每秒千万级实时数据处理系统是如何设计的?
闲鱼目前实际生产部署环境越来越复杂,横向依赖各种服务盘根错节,纵向依赖的运行环境也越来越复杂。

图片来自 Pexels
当服务出现问题的时候,能否及时在海量的数据中定位到问题根因,成为考验闲鱼服务能力的一个严峻挑战。
线上出现问题时常常需要十多分钟,甚至更长时间才能找到问题原因,因此一个能够快速进行自动诊断的系统需求就应运而生,而快速诊断的基础是一个高性能的实时数据处理系统。
这个实时数据处理系统需要具备如下的能力:
数据实时采集、实时分析、复杂计算、分析结果持久化。
可以处理多种多样的数据。包含应用日志、主机性能监控指标、调用链路图。
高可靠性。系统不出问题且数据不能丢。
高性能,低延时。数据处理的延时不超过 3 秒,支持每秒千万级的数据处理。
输入输出定义
输入
输出
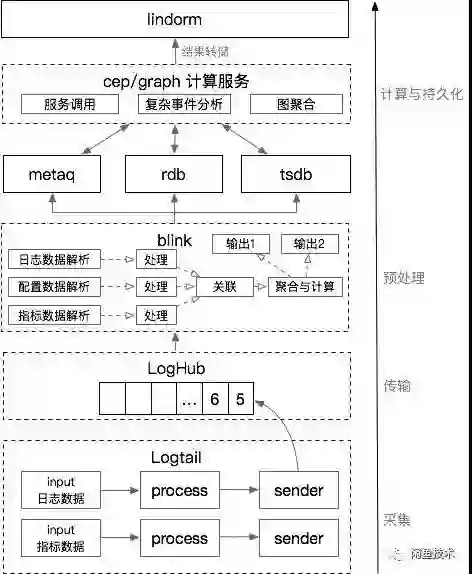
架构设计
每条产生的数据都有一个自己的时间戳。而实时传输这些带有时间戳的数据就像水在不同的管道中流动一样。

