我们还缺多少基础理论,才能在高中开设深度学习课程?

AI 科技评论按:这篇文章来自资深机器学习专家、NIPS 2017 「时间检验奖」( Test of Time Award ) 获得者 Ali Rahimi。上一次 Ali 在获奖演讲中把深度学习比作炼金术引起了深度学习界的大规模的讨论,Yann LeCun 也和他掐了起来,但最终大家都认可深度学习的理论基础还不够扎实。另一方面,深度学习热度不减,不仅各个知名大学的相关硕士博士申请火爆,甚至本科和高中阶段都有学校开始考虑设置机器学习/人工智能课程,其中当然也少不了身处潮头浪尖的深度学习。
那么,Ali 就提出了下面这个问题。
你会认为深度学习技术已经成熟到了能在中学中教授这门课程吗?
我为什么会这样问呢?不久前,我收到了一位大公司的产品经理的电子邮件。由于我本人喜欢将私人邮件公布开来,所以,下面我将它贴了出来:
来自:M.
您好,Ali,
…
请问您是如何教团队中年轻的成员们测试他们对于模型参数的预感或者获得这种直觉呢?
我们团队中的工程师们经常从其他的科学家的研究结果那里直接「继承」超参数,但他们十分畏惧自己调参。
这封电子邮件让我陷入了好几天的沉思中。我久久不能想出一个有建设性的答案。
如果实在要我回答的话,我想说:他的工程师们确实应该感到害怕!
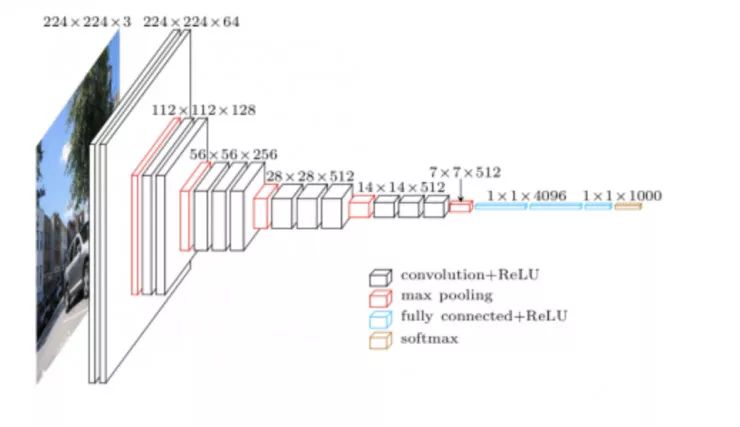
假如,你是一名工程师,面对上面这个网络,你需要让它在特定的数据集上更好地工作。你可以认为这些网络层的存在都是有其原因的。但作为一个科学领域,我们至今还没有一个通用的方式去表述这些原因。我们教授深度学习的方式与我们教授其他学科的方式差别很大。
几年前,我接触到了光学领域。在光学领域中,你也会构建一层层组件来处理输入。下面是一个相机的镜头:
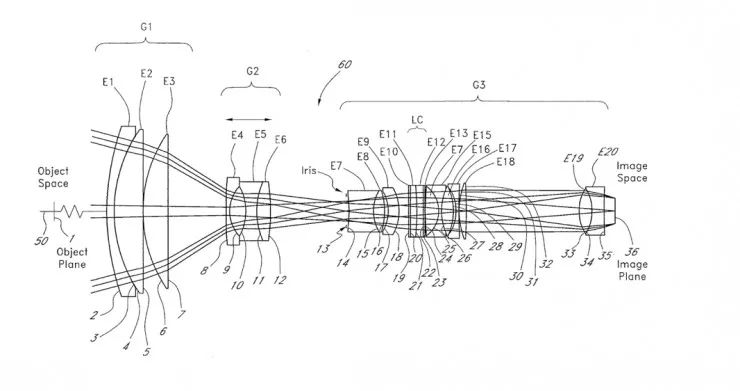
为了设计这样的东西,你将首先使用基本的光学结构,它们通常是以发明它的名人的名字命名的。你会进行仿真实验,发现它哪些地方不符合你的要求,然后插入额外的镜片来纠正缺点。
接着,你要通过一个数值化的优化器来处理整个系统,对诸如曲面的形状、位置、倾斜度等参数进行调整,使得一些设计目标最大化。然后,你会再进行仿真,修改设计,优化系统,并且一次次重复这个过程,直到系统满足需求。
这个过程和深度神经网络何其相似!
这一串结构中的 36 个镜片都是有着特定的意义才被插入其中的,它们分别负责纠正某些特定的异常情况。这就要求我们有一个非常清晰的心理模型,弄清每个镜片对透过它的光线有什么作用。这种心理模型通常是以某个功能为依据得来的,比如折射、反射、衍射、色散,或者波前校正。
人们并不畏惧这个设计过程。每年,美国都有数以百计的光学工程师毕业,从事设计镜头的工作。他们并不害怕自己的工作。
这不是因为光学是十分简单的。这是因为他们很好的组织了光学的心理模型。
现代光学的教学被抽象成了不同的层次。
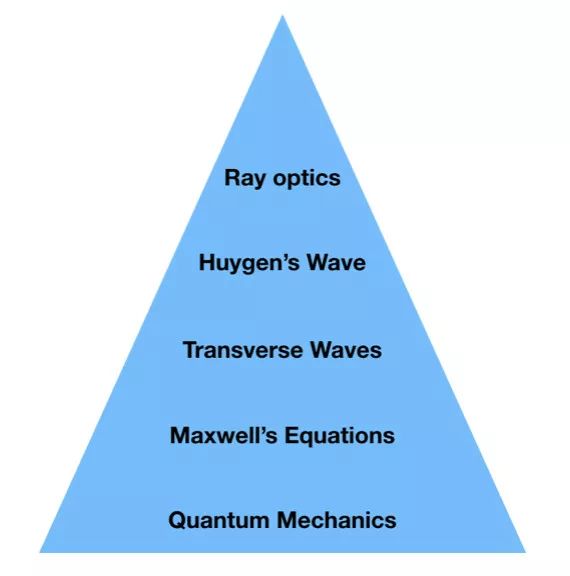
在最上面,是最简单的一层——射线光学。射线光学是波光学的一种简化,在波光学中,光线代表波前的法向量。波光学是麦克斯韦方程组的近似解。麦克斯韦方程组可以从量子物理中推导出来,而这我就不是十分了解了。
每一层都通过简化假设的方式从下面的层脱胎而来。因此,每一层都可以解释比上面的一层更加复杂的现象。

我把大部分的时间花在了设计最上面的四个抽象层上。
这就是我们今天教授光学的方法。但是这些理论并不总是像上面的网络结构这样组织起来的。直到一百年前,这其中的一些理论还以一种相互矛盾的状态共存。从业者所能依赖的仅仅是一些缺乏权威的、非正式的关于光学理论。

在牛顿形式化定义射线光学的近一百年之前,上面提到的这种状况并没有阻止伽利略制造出一个非常棒的望远镜。在伽利略的脑海里,他有一个足够优秀的关于光线的心理模型,这使得他能够制造出一个能将物体放大十倍的望远镜。但是他对于光学的认识也存在一些不足,以致于他不能够校正色差,或者获得更宽广的视场。
在这些光线的理论被统一成抽象层的堆叠之前,每一种学说都需要从对光线的基本概念开始。这样会编造出一套新的不切实际的假设。牛顿的射线光学将光线建模成能够被固体物质吸引或者排斥的雾状粒子。惠更斯将光线建模成一种通过神秘的媒介「以太」传播的纵向压力波。他像声音一样对光线建模。麦克斯韦也假设光线通过「以太」传播。你还可以在麦克斯韦方程组的系数中看到这种假设的痕迹。
是的这是一个愚蠢的模型!但是它能够被量化,有预测的能力。
尽管这些假说现在听起来可能很愚蠢,但是,这些模型是可以量化的,并且他们有预测的能力。你可以将数据填入这些系统中并且得到数值化的预测作为输出。这对于工程师来说是十分有用的!
在深度学习中我们要探索什么呢,就是要找到一种用于描述深度学习中每一层的功能的模块化语言。
如果我们能够像在光学中描述光线如何穿过一个光学器件那样描述深度神经网络中的每一层具有怎样的功能,我们设计深度神经网络的工作会更加简单。
我认为卷积层的功能是运行与他们的输入相匹配的过滤器,池化层则是紧随其后的非线性单元。这是一个较为「 底层 」的描述,类似于从麦克斯韦方程组的角度来描述镜头的功能。
也许存在我们能够依赖的更「 高层 」的抽象概念,我们可以根据数据的数值经过网络层之后被修改的量化情况来描述网络层的功能,这类似于根据镜头如何使光线弯曲来描述它的功能。
并且,如果这个抽象概念是可以被量化的那就更高了。这样一来,你可以将数字输入到一个公式中,进行粗略的分析,这会帮助你设计你的网络结构。
我们距离这样的语言还很遥远。那么,让我们从更简单的情况入手。
但是,也许我被幻想带跑偏了!
让我们从更简单的情况入手吧。我们有很多对于深度神经网络的训练如何工作的心理模型。我已经收集好了一些值得解释的现象的案例。让我们看看这些心里模型是如何很好的解释这些现象的。
在我更深入的分析之前,我承认这个小研究是十分粗糙的。光学用了长达 300 多年去做到这一点,而我只花了一个星期六的下午去做这个研究。相应地,我只将我的发现发表在了我的博客中。
现象:随机梯度下降(SGD)算法的随机初始化足够好,但是之后小的数值错误或者不恰当的步长会破坏随即梯度下降过程。
一些从业者已经注意到,梯度积聚的方式的微小变化会导致在测试集上巨大的性能差异。比如,当你使用 GPU 而不是 CPU 进行训练时(https://github.com/tensorflow/tensorflow/issues/2226,https://github.com/tensorflow/tensorflow/issues/2732),就会出现这种情况。
你认为这是一个值得解释的合理的观测结果吗?或者你认为这可能是伪造的、不真实的观测结果呢?或者也许你认为这个观测结果中有些错误,就像它在一定程度上逻辑上自相矛盾?或者它的表述是不恰当的。
我敢肯定你此时肯定百感交集。但是暂且让我们把它作为一个现象记录下来,继续进行我们的研究。
现象:浅层模型的局部最小值比尖锐的最小值的泛化能力更好
这个说法现在非常流行。一些人坚持它是正确的(https://arxiv.org/abs/1609.04836,https://arxiv.org/abs/1611.01838,https://arxiv.org/abs/1704.04289,https://arxiv.org/abs/1710.06451),包括我在内的其他人认为这个说法从逻辑上看就不正确,那些认为它正确的人反驳道:从经验上来说,这个说法的确是正确的(https://arxiv.org/abs/1703.04933)!如今,有的研究者已经对这个说法加以提炼,得出了变体的版本(https://arxiv.org/abs/1706.08947)。这个说法至今令人困惑(https://twitter.com/beenwrekt/status/941005520420225025)。
我需要指出,这个现象可能是充满争议的,但是尽管如此还是把它记录下来吧。
现象:嵌入批量正则化(BN)层会加速随机梯度下降
「 批量正则化是有效的 」这说法是几乎毫无争议的。我在此仅仅举出一个反例(http://nyus.joshuawise.com/batchnorm.pdf),并且将这个现象记录下来,不予置评。
现象:尽管存在很多局部最优点和鞍点,但随机梯度下降算法总能成功解决优化问题
对于这个问题,人们有各种各样的说法。一个经常被提到的说法是,在深度学习训练的损失函数的面上普遍存在鞍点和局部最小值(https://arxiv.org/abs/1712.04741)。此外,人们要么认为梯度下降可以克服这个问题(https://arxiv.org/abs/1412.6544),要么认为没有必要克服这个问题就可以得出一个能够被很好的泛化的解(https://arxiv.org/abs/1712.04741)。也有人认为深度学习模型的损失表面总体上来说是很好处理的(http://openaccess.thecvf.com/content_cvpr_2017/html/Haeffele_Global_Optimality_in_CVPR_2017_paper.html)。
在这里,我勉强将这个现象记录下来。
现象:Dropout 比其他的「 随机化策略 」更加有效
我不知道如何将类似于 Dropout 的算法归类,所以我在这里将他们称为「 随机化策略 」。
很抱歉,在这里我仅仅将它记录下来,不加以评论。
现象:深度神经网络能够记住随机的标签,并且能够将其泛化
这里的证据是很清楚的(https://arxiv.org/abs/1611.03530),我亲爱的朋友们发现了它们并支持这个观点。
尽管富有争议,我在这里还是将它记录下来。
我们已经发现了一些现象。从我上面引用的论文中,我也已经得到了我认为能够能够在最佳的程度上解释这些现象的学术理论。
让我们一起来看看我们的研究进展:
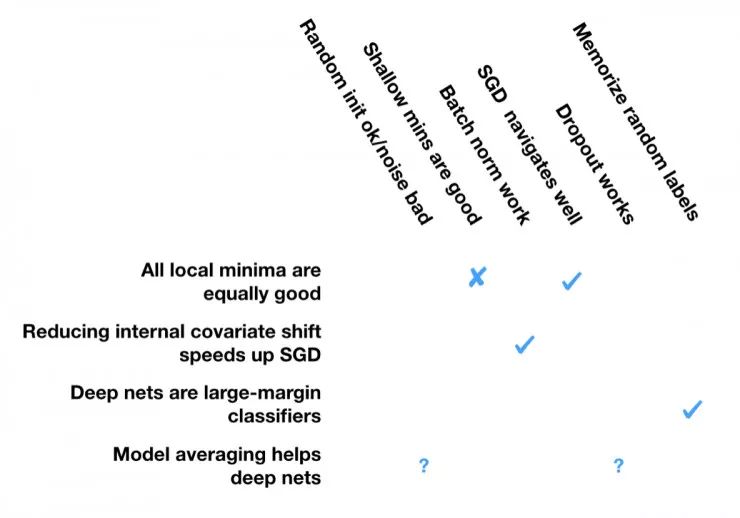
但我们仍然别高兴的太早,我们还面临着以下的问题:
首先,我并不认同我们我们在一开始想要解释的一些观测结果是合理的
第二,我不能将这些解释组织成一个层次化的抽象,不能像光学的层次化抽象那样明显的表述出来。
第三,我怀疑我从论文中引用的一些理论并不是正确的。
大量的新人涌入到了我们这个行业中,而我们通常差不多都是用一些不规范的方式培训他们,教给他们一些预训练好的深度神经网络,随后就要求他们能自己创新。对于那些需要解释的现象,我们自己都不能达成一致。想要在高中就能教这些东西,我们还离得太远了。
那么我们该怎么做呢?
如果我们能够提供由不同层次的抽象层组成的心理模型,用于描述深度学习网络中每一层的功能,那就太好了。在深度学习领域,我们与「 折射率 」、「 色散 」、「 衍射 」相对应的概念是什么呢?也许你已经思考过这些问题,但是我们没有把我们关于这些概念的语言标准化。
让我们将我们都同意的一组现象归拢。接着,我们可以试着去将它们解释清楚。什么是我们等价于牛顿环、克尔效应、法拉第效应的东西呢?
我和一小群同事开始进行了一项实证研究,试图将我们领域内的心理模型进行分类,使之形式化,然后用实验验证他们。这是一项很大的工程。我认为这是建立一个层次化的深度学习心理模型、得以在高中开设深度学习课程的第一步。
原文地址:
http://www.argmin.net/2018/01/25/optics/







