手把手教您将 libreoffice 移植到函数计算平台
云栖君导读:LibreOffice 是由文档基金会开发的自由及开放源代码的办公室套件。LibreOffice 套件包含文字处理器、电子表格、演示文稿程序、矢量图形编辑器和图表工具、数据库管理程序及创建和编辑数学公式的应用程序。借助 LibreOffice 的命令行接口可以方便地将 office 文件转换成 pdf。如下所示:

一个完整版本的 LibreOffice 大小为 2 GB,而函数计算运行时缓存目录 /tmp 空间限制为 512M,zip 程序包大小限制为 50M。好在社区已经有项目 aws-lambda-libreoffice 成功的将 libreoffice 移植到 AWS Lambda 平台,基于前人的方法和经验,本人创建了 fc-libreoffice 项目,使 libreoffice 成功的运行在阿里云函数计算平台。fc-libreoffice 在 aws-lambda-libreoffice 的基础上解决了如下问题:
重新编译和裁剪 libreoffice ,使其适配 FC nodejs8 runtime 内置的 gcc 和内核版本;
安装运行时缺失的 libssl3 依赖;
借助 OSS 运行时下载解压,以绕过 zip 程序包 50M 的限制;
制作了一个 example 项目,支持一键部署,快速体验。
本文侧重于记述整个移植过程,记录关键步骤以备忘,也为类似的转换工具移植到函数计算平台提供参考。如果您对于如何快速搭建一个廉价且可扩展的 word 转换 pdf 云服务更感兴趣,可以阅读另一篇文章《五分钟上线——函数计算 Word 转 PDF 云服务》。
https://yq.aliyun.com/articles/674284
准备工作
在开始之前建议找一个台配置较好的 Debain/Ubuntu 机器,libreoffice 编译比较消耗计算资源。并在机器上安装和配置如下工具:
docker-ce 安装方法参考官方安装文档
fun 一款函数计算的编排工具,用于快速部署函数计算应用。
MacOS 平台可以使用如下方法安装

其他平台可以通过 npm 安装

ossutil oss 的命令行工具。将其下载并放置到 $PATH 所在目录。
编译 libreoffice
我们会采用 fc-docker 提供的 aliyunfc/runtime-nodejs8:build docker 镜像进行编译。fc-docker 提供了一系列的 docker 镜像,这些 docker 镜像环境非常接近函数计算的真实环境。因为我们打算把 libreoffice 跑在 nodejs8 环境中,所以我们选用了 aliyunfc/runtime-nodejs8:build,build 标签镜像相比于其他镜像会多一些构建需要的基础包。
https://github.com/aliyun/fc-docker?
启动一个编译环境
通过如下命令可启动一个用于构建 libreoffice 的容器。

上面的命令,我们启动了一个名为 libre-builder 的容器并把当前目录挂载到容器内文件系统的 /code 目录。附加参数 --cap-add=SYS_PTRACE --security-opt seccomp=unconfined 是 cpp 程序编译需要的,否则会报出一些警告。-d 表示以后台 daemon 的方式启动。-t 表示启动 tty,配合后面的 bash 命令是为了卡主容器不退出。而 --rm 表示一旦容器停止了就自动删除容器。
安装编译工具
接下来进入容器安装编译工具

ccache 是一个编译工具,可以加速 gcc 对同一个程序的多次编译。尽管第一次编译会花费长一点的时间,有了ccache,后续的编译将变得非常非常快。
apt-get 的 build-dep 子命令会建立某个要编译软件的环境。具体行为就是把所有依赖的工具和软件包都安装上。
克隆源码

记得加上 --depth=1 参数,因为 libreoffice 项目比较大,进行全量克隆会比较费时间,对于编译来说 git 提交历史没有意义。
配置并编译

通过 --disable 参数去掉不需要的模块,以减少最终编译产物的体积。

开始编译

最终的编译结果位于 ./instdir/ 目录下。
精简尺寸
使用 strip 命令去除二进制文件中的符号信息和编译信息

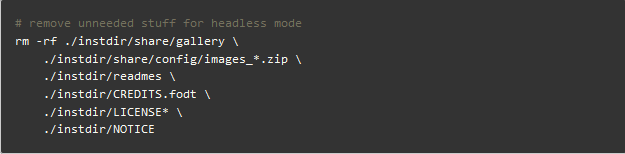
删除不必要的文件
验证
使用如下命令,测试一下编译出来的 soffice 是否能正常将 txt 文件转换成 pdf 文件。

打包

然后使用如下命令将 lo.tar.gz 文件从容器文件系统拷贝到宿主机文件系统。

Gzip vs Zopfli vs Brotli
Gzip 、Zopfli 和 Brotli 是三种开源的压缩算法,对于一个 130M 的 chromium 文件,分别采用这三种压缩算法最大 level 的压缩效果是
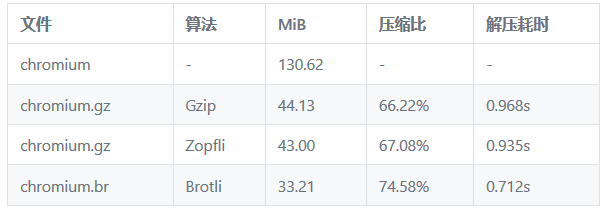
从上面的结果看 Brotli 算法的效果最优。
由于 aliyunfc/runtime-nodejs8:build 是基于 debain jessie 发行版的。在 debain jessie 上安装 brotli 较为麻烦,所以我们借助 ubuntu 容器安装 brotli 工具,将 tar.gz 格式转为 tar.br 格式。

然后当前目录会多一个 lo.tar.br 文件。
安装依赖
在函数计算 nodejs8 环境中运行 soffice ,需要安装通过 npm 安装 tar.br 的解压依赖包 @shelf/aws-lambda-brotli-unpacker 和 通过 apt-get 安装 libnss3 依赖。先启动一个 nodejs8 的容器,以保证依赖的安装环境和运行时环境是一致的。

注意:@shelf/aws-lambda-brotli-unpacker 存在 native binding,所以在开发机 MacOS 上 npm install 打包上传是无法工作。

由于函数计算运行时无法安装全局的 deb 包,所以需要将 deb 和依赖的 deb 包下载下来,再安装到当前工作目录而不是系统目录。当前工作目录下可以随代码一起打包上传。

libnss3 包含了许多 .so 动态链接库文件,linux 系统下 LD_LIBRARY_PATH 环境变量里的动态链接库才能被找到,而函数计算将代码目录/code 下的 lib 目录默认添加到了 LD_LIBRARY_PATH 中。所以我们写个脚本,把所有安装的 .so 文件软连接到 /code/lib 目录下

下载并解压 tar.br
为了使用 这个 lo.tar.br 文件,需要先上传到 OSS

在函数的 initializer 方法中下载。
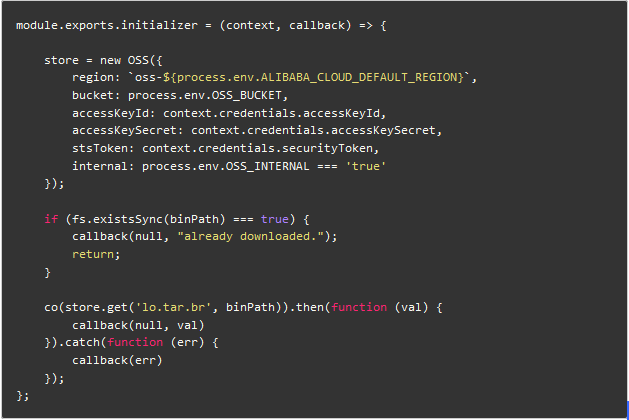
然后借助于 @shelf/aws-lambda-brotli-unpacker npm 包解压 lo.tar.br
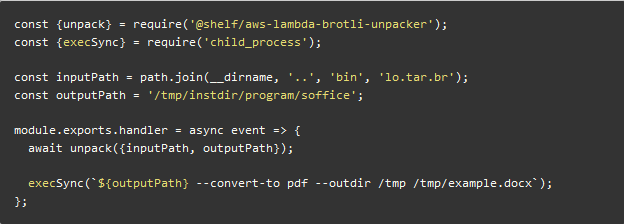
fun 部署函数
编写一个 template.yml 文件,将函数计算的配置都写在该文件中,然后使用 fun deploy 命令部署函数。
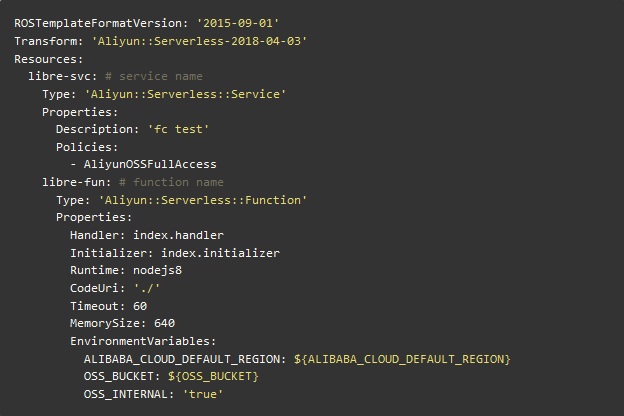
真实场景下,把秘钥和一起变量写在 template.yml 里并不合适。为了做到代码和配置相分离,上面使用了变量占位符 ${ALIBABA_CLOUD_DEFAULT_REGION} 和 ${OSS_BUCKET} 。
然后使用 envsubst 进行替换
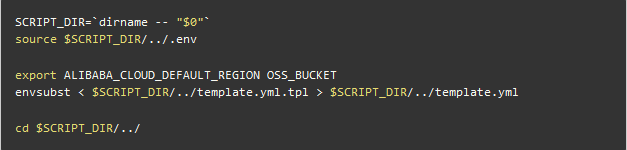
上面所有的配置都写在了 .env 文件中,dotenv 是社区常见的方案,也有广泛的工具支持。
小结
本文重点介绍了编译 libreoffice 的过程,这也是移植中较为困难的部分。由于 libreoffice 又涉及到 npm 的 native binding 和 apt-get 安装到本地目录的问题,所以在函数计算依赖方面本例也是非常经典的场景。无论是编译还是依赖安装,本文中的步骤都强烈地依赖 fc-docker 镜像,正因为有了该镜像,解决了环境差异问题,大大降低了移植的难度。大文件运行时加载也是函数计算的常见问题,对于转换工具场景中常见的大文件是二进制程序,对于机器学习场景中大文件常是训练模型的数据问题,但是无论是哪一种,采用 OSS 下载解压的方法都是通用的,随着函数计算支持了 NAS,使用 NAS 挂载共享网盘的方式也是一种新的路径。
上文完整的源码可以在 fc-libreoffice 项目中找到。
https://github.com/awesome-fc/fc-libreoffice
参考阅读
https://zh.wikipedia.org/wiki/LibreOffice
How to Run LibreOffice in AWS Lambda for Dirty-Cheap PDFs at Scale
https://hackernoon.com/how-to-run-libreoffice-in-aws-lambda-for-dirty-cheap-pdfs-at-scale-b2c6b3d069b4
https://github.com/alixaxel/chrome-aws-lambda
https://github.com/shelfio/aws-lambda-brotli-unpacker

end
更多精彩