如果把源源不断的实时数据比作流水,那数据处理过程和自来水生产的过程也是类似的:
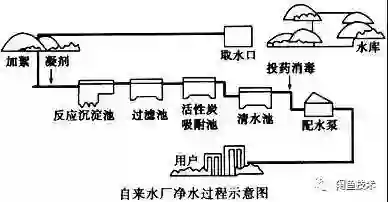
采集
传输
详细对比文章参考:
https://yq.aliyun.com/articles/35979?spm=5176.10695662.1996646101.searchclickresult.6f2c7fbe6g3xgP
预处理
Jstorm 由于没有中间计算状态的,其计算过程中需要的中间结果必然依赖于外部存储,这样会导致频繁的 IO 影响其性能。
Spark Stream 本质上是用微小的批处理来模拟实时计算,实际上还是有一定延时。
Flink 由于其出色的状态管理机制保证其计算的性能以及实时性,同时提供了完备 SQL 表达,使得流计算更容易。
计算与持久化
详细设计与性能优化
采集
日志和指标数据采集使用 Logtail,整个数据采集过程如图:
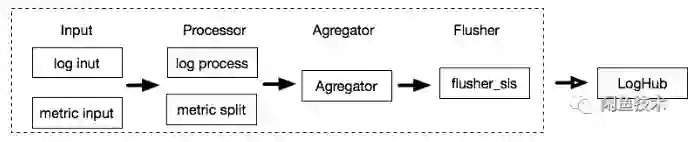
Inputs:输入插件,获取数据。
Processors:处理插件,对得到的数据进行处理。
Aggregators:聚合插件,对数据进行聚合。
Flushers:输出插件,将数据输出到指定 Sink。
传输
预处理
服务的请求入口日志作为一个单独的流来处理,筛选出请求出错的数据。
其他中间链路的调用日志作为另一个独立的流来处理,通过和上面的流 Join On Traceid 实现出错服务依赖的请求数据筛选。
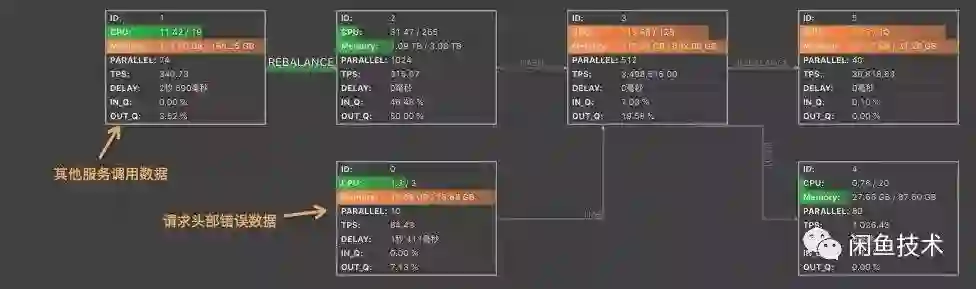
而如果 State 的生命周期太长会导致数据膨胀影响性能,如果 State 的生命周期太短就会无法正常关联出部分延迟到来的数据,所以需要合理的配置 State 生存周期,对于该应用允许最大数据延迟为 1 分钟。
使用niagara作为statebackend,以及设定state数据生命周期,单位毫秒
state.backend.type=niagara
state.backend.niagara.ttl.ms=60000
MicroBatch 和 MiniBatch 都是微批处理,只是微批的触发机制上略有不同。原理上都是缓存一定的数据后再触发处理,以减少对 State 的访问从而显著提升吞吐,以及减少输出数据量。
开启join
blink.miniBatch.join.enabled=true
使用 microbatch 时需要保留以下两个 minibatch 配置
blink.miniBatch.allowLatencyMs=5000
防止OOM,每个批次最多缓存多少条数据
blink.miniBatch.size=20000
相比于静态的 Rebalance 策略,在下游各任务计算能力不均衡时,可以使各任务相对负载更加均衡,从而提高整个作业的性能。
开启动态负载
task.dynamic.rebalance.enabled=true
其吞吐量和 RDB 这种内存数据库相比还是较大差距(大概差一个数量级)。
在接受端还需要根据 traceid 做数据关联。
图聚合计算
诊断结果简化为如下形式:
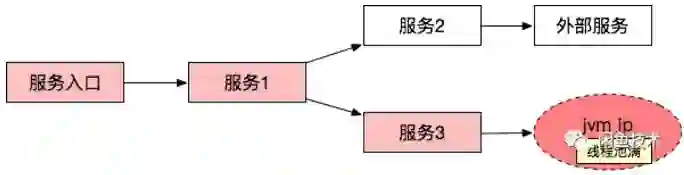
首先利用 Redis 的 Zrank 能力为根据服务名或 IP 信息为每个节点分配一个全局唯一排序序号。
为图中的每个节点生成对应图节点编码,编码格式。
对于头节点:头节点序号|归整时间戳|节点编码。
对于普通节点:|归整时间戳|节点编码。
由于每个节点在一个时间周期内都有唯一的 Key,因此可以将节点编码作为 Key 利用 Redis 为每个节点做计数。同时消除了并发读写的问题。
利用 Redis 中的 Set 集合可以很方便的叠加图的边。
记录根节点,即可通过遍历还原聚合后的图结构。
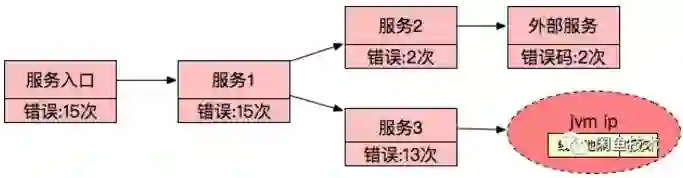
收益
展望
能够自动的减少或者压缩处理的数据。
复杂的模型分析计算也可以在 Blink 中完成,减少 IO,提升性能。
支持多租户的数据隔离。
作者:靖杨
编辑:陶家龙、孙淑娟
出处:转载自微信公众号:闲鱼技术(XYtech_Alibaba)

精彩文章推荐: