近20年最权威的目标检测总结(第四期)文中有下载包链接
点击蓝字关注我们

扫码关注我们
公众号 : 计算机视觉战队
扫码回复:目标检测,获取源码及论文链接

Technical Evolution of Bounding Box Regression
边界框(BB)回归是一种重要的目标检测技术。它的目的是在初始建议(initial proposal)或锚框的基础上细化预测边界框的位置。在过去的20年里 BB 回归经历了三个历史时期:“ (1)没有BB回归(2008年以前) ”,“(2)从BB到BB(2008-) ” 以及 “(3)从feature到BB(2013年后) ”。图7为边界框回归的演化过程。
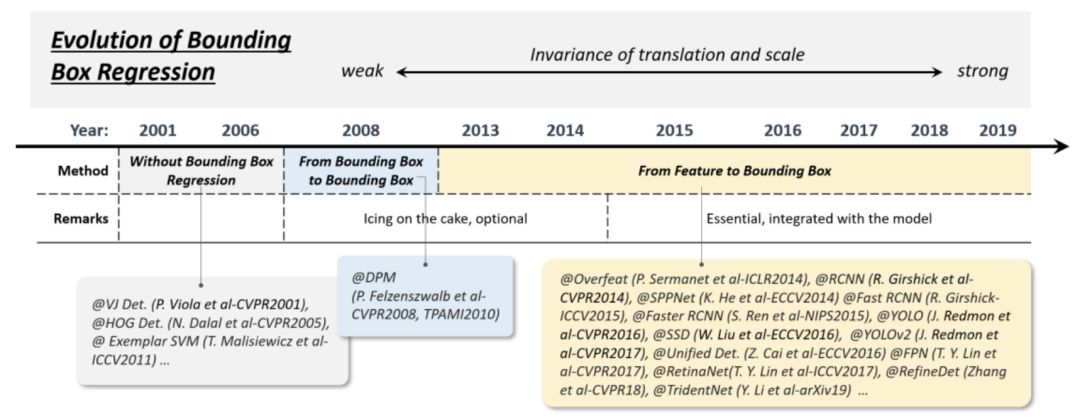
(1)Without BB regression (before 2008)
早期的检测方法,如 VJ 检测器和 HOG 检测器,大多不使用 BB 回归,通常直接将滑动窗口作为检测结果。为了获得精确的目标位置,研究人员别无选择,只能建造非常密集的金字塔,并在每个位置上密集地滑动探测器。
(2)From BB to BB (2008-2013)
第一次将BB回归引入目标检测系统是在DPM中。那时的BB回归通常作为一个后处理块,因此它是可选的。由于PASCAL VOC的目标是预测每个对象的单个边界框,因此DPM生成最终检测的最简单方法应该是直接使用其根过滤器位置。后来,R. Girshick 等人提出了一种更复杂的方法来预测一个基于对象假设完整配置的边界框,并将这个过程表示为一个线性最小二乘回归问题。该方法对PASCAL标准下的检测有明显的改进。
(3)From features to BB (after 2013)
2015年引入 Faster RCNN 后,BB回归不再作为单独的后处理块,而是与检测器集成,以端到端的方式进行训练。同时BB回归已经演化为直接基于CNN特征预测BB。为了得到更强的鲁棒性预测,通常使用smooth-L1函数或平方根函数作为回归损失,它们对异常值的鲁棒性比 DPM 中使用的最小二乘损失更强。一些研究人员还选择将坐标标准化,以获得更稳健的结果。
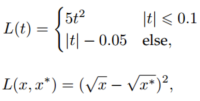
Technical Evolution of Context Priming
视觉对象通常嵌入到与周围环境一起的典型上下文中。我们的大脑利用物体和环境之间的联系来促进视觉感知和认知。长期以来,上下文启动(Context priming)一直被用来改进检测。在其进化过程中,常用的方法有三种:1) 局部上下文检测,2) 全局上下文检测,3) 上下文交互,如下图所示:
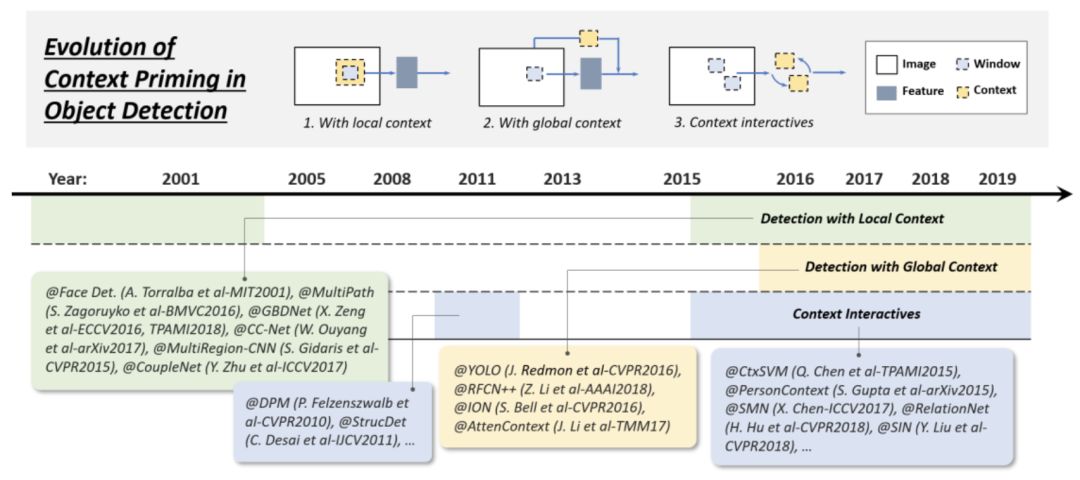
(1)Detection with local context
局部上下文是指要检测的对象周围区域的视觉信息。长期以来,人们一直认为局部上下文有助于改进对象检测。在21世纪初,Sinha和Torralba发现,包含面部边界轮廓等局部上下文区域可以显著提高人脸检测性能。Dalal和Triggs还发现,加入少量的背景信息可以提高行人检测的准确性。最近的基于深度学习的检测器也可以通过简单地扩大网络的接受域或对象建议的大小来根据局部上下文进行改进。
(2)Detection with global context
全局上下文利用场景配置作为对象检测的额外信息源。对于早期的对象检测器,集成全局上下文的一种常见方法是集成组成场景的元素的统计摘要,如Gist。对于现代的基于深度学习的检测器,有两种方法来集成全局上下文。第一种方法是利用大的接受域 ( 甚至大于输入图像 )或CNN feature的全局池化操作。第二种方法是将全局上下文看作一种序列信息,并使用递归神经网络学习它。
(3)Context interactive
上下文交互是指通过视觉元素的交互 ( 如约束和依赖关系 ) 来传达的信息。对于大多数对象检测器,是在不利用对象实例之间的关系的情况下分别检测和识别对象实例。最近的一些研究表明,考虑上下文的交互作用可以改进现代的目标检测器。最近的一些改进可以分为两类,第一类是探索单个对象之间的关系,第二类是探索建模对象和场景之间的依赖关系。
Technical Evolution of Non-Maximum Suppression
非最大抑制(NMS)是一组重要的目标检测技术。由于相邻窗口的检测分数往往相近,因此本文采用非最大抑制作为后处理步骤,去除重复的边界框,得到最终的检测结果。在目标检测的早期,NMS并不总是被整合。这是因为当时目标检测系统的期望输出并不完全清楚。在过去的20年里,NMS逐渐发展成以下三组方法:1) 贪心选择,2) 边界框聚合,3) 学习NMS,如下图所示:
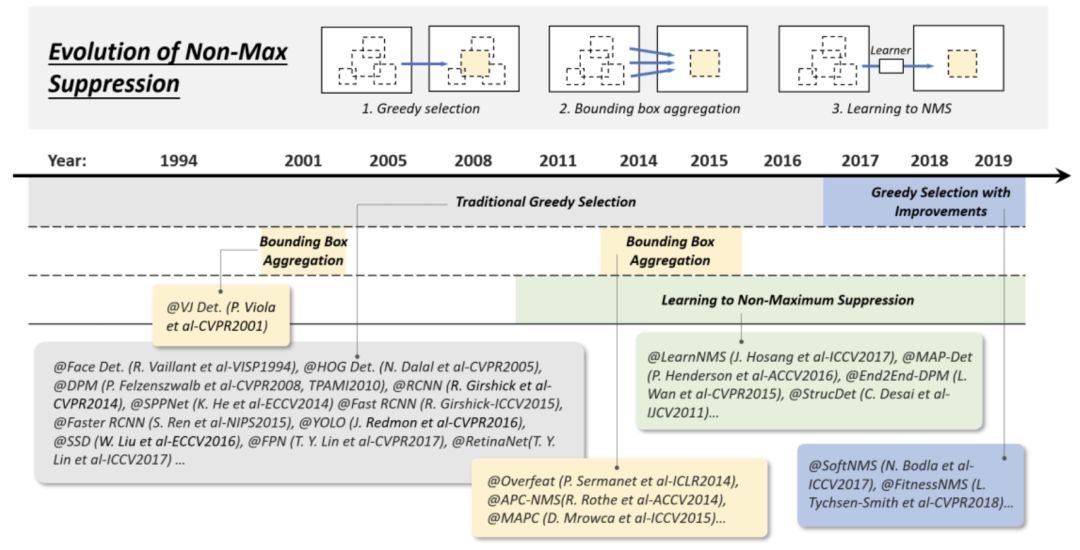
(1)Greedy selection
贪心选择是一种老式但最流行的目标检测方法。该过程背后的思想简单直观:对于一组重叠检测,选择检测分值最大的边界框,并根据预定义的重叠阈值 ( 如0.5 ) 删除相邻框。上述处理以贪婪的方式迭代执行。
虽然贪心选择已成为 NMS 的实际方法,但仍有一定的改进空间,如下图所示。
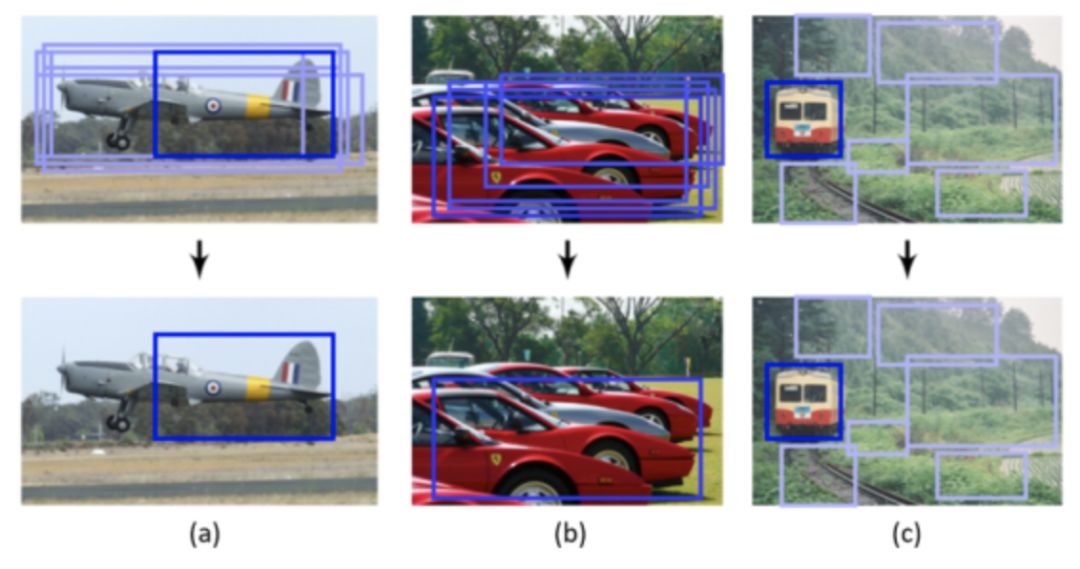
首先,得分最高的框可能不是最合适的。其次,它可能会抑制附近的物体。最后,它不抑制假阳性。近年来,尽管最近进行了一些手工修改以改进其性能,据我们所知,贪心选择仍然是当今目标检测的最强基线。
(2)BB aggregation
BB聚合是另一组用于NMS的技术,将多个重叠的边界框组合或聚类成一个最终检测。这种方法的优点是充分考虑了对象关系及其空间布局。有一些著名的检测器使用这种方法,如VJ检测器和Overfeat。
(3)Learning to NMS
最近一组受到广泛关注的NMS改进是学习NMS。这类方法的主要思想是将NMS看作一个过滤器,对所有原始检测进行重新评分,并以端到端方式将NMS训练为网络的一部分。与传统的手工NMS方法相比,这些方法在改善遮挡和密集目标检测方面取得了良好的效果。
Technical Evolution of Hard Negative Mining
目标检测器的训练本质上是一个不平衡的数据学习问题。在基于滑动窗口的检测器的情况下,每个对象的背景和对象之间的不平衡可能达到极端的10^4~10^5个背景窗口。现代检测数据集要求预测对象的长径比,进一步将不平衡比提高到10^6~10^7。在这种情况下,使用所有的背景数据进行训练是有害的,因为大量易产生的负样本将压倒学习过程。困难负样本挖掘 ( HNM ) 是针对训练过程中数据不平衡的问题。HNM 在目标检测中的技术演进如下图所示:

(1)Bootstrap
目标检测中的Bootstrap是指一组训练技术,训练从一小部分背景样本开始,然后在训练过程中迭代地添加新的误分类背景。在早期的对象检测器中,最初引入bootstrap的目的是减少对数百万个背景样本的训练计算。后来成为DPM和HOG检测器中解决数据不平衡问题的标准训练技术。
(2)HNM in deep learning based detectors
在深度学习时代后期,由于计算能力的提高,在2014-2016年的目标检测中,bootstrap很快被丢弃。为了缓解训练期间的数据目标平衡问题,像Faster RCNN和YOLO这样的检测器只是在正窗和负窗之间平衡权重。然而,研究人员后来发现,权重平衡不能完全解决不平衡的数据问题。为此,2016年以后,bootstrap被重新引入到基于深度学习的检测器中。例如,在SSD和OHEM中,只有很小一部分样本的梯度 ( 损失值最大的 ) 将反向传播。在RefineDet中,设计了一个 “ 锚框细化模块(anchor refinement module) ” 来过滤容易出现的负样本。另一种改进是设计新的损失函数,通过重新定义标准的交叉熵损失,使其更关注于困难的、分类错误的样本。
Zhengxia Zou等人的无私贡献,本系列综述引用于《Object Detection in 20 Years: A Survey》!
通知
计算机视觉战队正在组建深度学习技术群,欢迎大家私信申请加入!
扫码关注我们
公众号 : 计算机视觉战队
扫码回复:目标检测,获取源码及论文链接


