopfield Network 的基础上,深度学习的先驱们开发了如 Boltzmann Machine、Restricted Boltzmann Machine 等的早期机器学习用神经网络。就连 Ising Model 这种笔笔直的物理模型,也被用来给图像降噪了。
这些神经网络仍然是有扎实的理论基础的。因为他们的设计是遵循统计物理系统的原理的,每个神经元在稳态中的数值分布可以用波兹曼分布(统计物理中把稳态系统里一个状态的能量和概率相联系的等式)来描述。正因为如此,这些神经网络还是可以放在概率论的理论框架中进行阐述的:他们属于所谓的无向图模型(undirected graph model)。
神经网络
脑洞尝试真成功了
但是机器学习熊孩子们的脑洞不止于此。他们设想,我们要不干脆就放弃物理原理吧。假如我们抛弃自由能函数,定义一个我们想要在实际生活中最小化的函数(比如说,辨认手写数字的错误率),然后把这个函数当自由能函数一样做最小化,是不是也能取得不错的效果呢?这里基本的操作,就是反向传播算法(backpropagation)。我对网络中的每一个参数都求这个函数的偏导数,再按照偏导数调节这些参数,实现函数的最小化。
按照当时的统计学习的理论,这个思路有一万个出错的地方。和简单的统计模型相比,神经网络的参数要多的多(AlexNet有约10万参数),经常远远比用来训练的数据量大。按道理说,这应该导致训练“过拟合”(overfit),也就是网络学到的东西只适用于训练的数据集,不能用来推广;神经网络最小化的函数经常有无数个 local minimum,按道理说用反向传播会导致系统卡在 local minimum 不能动;大的神经网络训练和运行,需要做极多的矩阵运算,对于计算机性能要求也很高。

深度学习,进程还远着 | codeburst
然而深度学习有千千万万失败的理由,结果却很成功了。而深度学习的成功,就变成做神经网络理论研究的人面前又一大难题:和别的机器学习方法相比,深度学习到底特别在什么地方?是什么让深度学习取得这样的成功?
绕了这么一大圈,我是想说两件事。首先你看,就算是统计物理的高大上方法,仍然只能描述非常简陋的神经网络。这些方法所能透彻理解的神经网络,不要说和人脑相比,就算是和机器学习课上教学用的小学生神经网络都相差甚远。
最最基础的三维 Ising Model 物理学家研究了大半个世纪了,仍然没有找到解析解,而 Ising Model 又已经是高度抽象和简化的神经模型了。也就是说,就算是用上了统计物理的数(zhuang)学(bi)方(shen)法(qi),咱们也就能研究个智力比不上微生物的神经网络。不管是人的神经系统,还是深度学习所使用的神经网络,复杂程度都远远超出了已有方法能描述的范畴。
第二是,想做深度学习应用的人,根本不需要掌握什么理论知识。已有的理论知识,要么是描述和商用深度学习系统完全不同的系统的,要么是预言深度学习不会成功的。而真的要让一个深度学习系统跑起来,除了会编程,最麻烦的地方也就是设计一个损耗函数了。
理论对于今天很多的深度学习人来说,是一个既不懂又不想懂的东西,Hopfield 等等本应该熠熠生辉的名字,很多深度学习实践者却没有听说。据说,某业界超级大佬的指导思路就是,不用懂一个东西什么原理,管用就行了。
酷炫,但是不明白的地方多了 | wikimedia commons
这别人说你是炼金术,你还敢回嘴?
不能理解深度学习运行原理的我们,还在寻找理论框架的路上。缺少了理论基础,深度学习像一剂成分复杂、原理不明的药。在机器学习愈发普遍的未来,我们真的希望在生活的方方面面依赖一个原理不明的东西吗?
正如制药者希望能提取药剂里的有效成分,我们也希望能找到深度学习取得成功的关键并加以推广,并发现和改善深度学习隐藏的种种弊病。
本文经授权转载自公众号驻波
(Science_in_Boston)

果壳网
ID:Guokr42
为什么这样的二维码也能扫出来?
长按它,向果壳发送【二维码】
获得答案!


好歹炼金术士我看懂了,可以点赞了



